

Let's learn about Data via these 500 free blog posts. They are ordered by HackerNoon reader engagement data. Visit the Learn Repo or LearnRepo.com to find the most read blog posts about any technology.
Data is the king, queen, oil, sun, and the moon.
1. 14 Best Tableau Datasets for Practicing Data Visualization
 This article focuses on the 14 Best Tableau Datasets for Practicing Data Visualization, which is essential for business analysts and data scientists.
This article focuses on the 14 Best Tableau Datasets for Practicing Data Visualization, which is essential for business analysts and data scientists.
2. Android Devices in Enterprise Mobility — Navigating Key Risks
 Mobile phones have always been a staple of corporate communication. In the early days, companies would provide mobile devices to their employees.
Mobile phones have always been a staple of corporate communication. In the early days, companies would provide mobile devices to their employees.
3. Ruby: How to read/write JSON File
 In Ruby read and write JSON file to hash can be achieved using File Handling.
In Ruby read and write JSON file to hash can be achieved using File Handling.
4. How to read and write JSON files in Python
 We will discuss how to use Python to read, write, and manipulate JSON files.
We will discuss how to use Python to read, write, and manipulate JSON files.
5. How to Convert Base64 Data to Files on Linux and Mac OS
 This tutorial teaches you how to decode Base64 data into a File in Linux or Mac operating systems using commands and online tool.
This tutorial teaches you how to decode Base64 data into a File in Linux or Mac operating systems using commands and online tool.
6. Setting up Kafka on Docker for Local Development
 In a world where data is king, Kafka is a valuable tool for developers and data engineers to learn.
In a world where data is king, Kafka is a valuable tool for developers and data engineers to learn.
7. 10 Data Table Libraries for JavaScript
 Tables are a useful tool for visualizing, organizing and processing data in JavaScript. To start using them, you need to download a free library or one for a reasonable price. Here is a list of 10 useful, functional, and reliable JS libraries that will help you work with tables.
Tables are a useful tool for visualizing, organizing and processing data in JavaScript. To start using them, you need to download a free library or one for a reasonable price. Here is a list of 10 useful, functional, and reliable JS libraries that will help you work with tables.
8. Pyth and Auros are Bringing Real-Time High-Frequency Data to Blockchain Protocols
 Auros, a company specialising in algorithmic trading and market making, and Pyth Network will provide access to high-frequency data in real-time.
Auros, a company specialising in algorithmic trading and market making, and Pyth Network will provide access to high-frequency data in real-time.
9. How to Build a Web Scraper With Python [Step-by-Step Guide]
 On my self-taught programming journey, my interests lie within machine learning (ML) and artificial intelligence (AI), and the language I’ve chosen to master is Python.
On my self-taught programming journey, my interests lie within machine learning (ML) and artificial intelligence (AI), and the language I’ve chosen to master is Python.
10. The Algorithm for Inserting Sequences into Sequences
 Insert ordered sequences with a string-based algorithm that avoids recalculations, perfect for large datasets in product lists, chats, or task management.
Insert ordered sequences with a string-based algorithm that avoids recalculations, perfect for large datasets in product lists, chats, or task management.
11. How To Scrape Google With Python
 Ever since Google Web Search API deprecation in 2011, I've been searching for an alternative. I need a way to get links from Google search into my Python script. So I made my own, and here is a quick guide on scraping Google searches with requests and Beautiful Soup.
Ever since Google Web Search API deprecation in 2011, I've been searching for an alternative. I need a way to get links from Google search into my Python script. So I made my own, and here is a quick guide on scraping Google searches with requests and Beautiful Soup.
12. The Difference Between JDBC, JPA, Hibernate, and Spring Data JPA
 Connecting a database to a Java application is not an easy process. You need to consider the connection pool, the data access layer, etc.
Connecting a database to a Java application is not an easy process. You need to consider the connection pool, the data access layer, etc.
13. A Beginner's Guide to Data Structures and Algorithms
 Data structures and algorithms allows you to write better code, solve complex problems, and understand the inner workings of computer programs.
Data structures and algorithms allows you to write better code, solve complex problems, and understand the inner workings of computer programs.
14. Mastering the Craft of Transforming Data into Engaging Visual Narratives in User Interfaces
 As data volumes grow, mastering the art of translating data into captivating visual narratives becomes even more important.
As data volumes grow, mastering the art of translating data into captivating visual narratives becomes even more important.
15. An Intro to Resiliency, DHT, and Autonomous Economic Agents
 According to the paper published by Lokman Rahmani et al., the S/Kademlia distributed hash table (DHT) used by the ACN is resilient against malicious attacks.
According to the paper published by Lokman Rahmani et al., the S/Kademlia distributed hash table (DHT) used by the ACN is resilient against malicious attacks.
16. How Cassandra Stores Data: An Exploration of Log Structured Merge Trees
 LSM trees, memtables and SSTables working to provide database storage
LSM trees, memtables and SSTables working to provide database storage
17. Setting up Continuous PostgreSQL Backups
 This manual describes the process of setting up continuous backups for PostgreSQL databases to safeguard your data from accidental loss in an efficient way.
This manual describes the process of setting up continuous backups for PostgreSQL databases to safeguard your data from accidental loss in an efficient way.
18. How to Transform Your Data Into a Voice AI Knowledge Assistant
 RAIN executives give a full breakdown of the build out and power of AI Voice Assistants.
RAIN executives give a full breakdown of the build out and power of AI Voice Assistants.
19. NLP Datasets from HuggingFace: How to Access and Train Them
 The Datasets library from hugging Face provides a very efficient way to load and process NLP datasets from raw files or in-memory data. These NLP datasets have been shared by different research and practitioner communities across the world.
The Datasets library from hugging Face provides a very efficient way to load and process NLP datasets from raw files or in-memory data. These NLP datasets have been shared by different research and practitioner communities across the world.
20. How to get data from API in Excel
 How to get data from API JSON in Excel table with the simplest tutorial with formula. Ready to go open-sourced VBA formula with intuitive video tutorial
How to get data from API JSON in Excel table with the simplest tutorial with formula. Ready to go open-sourced VBA formula with intuitive video tutorial
21. How the TypeScript Pick Type works
 The Pick utility Type lets us take types based off existing ones, by selecting specific elements from them. Let's look at how it works and when to use it.
The Pick utility Type lets us take types based off existing ones, by selecting specific elements from them. Let's look at how it works and when to use it.
22. 11 Best Climate Change Datasets for Data Science Projects
 Data is a central piece of the climate change debate. With the climate change datasets on this list, many data scientists have created visualizations and models to measure and track the change in surface temperatures, sea ice levels, and more. Many of these datasets have been made public to allow people to contribute and add valuable insight into the way the climate is changing and its causes.
Data is a central piece of the climate change debate. With the climate change datasets on this list, many data scientists have created visualizations and models to measure and track the change in surface temperatures, sea ice levels, and more. Many of these datasets have been made public to allow people to contribute and add valuable insight into the way the climate is changing and its causes.
23. Top 10 Open Datasets for Linear Regression
 On Hacker Noon, I will be sharing some of my best-performing machine learning articles. This listicle on datasets built for regression or linear regression tasks has been upvoted many times on Reddit and reshared dozens of times on various social media platforms. I hope Hacker Noon data scientists find it useful as well!
On Hacker Noon, I will be sharing some of my best-performing machine learning articles. This listicle on datasets built for regression or linear regression tasks has been upvoted many times on Reddit and reshared dozens of times on various social media platforms. I hope Hacker Noon data scientists find it useful as well!
24. Scraping Information From LinkedIn Into CSV using Python
 In this post, we are going to scrape data from Linkedin using Python and a Web Scraping Tool. We are going to extract Company Name, Website, Industry, Company Size, Number of employees, Headquarters Address, and Specialties.
In this post, we are going to scrape data from Linkedin using Python and a Web Scraping Tool. We are going to extract Company Name, Website, Industry, Company Size, Number of employees, Headquarters Address, and Specialties.
25. Why Are Removed Posts Still Visible on Reddit?
 Even if moderators delete a post that is breaking the rules of Reddit, it is still very easy to find.
Even if moderators delete a post that is breaking the rules of Reddit, it is still very easy to find.
26. 12 Best Pre-Installed R Datasets Commonly Used for Statistical Analysis
 R programming is mostly used in statistical analysis and ML.
This article looks at the Best Pre-Installed R Datasets Commonly Used for Statistical Analysis.
R programming is mostly used in statistical analysis and ML.
This article looks at the Best Pre-Installed R Datasets Commonly Used for Statistical Analysis.
27. Grafana Loki: Architecture Summary and Running in Kubernetes
 Grafana Loki logging system architecture and components, its setup in Kubernetes from the Helm chart with AWS S3 as Single Store and boltdb-shipper for indexes.
Grafana Loki logging system architecture and components, its setup in Kubernetes from the Helm chart with AWS S3 as Single Store and boltdb-shipper for indexes.
28. How to Create Dummy Data in Python
 Dummy data is randomly generated data that can be substituted for live data. Whether you are a Developer, Software Engineer, or Data Scientist, sometimes you need dummy data to test what you have built, it can be a web app, mobile app, or machine learning model.
Dummy data is randomly generated data that can be substituted for live data. Whether you are a Developer, Software Engineer, or Data Scientist, sometimes you need dummy data to test what you have built, it can be a web app, mobile app, or machine learning model.
29. Scraping Glassdoor Job Data
 Glassdoor is one of the biggest job markets in the world but can be hard to scrape. In this article, we'll legally extract job data with Python & Beautiful Soup
Glassdoor is one of the biggest job markets in the world but can be hard to scrape. In this article, we'll legally extract job data with Python & Beautiful Soup
30. Measuring Information Retrieval Quality: Overview and Technical Metrics
 In this article, we'll look at the key metrics for measuring information retrieval quality
In this article, we'll look at the key metrics for measuring information retrieval quality
31. 10 Best Stock Market Datasets for Machine Learning
 For those looking to build predictive models, this article will introduce 10 stock market and cryptocurrency datasets for machine learning.
For those looking to build predictive models, this article will introduce 10 stock market and cryptocurrency datasets for machine learning.
32. How to Create a Responsive Table with HTMX and Django
 A guide on how to create a responsive table inside your web applications using both Django and htmx to create such a system to process your website's data.
A guide on how to create a responsive table inside your web applications using both Django and htmx to create such a system to process your website's data.
33. 5 Best Website Categorization Tools
 Website categorization refers to the process of classifying websites that users come into contact with into various categories.
Website categorization refers to the process of classifying websites that users come into contact with into various categories.
34. My Experience using GitHub Copilot for SQL Development
 In this article, I will share my experience using GitHub Copilot for SQL and explore how it impacted my coding efficiency.
In this article, I will share my experience using GitHub Copilot for SQL and explore how it impacted my coding efficiency.
35. What installing the Messenger app tells us about Facebook

36. A Guide to Web Scraping With JavaScript and Node.js
 With the massive increase in the volume of data on the Internet, this technique is becoming increasingly beneficial in retrieving information from websites and applying them for various use cases. Typically, web data extraction involves making a request to the given web page, accessing its HTML code, and parsing that code to harvest some information. Since JavaScript is excellent at manipulating the DOM (Document Object Model) inside a web browser, creating data extraction scripts in Node.js can be extremely versatile. Hence, this tutorial focuses on javascript web scraping.
With the massive increase in the volume of data on the Internet, this technique is becoming increasingly beneficial in retrieving information from websites and applying them for various use cases. Typically, web data extraction involves making a request to the given web page, accessing its HTML code, and parsing that code to harvest some information. Since JavaScript is excellent at manipulating the DOM (Document Object Model) inside a web browser, creating data extraction scripts in Node.js can be extremely versatile. Hence, this tutorial focuses on javascript web scraping.
37. A Better Guide to Build Apache Superset From source
 In this article, we’ll be deep-diving on how to build Apache Superset from the source. The official documentation is too complicated for a new contributor and thus my attempt to simplify it.
In this article, we’ll be deep-diving on how to build Apache Superset from the source. The official documentation is too complicated for a new contributor and thus my attempt to simplify it.
38. How to Query Deeply Nested JSON Data in PSQL
 Recently I had to write a script, which should’ve changed some JSON data structure in a PSQL database. Here are some tricks I learned along the way.
Recently I had to write a script, which should’ve changed some JSON data structure in a PSQL database. Here are some tricks I learned along the way.
39. 3 Types of Anomalies in Anomaly Detection
 An Introduction to Anomaly Detection and Its Importance in Machine Learning
An Introduction to Anomaly Detection and Its Importance in Machine Learning
40. Don’t OFFSET Your SQL Query’s Performance
 To implement pagination without unexpected performance issues on large sets of data, use "WHERE id > N" instead of "OFFSET N”.
To implement pagination without unexpected performance issues on large sets of data, use "WHERE id > N" instead of "OFFSET N”.
41. Object-Oriented Databases And Their Advantages
 Object oriented database is a type of database system that deals with modeling and creation of data as objects. The main advantage of this database is the cons
Object oriented database is a type of database system that deals with modeling and creation of data as objects. The main advantage of this database is the cons
42. 5 Web3 Startups That Deserve Your Attention
 I've worked with Blockchain & Web3 startups consistently since 2017. I've seen teams come and go, businesses flourish only to fail, and bull and bear markets prop up, or kill great ideas respectively.
I've worked with Blockchain & Web3 startups consistently since 2017. I've seen teams come and go, businesses flourish only to fail, and bull and bear markets prop up, or kill great ideas respectively.
43. Top 7 JavaScript Pivot Widgets in 2022
 Pivot Charts are useful tools that can be relied on to visualise huge amounts of data. These 7 JavaScript Pivot Widgets are some of the best ways to use them.
Pivot Charts are useful tools that can be relied on to visualise huge amounts of data. These 7 JavaScript Pivot Widgets are some of the best ways to use them.
44. Running a Python Script to Scrape LinkedIn Profiles From Google
 LinkedIn is a great place to find leads and engage with prospects. In order to engage with potential leads, you’ll need a list of users to contact. However, getting that list might be difficult because LinkedIn has made it difficult for web scraping tools. That is why I made a script to search Google for potential LinkedIn user and company profiles.
LinkedIn is a great place to find leads and engage with prospects. In order to engage with potential leads, you’ll need a list of users to contact. However, getting that list might be difficult because LinkedIn has made it difficult for web scraping tools. That is why I made a script to search Google for potential LinkedIn user and company profiles.
45. The Best 50 Sites to Learn About Data Science

46. Building Data Intelligence Brick by Brick: From Databricks' Playbook
 Book a free demo of Databricks Data Intelligence Platform via AWS Marketplace.
Book a free demo of Databricks Data Intelligence Platform via AWS Marketplace.
47. How to Stream From a REST API Using Kafka Connect
 Learn how to stream data efficiently from a REST API into a Kafka topic using Kafka Connect.
Learn how to stream data efficiently from a REST API into a Kafka topic using Kafka Connect.
48. 12 Mistakes that Data Scientists Make and How to Avoid Them
 Data analytics can transform how businesses operate. With companies having tons of data today , data analytics can help companies deliver valuable products and services to customers.
Data analytics can transform how businesses operate. With companies having tons of data today , data analytics can help companies deliver valuable products and services to customers.
49. The MinIO DataPod: A Reference Architecture for Exascale Computing
 MinIO has created a comprehensive blueprint for data infrastructure to support exascale AI and other large scale data lake workloads.
MinIO has created a comprehensive blueprint for data infrastructure to support exascale AI and other large scale data lake workloads.
50. 10 Best Hugging Face Datasets for Building NLP Models
 Hugging Face offers solutions and tools for developers and researchers. This article looks at the Best Hugging Face Datasets for Building NLP Models.
Hugging Face offers solutions and tools for developers and researchers. This article looks at the Best Hugging Face Datasets for Building NLP Models.
51. How to Create a Simple Dashboard with Google Forms and Google Data Studio

52. An Intro to No-Code Web Scraping
 Web scraping has broken the barriers of programming and can now be done in a much simpler and easier manner without using a single line of code.
Web scraping has broken the barriers of programming and can now be done in a much simpler and easier manner without using a single line of code.
53. From Data to Decisions: Harnessing Open Banking for Enhanced Business Performance
 Explore the transformative power of open banking and how it enhances business performance by leveraging shared customer data through secure APIs. Learn how open
Explore the transformative power of open banking and how it enhances business performance by leveraging shared customer data through secure APIs. Learn how open
54. Top 10 Data Science Project Ideas for 2020
 As an aspiring data scientist, the best way for you to increase your skill level is by practicing. And what better way is there for practicing your technical skills than making projects.
As an aspiring data scientist, the best way for you to increase your skill level is by practicing. And what better way is there for practicing your technical skills than making projects.
55. How to Make Any LLM More Accurate with Just a Few Lines of Code
 A look at using the open-source Cleanlab package to automatically boost the accuracy of LLMs with a few lines of code.
A look at using the open-source Cleanlab package to automatically boost the accuracy of LLMs with a few lines of code.
56. Data, Data, Data! 11(+2) Great Financial Data Vendors
 Hey everyone, Intern <a href="https://medium.com/@raobvinnakota" target="_blank">Rao</a> here. A few weeks ago, I worked with <a href="https://twitter.com/umitanuki/" target="_blank">Hitoshi</a> and <a href="https://twitter.com/iyoshyoshi/" target="_blank">Yoshi</a> to put together “9 Great Tools for Algo Trading”.
Hey everyone, Intern <a href="https://medium.com/@raobvinnakota" target="_blank">Rao</a> here. A few weeks ago, I worked with <a href="https://twitter.com/umitanuki/" target="_blank">Hitoshi</a> and <a href="https://twitter.com/iyoshyoshi/" target="_blank">Yoshi</a> to put together “9 Great Tools for Algo Trading”.
57. Data Analytics 101: Your First Steps Into a Data-Driven World
 Every business has its goals and the path to attaining those goals usually lies in data, it’s why our data is so important today.
Every business has its goals and the path to attaining those goals usually lies in data, it’s why our data is so important today.
58. "We Are Very Early in Our Work With LLMs," - Prem Ramaswami, Head of Data Commons at Google
 Google's Head of Data Commons joined HackerNoon to discuss grounding AI in verifiable data, and why "we are very early with LLMs," MCP's open approach.
Google's Head of Data Commons joined HackerNoon to discuss grounding AI in verifiable data, and why "we are very early with LLMs," MCP's open approach.
59. 4 Ways Open Banking is Set to Democratize Retail Investing for Everyone
 The widespread democratization of investment tools with open banking will fundamentally transform how the world saves its money.
The widespread democratization of investment tools with open banking will fundamentally transform how the world saves its money.
60. Dear Facebook, “Download My Archive” is Broken and That’s Not Okay

61. 17 Open Crime Datasets for Data Science and Machine Learning Projects
 For those looking to analyze crime rates or trends over a specific area or time period, we have compiled a list of the 16 best crime datasets made available for public use.
For those looking to analyze crime rates or trends over a specific area or time period, we have compiled a list of the 16 best crime datasets made available for public use.
62. Top 20 Twitter Datasets for Machine Learning Projects
 It is often very difficult for AI researchers to gather social media data for machine learning. Luckily, one free and accessible source of SNS data is Twitter.
It is often very difficult for AI researchers to gather social media data for machine learning. Luckily, one free and accessible source of SNS data is Twitter.
63. Life360 Potentially Leaves Its Users’ Sensitive Data at Risk
 The family safety app Life360 doesn’t have some standard guardrails to prevent a hacker from taking over an account and accessing sensitive information.
The family safety app Life360 doesn’t have some standard guardrails to prevent a hacker from taking over an account and accessing sensitive information.
64. The Importance of Hypothesis Testing
 Hypothesis tests are significant for evaluating answers to questions concerning samples of data.
Hypothesis tests are significant for evaluating answers to questions concerning samples of data.
65. Crunch the Lottery Numbers
 As we wrap up our journey into the world of lottery data, it's been a wild ride through numbers and probabilities.
As we wrap up our journey into the world of lottery data, it's been a wild ride through numbers and probabilities.
66. A Beginner's Guide to Understanding SQL Window Functions and Their Capabilities
 Welcome to the world of SQL and Window functions! If you're just starting out, you're in the right place.
Welcome to the world of SQL and Window functions! If you're just starting out, you're in the right place.
67. Make it Rain: How Repatriating Your Public Cloud Workload Can Save You Millions
 A high performance, cloud-native object store offers you economic benefits, performance benefits, control benefits - and they compound with scale.
A high performance, cloud-native object store offers you economic benefits, performance benefits, control benefits - and they compound with scale.
68. Increase The Size of Your Datasets Through Data Augmentation
 Access to training data is one of the largest blockers for many machine learning projects. Luckily, for various different projects, we can use data augmentation to increase the size of our training data many times over.
Access to training data is one of the largest blockers for many machine learning projects. Luckily, for various different projects, we can use data augmentation to increase the size of our training data many times over.
69. Introducing CatalyzeX: A Browser Extension for Machine Learning
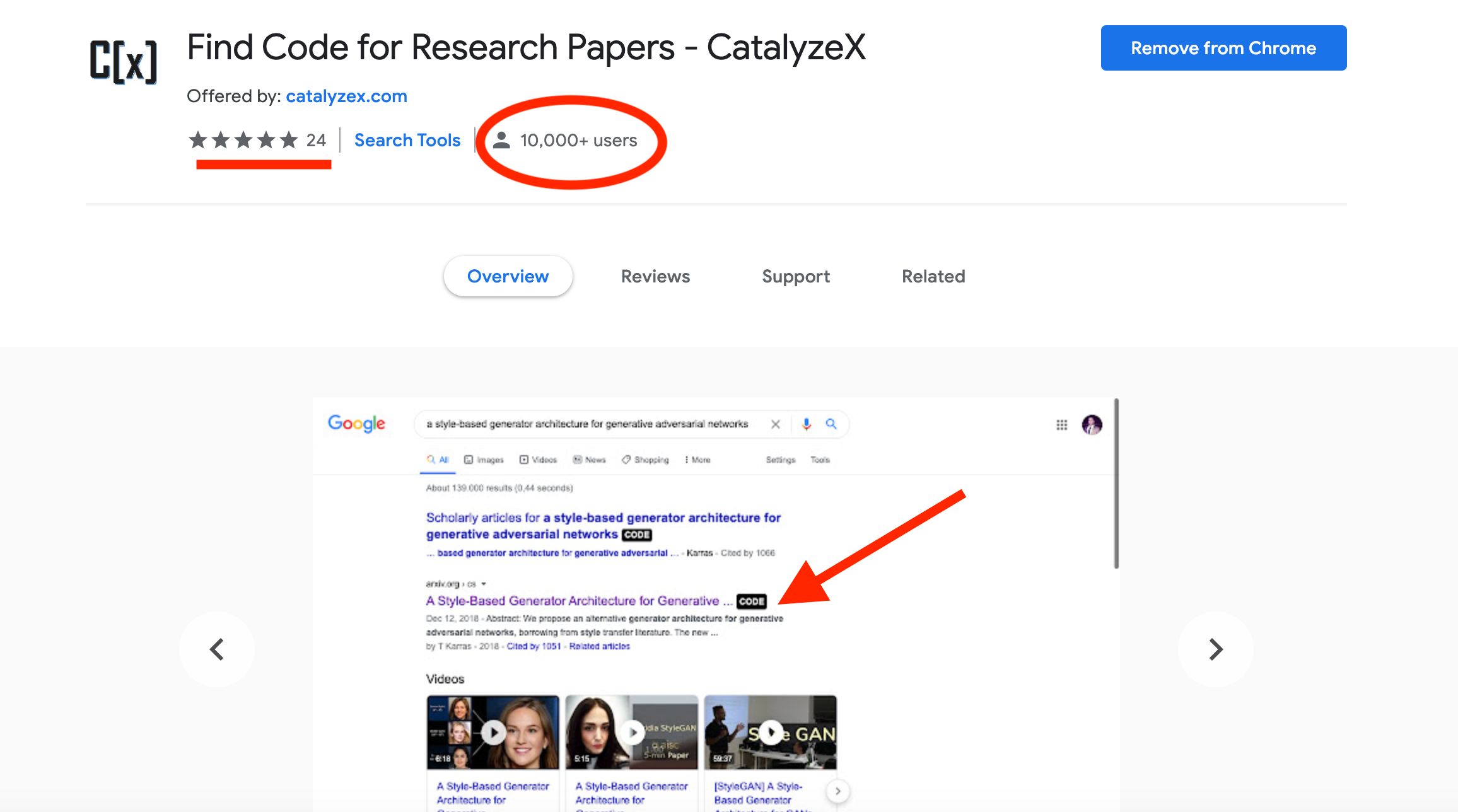 Andrew Ng likes it, you probably will too!
Andrew Ng likes it, you probably will too!
70. Delta Compression: Diff Algorithms And Delta File Formats [Practical Guide]
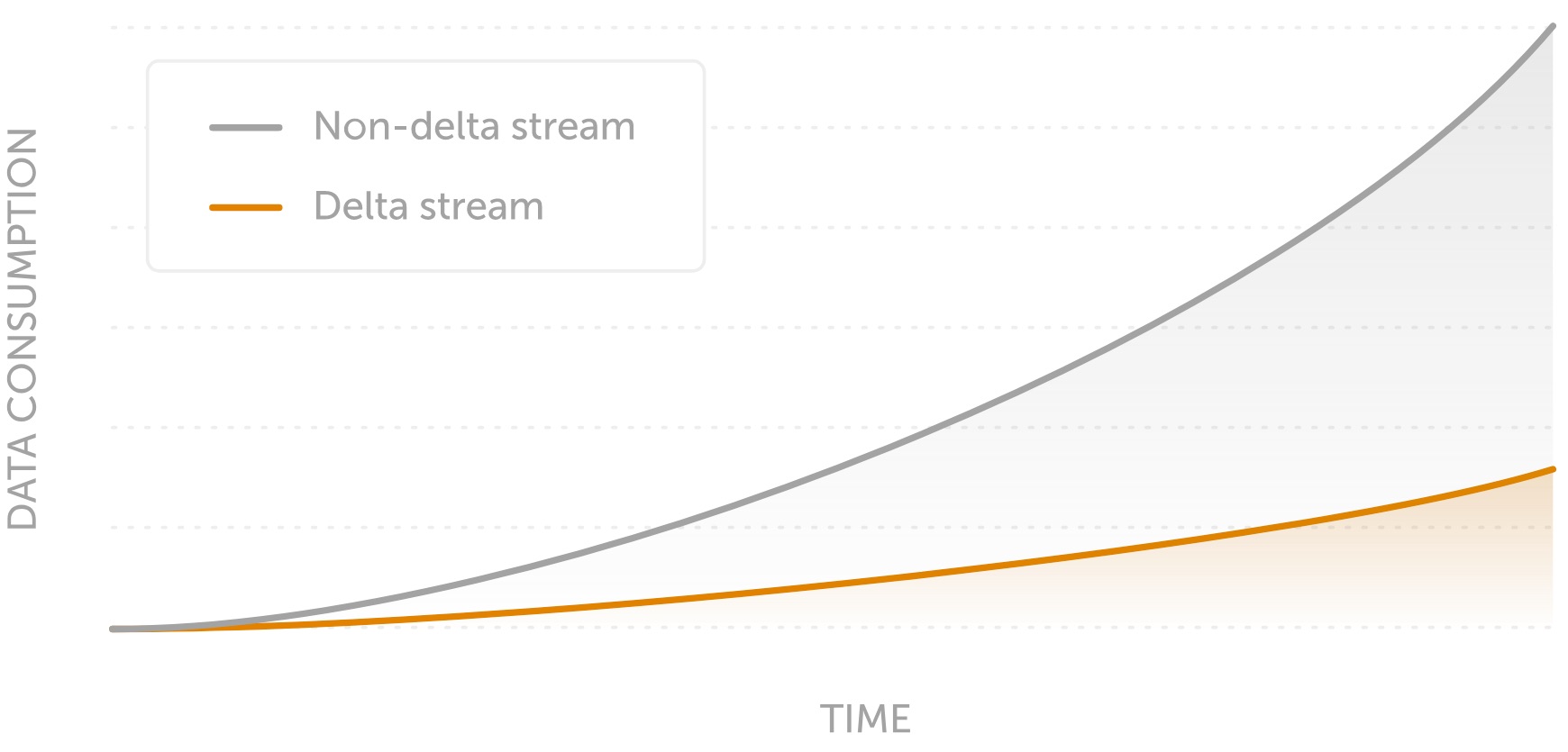 A diff algorithm outputs the set of differences between two inputs. These algorithms are the basis of a number of commonly used developer tools. Yet understanding the inner workings of diff algorithms is rarely necessary to use said tools.
A diff algorithm outputs the set of differences between two inputs. These algorithms are the basis of a number of commonly used developer tools. Yet understanding the inner workings of diff algorithms is rarely necessary to use said tools.
71. Solving Time Series Forecasting Problems: Principles and Techniques
 Explore time series analysis: from cross-validation, decomposition, transformation to advanced modeling with ARIMA, Neural Networks, and more.
Explore time series analysis: from cross-validation, decomposition, transformation to advanced modeling with ARIMA, Neural Networks, and more.
72. How I Created a Zero Trust Overlay Network in my Home
 Enabling a secure home automation experience, by creating a zero trust overlay network to access #HomeAssistant.
Enabling a secure home automation experience, by creating a zero trust overlay network to access #HomeAssistant.
73. Even Supermarkets Are Tracking Your Data Nowadays
 You are handing over a valuable treasure trove of data that may not be limited to the items in your shopping cart.
You are handing over a valuable treasure trove of data that may not be limited to the items in your shopping cart.
74. Busting AI Myths: "You Need Tons of Data for Machine Learning"
 Leading researchers like Karl Friston describe AI as "active inference" —creating computational statistical models that minimize prediction-error. The human brain operates much the same way, also learning from data. A common argument goes:
Leading researchers like Karl Friston describe AI as "active inference" —creating computational statistical models that minimize prediction-error. The human brain operates much the same way, also learning from data. A common argument goes:
75. Designing a Website for Data
 It’s complex to create the right design when the only visuals you have are based on data. Here’s how we did it.
It’s complex to create the right design when the only visuals you have are based on data. Here’s how we did it.
76. MCP, A2A, AGP, ACP: Making Sense of the New AI Protocols
 Let's learn everything you need to know about MCP, A2A, AGP, ACP—the new AI protocols.
Let's learn everything you need to know about MCP, A2A, AGP, ACP—the new AI protocols.
77. Building A Secure Data Economy: An Interview with Ocean Protocol's Founder Bruce Pon
 Ocean Protocol is technology that allows data sharing in a safe, secure and transparent manner without any central intermediary. Using Ocean Protocol, data scientists and artificial intelligence researchers can unlock and analyze big data, while respecting data privacy.
Ocean Protocol is technology that allows data sharing in a safe, secure and transparent manner without any central intermediary. Using Ocean Protocol, data scientists and artificial intelligence researchers can unlock and analyze big data, while respecting data privacy.
78. What Happens When You Get Sick Right Now?
 We are living in a weird time. Day by day we see more & more people coughing and getting sick, our neighbors, coworkers on Zoom calls, politicians, etc… But here’s when it becomes really, really scary — when you become one of “those” and have no clue what to do. Your reptile brain activates, you enter a state of panic, and engage complete freakout mode. That’s what happened to me this Monday, and I’m not sure I’m past this stage.
We are living in a weird time. Day by day we see more & more people coughing and getting sick, our neighbors, coworkers on Zoom calls, politicians, etc… But here’s when it becomes really, really scary — when you become one of “those” and have no clue what to do. Your reptile brain activates, you enter a state of panic, and engage complete freakout mode. That’s what happened to me this Monday, and I’m not sure I’m past this stage.
79. Writing a Scraping Bot with Python and Selenium
 Learning how to use Selenium and Python to interact with websites to get the data you need.
Learning how to use Selenium and Python to interact with websites to get the data you need.
80. Harnessing AI to Democratize Data Analysis: An Interview with the Founder of ANDRE
 Laurent Rochat, the founder of ANDRE, discusses the inception and vision of his company aimed at democratizing data analysis.
Laurent Rochat, the founder of ANDRE, discusses the inception and vision of his company aimed at democratizing data analysis.
81. AI Shouldn’t Have to Waste Time Reinventing ETL
 This article describes the challenges of data movement for AI, the need for extraction and loading pipelines and the benefits of using existing solutions.
This article describes the challenges of data movement for AI, the need for extraction and loading pipelines and the benefits of using existing solutions.
82. A Guide to Scraping HTML Tables with Pandas and BeautifulSoup
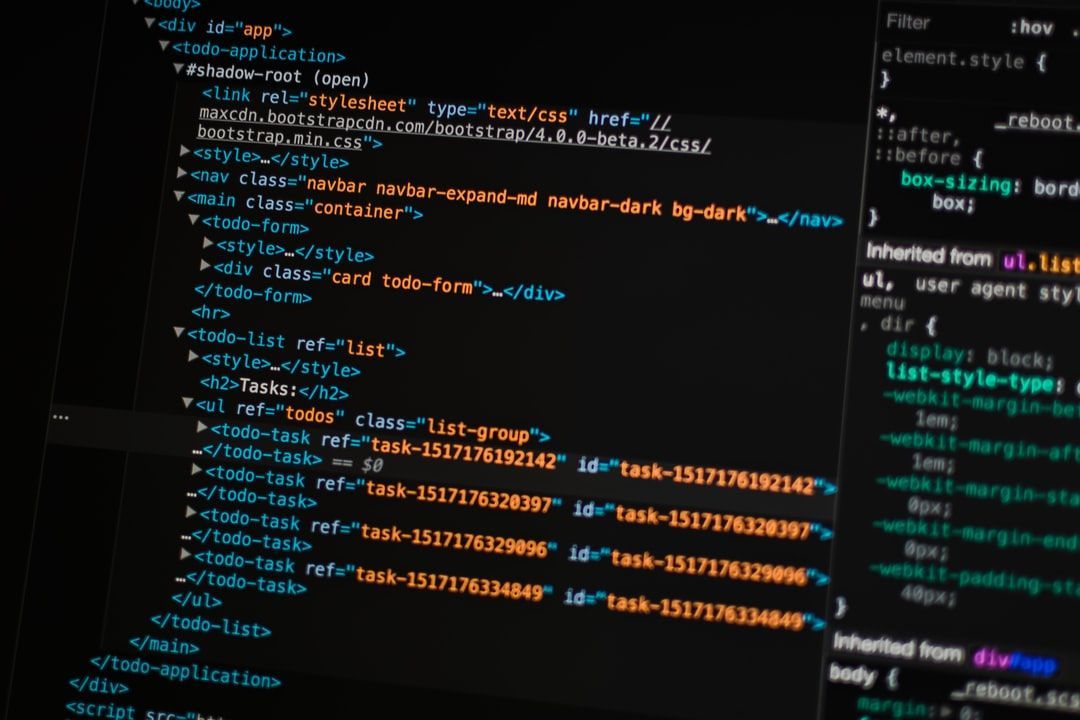 How to not get stuck when collecting tabular data from the internet.
How to not get stuck when collecting tabular data from the internet.
83. Open-Source Intelligence (OSINT) Use by Governments
 In the 1980s, the US military first coined the term ‘OSINT’. Since then, the dynamic reform of intelligence has been beneficial in many different scenarios.
In the 1980s, the US military first coined the term ‘OSINT’. Since then, the dynamic reform of intelligence has been beneficial in many different scenarios.
84. What Is E-Waste Hacking?
 You may know about e-waste's environmental risks, but what about its security risks? Here's how hackers use discarded devices to steal your personal data.
You may know about e-waste's environmental risks, but what about its security risks? Here's how hackers use discarded devices to steal your personal data.
85. Building an AI Red Team to Stop Problems Before They Start
 An incredible 87% of data science projects never go live.
An incredible 87% of data science projects never go live.
86. Data Fingerprinting in JavaScript
 I want to talk a little about how you can use content-based addressing (aka data fingerprinting) as a general approach to make your applications faster and more secure with some practical JavaScript examples.
I want to talk a little about how you can use content-based addressing (aka data fingerprinting) as a general approach to make your applications faster and more secure with some practical JavaScript examples.
87. Pickling and Unpickling in Python
 In this blog, you will learn about the Pickling and Unpickling process, although it is quite simple it is very important and useful.
In this blog, you will learn about the Pickling and Unpickling process, although it is quite simple it is very important and useful.
88. Data Access for Microservices
 If you want to access data in a distributed environment such as in a microservice architecture, then data services are the way to go. The idea is to create a data abstraction layer (DAL) that the rest of the system’s applications and services can share. Thus, a data service gives you a generalized interface to the data you’re exposing and provides access to it in a standard manner. This would be in a well-understood protocol and a known data format. For example, a popular approach is to use JSON via HTTP/S.
If you want to access data in a distributed environment such as in a microservice architecture, then data services are the way to go. The idea is to create a data abstraction layer (DAL) that the rest of the system’s applications and services can share. Thus, a data service gives you a generalized interface to the data you’re exposing and provides access to it in a standard manner. This would be in a well-understood protocol and a known data format. For example, a popular approach is to use JSON via HTTP/S.
89. Secrets to Growth Marketing Data Engineering – Even in This Down Economy
 Marketing is a big business and it's only going to grow bigger. One reason for this is that marketers need to keep growing the list of data points.
Marketing is a big business and it's only going to grow bigger. One reason for this is that marketers need to keep growing the list of data points.
90. The Best Data Visualizations for Grabbing Readers’ Attention

91. Azure Data Factory: An Amazing Data Migration Tool

92. Comparing Meilisearch and Manticore Search Using Key Benchmarks
 Both Manticore and Meilisearch position themselves as full-text search engines. The key element in full-text search engines is how they rank documents.
Both Manticore and Meilisearch position themselves as full-text search engines. The key element in full-text search engines is how they rank documents.
93. The Pros and Cons of Collecting Online and Offline Data

94. Build vs Buy: What We Learned by Implementing a Data Catalog
 Why we chose to finally buy a unified data workspace (Atlan), after spending 1.5 years building our own internal solution with Amundsen and Atlas
Why we chose to finally buy a unified data workspace (Atlan), after spending 1.5 years building our own internal solution with Amundsen and Atlas
95. How to Fix Your Organization’s Meta Pixel Problem
 Although Meta has policies against collecting sensitive data, our reporting over the past year found that the pixel often did just that...
Although Meta has policies against collecting sensitive data, our reporting over the past year found that the pixel often did just that...
96. Why Agents Stall in Production: When Real-Time Retrieval Meets Reality
 Agents that work in demos fail at scale. Learn why 429/403 happen under concurrency and how to build reliable, accurate evidence acquisition.
Agents that work in demos fail at scale. Learn why 429/403 happen under concurrency and how to build reliable, accurate evidence acquisition.
97. Goodbye Product Management - Hello Data Product Leadership
 Product Management is out, Data Product Leadership is in! Discover how this pivotal shift can revolutionize your business strategy!
Product Management is out, Data Product Leadership is in! Discover how this pivotal shift can revolutionize your business strategy!
98. Sustainable Computing beyond the Cloud
 Extreme increases in data streams are expanding the cloud's carbon footprint; a sustainable alternative to Cloud dependence has been developed.
Extreme increases in data streams are expanding the cloud's carbon footprint; a sustainable alternative to Cloud dependence has been developed.
99. How to Scrape NLP Datasets From Youtube
 Too lazy to scrape nlp data yourself? In this post, I’ll show you a quick way to scrape NLP datasets using Youtube and Python.
Too lazy to scrape nlp data yourself? In this post, I’ll show you a quick way to scrape NLP datasets using Youtube and Python.
100. The Noonification: How Often Do NFTs Pass The Howey Test? (1/13/2023)
 1/13/2023: Top 5 stories on the Hackernoon homepage!
1/13/2023: Top 5 stories on the Hackernoon homepage!
101. Efficient Data Storage for Rapid Analysis and Visualization
 In this article, I want to share one of the ways that big data can be stored and used for analysis.
In this article, I want to share one of the ways that big data can be stored and used for analysis.
102. The Top Big Data Consulting Firms
 Thanks to big data, today an organization can quickly obtain the necessary information from an unordered data set and deploy it effectively. The growing popularity of big data analytics has led to a significant increase in the number of companies providing big data solutions and related services.
Thanks to big data, today an organization can quickly obtain the necessary information from an unordered data set and deploy it effectively. The growing popularity of big data analytics has led to a significant increase in the number of companies providing big data solutions and related services.
103. 8-Ways Data Mining Can Improve your Business
 If your company is trying to make sense of the customer data, here’s a not-so-surprising fact for you. You aren’t alone. Far too many companies want to understand data and gain an in-depth insight into the information they are sitting on. Let’s be clear that today, the success of a business lies in how efficient their data mining process is. Their expertise to process the available data as this can help them to decipher age-old questions that make or break them:
If your company is trying to make sense of the customer data, here’s a not-so-surprising fact for you. You aren’t alone. Far too many companies want to understand data and gain an in-depth insight into the information they are sitting on. Let’s be clear that today, the success of a business lies in how efficient their data mining process is. Their expertise to process the available data as this can help them to decipher age-old questions that make or break them:
104. DOCSIS 3.1 Technology: Everything You Need to Know
 In this tech guide, we will cover the important details about DOCSIS 3.1 technology.
In this tech guide, we will cover the important details about DOCSIS 3.1 technology.
105. What the Heck Is SDF?
 Is dbt kicking your butt? Take a look at SDF.
Is dbt kicking your butt? Take a look at SDF.
106. What is a Data Reliability Engineer?
 With each day, enterprises increasingly rely on data to make decisions.
With each day, enterprises increasingly rely on data to make decisions.
107. Using a Relational Database to Query Unstructured Data
 Using Relational Database to search inside unstructured data
Using Relational Database to search inside unstructured data
108. Search and Extract: Why This AI Pattern Matters, Tutorial, and Example
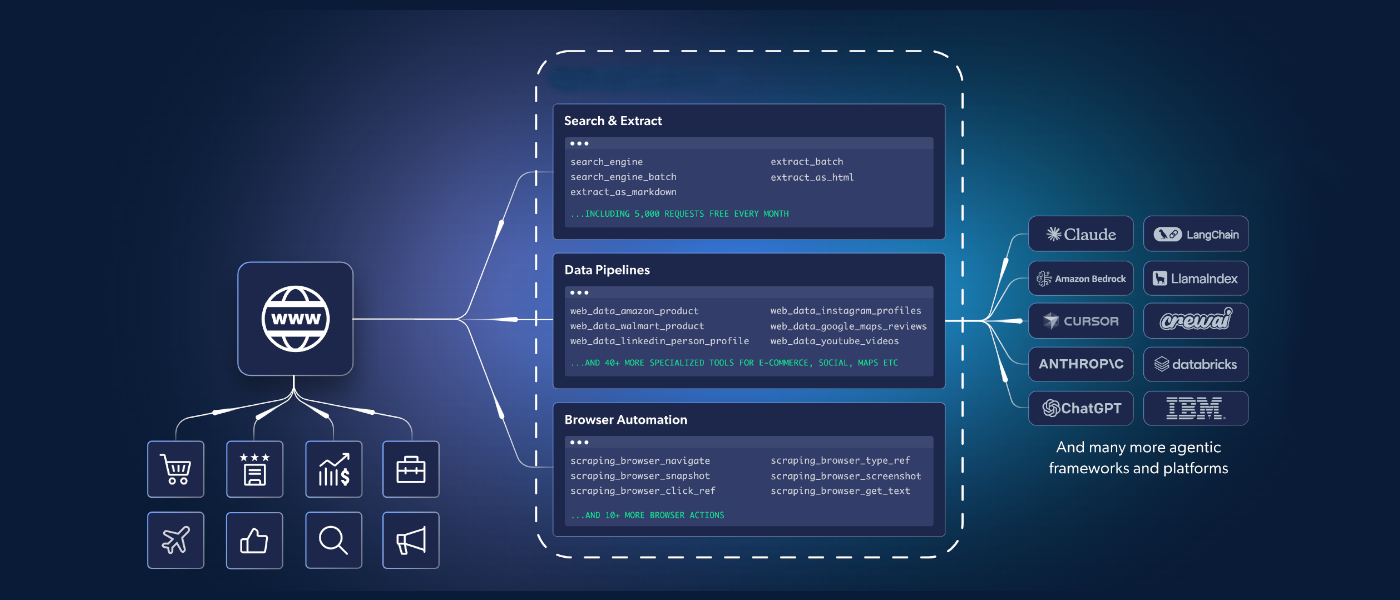 Learn why search-and-extract matters for AI enrichment and research. Step-by-step tutorial using SERP API, Web Unlocker, and Browser API with a real example.
Learn why search-and-extract matters for AI enrichment and research. Step-by-step tutorial using SERP API, Web Unlocker, and Browser API with a real example.
109. Statistics Cheat Sheet: A Beginner's Guide to Probability and Random Events
 A beginner’s guide to Probability and Random Events. Understand the key statistics concepts and areas to focus on to ace your next data science interview.
A beginner’s guide to Probability and Random Events. Understand the key statistics concepts and areas to focus on to ace your next data science interview.
110. Jetpack DataStore in Android Explained
 The JetPack Datastore is an Android data storage solution that is helpful when making Android-based mobile apps by providing a way for data to be retrieved.
The JetPack Datastore is an Android data storage solution that is helpful when making Android-based mobile apps by providing a way for data to be retrieved.
111. An Internal Email to Tim Cook and the State of Business Intelligence
 We get a glimpse into the inner workings of a valuable company and it turns out it's not all sunshine and rainbows.
We get a glimpse into the inner workings of a valuable company and it turns out it's not all sunshine and rainbows.
112. Please Dont Build Your Data Pipeline using Singer

113. Efficient Data Deduplication: Optimizing Storage Space with NTFS, ZFS, & BTRFS
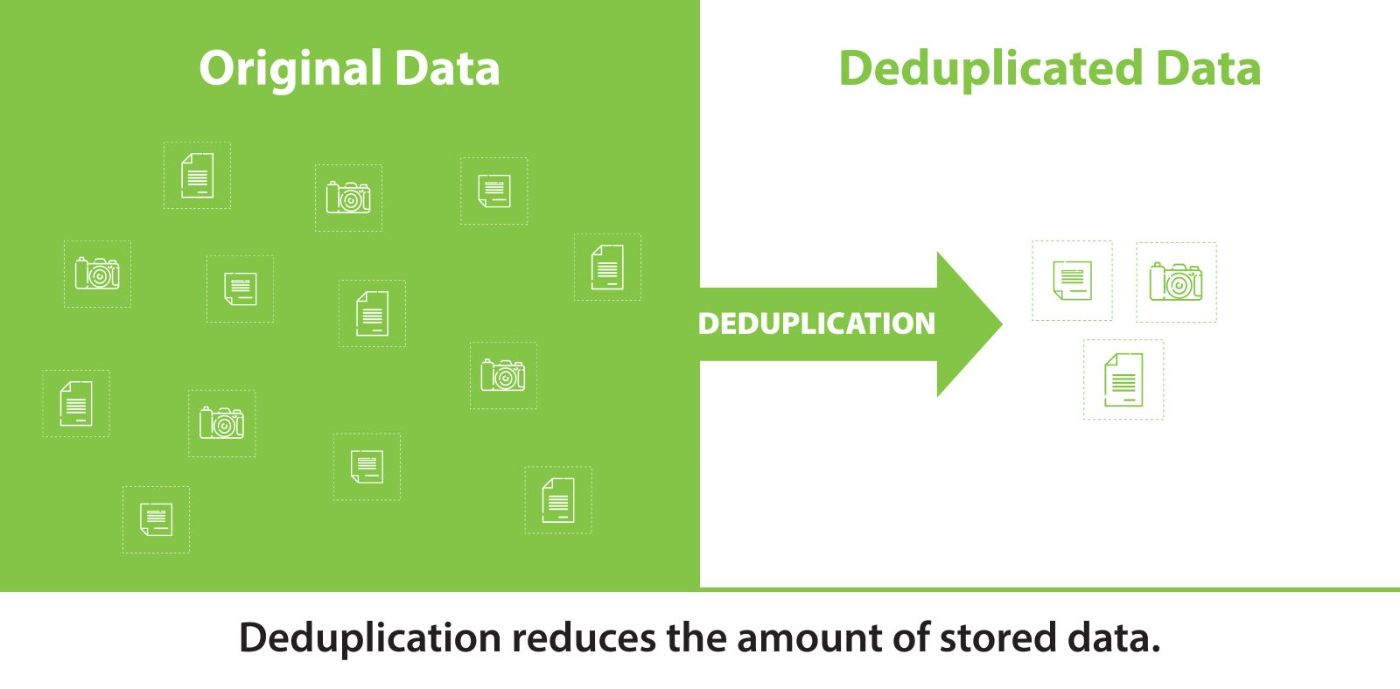 Deduplication serves a variety of purposes and can be applied in numerous scenarios to address specific challenges effectively.
Deduplication serves a variety of purposes and can be applied in numerous scenarios to address specific challenges effectively.
114. Special Database 18: What Is It and How Does It Work?
 This dataset contains black-and-white mugshot photographs of 1,573 people. The 3,248 undated photos appear to be many decades old...
This dataset contains black-and-white mugshot photographs of 1,573 people. The 3,248 undated photos appear to be many decades old...
115. Estimating Price Elasticity with Machine Learning
 Using machine learning, multi-linear regression, and scikit-learn to estimate price elasticity for wine products.
Using machine learning, multi-linear regression, and scikit-learn to estimate price elasticity for wine products.
116. Which Type of Data Center Cooling System Is Best for You?
 Data center cooling is crucial to keeping servers running efficiently. But which cooling method is the most effective?
Data center cooling is crucial to keeping servers running efficiently. But which cooling method is the most effective?
117. The 20 Slides That Raised $7 Million
 Fundraising is a funny art.
Fundraising is a funny art.
118. Trino: The Open-source Data Query Engine That Split from Facebook
 If you want to accelerate Trino queries with a response time of seconds to minutes, click here to learn how Trino helps engineers.
If you want to accelerate Trino queries with a response time of seconds to minutes, click here to learn how Trino helps engineers.
119. Data Quality Score: One Score to Rule Them All
 One score to rule them all, one score to find them, one score to bring them all and in the data's clarity bind them.
One score to rule them all, one score to find them, one score to bring them all and in the data's clarity bind them.
120. 8 Cloud Computing Trends to Watch in 2021
 Cloud computing has grown exponentially in the past decade and is not about to stop. As predicted by Forrester’s research, the global public cloud infrastructure will grow 35% in 2021, many thanks to the pandemic. Due to the lingering effects of covid-19 in 2021, the cloud will be the key focus for organizations looking for increased scalability, business continuity, and cost-efficiency.
Cloud computing has grown exponentially in the past decade and is not about to stop. As predicted by Forrester’s research, the global public cloud infrastructure will grow 35% in 2021, many thanks to the pandemic. Due to the lingering effects of covid-19 in 2021, the cloud will be the key focus for organizations looking for increased scalability, business continuity, and cost-efficiency.
121. Living in the world of AI - The Human Transformation
 Today, if you stop and ask anyone working in a technology company, “What is the one thing that would help them change the world or make them grow faster than anyone else in their field?” The answer would be Data. Yes, data is everything. Because data can essentially change, cure, fix, and support just about any problem. Data is the truth behind everything from finding a cure for cancer to studying the shifting weather patterns.
Today, if you stop and ask anyone working in a technology company, “What is the one thing that would help them change the world or make them grow faster than anyone else in their field?” The answer would be Data. Yes, data is everything. Because data can essentially change, cure, fix, and support just about any problem. Data is the truth behind everything from finding a cure for cancer to studying the shifting weather patterns.
122. Using Machine Learning to Build a Ride Acceptance Model for Uber
 Objective: Predict if a driver will accept a ride request or not and find the probability of acceptance.
Objective: Predict if a driver will accept a ride request or not and find the probability of acceptance.
123. Unraveling the Maze of Large JSON Files: Tips and Tools for Local JSON Parsing
 Discover how a backend developer overcomes obstacles in processing large JSON log files.
Discover how a backend developer overcomes obstacles in processing large JSON log files.
124. 6 Biggest Differences Between Airbyte And Singer
 We’ve been asked if Airbyte was being built on top of Singer. Even though we loved the initial mission they had, that won’t be the case. Aibyte's data protocol will be compatible with Singer’s, so that you can easily integrate and use Singer’s taps, but our protocol will differ in many ways from theirs.
We’ve been asked if Airbyte was being built on top of Singer. Even though we loved the initial mission they had, that won’t be the case. Aibyte's data protocol will be compatible with Singer’s, so that you can easily integrate and use Singer’s taps, but our protocol will differ in many ways from theirs.
125. Five Data Quality Tools You Should Know
 Enterprises ensure their data is accurate, consistent, complete, and reliable, by relying on data quality tools
Enterprises ensure their data is accurate, consistent, complete, and reliable, by relying on data quality tools
126. Software Development Tricks Coding for Beginners and More
 This week on HackerNoon's Stories of the Week, we looked at three articles that covered the world of software development from employment to security.
This week on HackerNoon's Stories of the Week, we looked at three articles that covered the world of software development from employment to security.
127. Downloading Data as a File with Alpine.js
 A quick demonstration of using JavaScript to download ad hoc data.
A quick demonstration of using JavaScript to download ad hoc data.
128. At the Potomac, Where DC, the Analog Political National Capital, and VC, the Digital Capital, Meet
 Data Centers and AI demand for electricity provide a forcing funciton to roduce policies designed to provide essential reliable, abundant, affordable energy.
Data Centers and AI demand for electricity provide a forcing funciton to roduce policies designed to provide essential reliable, abundant, affordable energy.
129. Why Sapien.io Could Be the Scale.AI of Crypto
 Could Sapien.io become crypto's Scale.AI? With its TGE nearing, here is a deep dive into the AI-powered Web3 startup co-founded by Polymath’s Trevor Koverko.
Could Sapien.io become crypto's Scale.AI? With its TGE nearing, here is a deep dive into the AI-powered Web3 startup co-founded by Polymath’s Trevor Koverko.
130. 10 Ways to Optimize Your Database
 Take these 10 steps to optimize your database.
Take these 10 steps to optimize your database.
131. A Look at the Trends in Developer Jobs: A Meta Analysis of Stack Overflow Surveys
 I'm really interested in the trends we see in the software engineering job market.
I'm really interested in the trends we see in the software engineering job market.
132. Principles of a Clean Relational Database
 The article describes how a relational database should be designed to properly work in OLTP mode.
The article describes how a relational database should be designed to properly work in OLTP mode.
133. Busting Data Science Myths: "You Need a PhD, Extensive Python Skills, and Tons of Experience"
 DJ Patil and Jeff Hammerbacher coined the title Data Scientist while working at LinkedIn and Facebook, respectively, to mean someone who “uses data to interact with the world, study it and try to come up with new things.”
DJ Patil and Jeff Hammerbacher coined the title Data Scientist while working at LinkedIn and Facebook, respectively, to mean someone who “uses data to interact with the world, study it and try to come up with new things.”
134. 3 New Startups That Are Innovating DeFi Data Analysis Technology
 Data analysis as a whole is one of the most important industries. Now that DeFi is a full-fledged industry, there is a growing need for valuable data analytics.
Data analysis as a whole is one of the most important industries. Now that DeFi is a full-fledged industry, there is a growing need for valuable data analytics.
135. Using Real-Time Data in Digital Marketing
 Learn how you can use real-time data in digital marketing for customer engagement and retention, analyze real-time data for faster decision-making
Learn how you can use real-time data in digital marketing for customer engagement and retention, analyze real-time data for faster decision-making
136. The New Data Engineering Landscape: DataOps, VectorOps, and LangChain
 DataOps, VectorOps, and LangChain integration creates powerful applications that combine efficient data management, high-dimensional data processing.
DataOps, VectorOps, and LangChain integration creates powerful applications that combine efficient data management, high-dimensional data processing.
137. Azure Data Factory - Datasets and Linked Services
 ADF Concepts & relation among the ADF components
ADF Concepts & relation among the ADF components
138. How to model an efficient database for your application
 What is Database Modeling?
What is Database Modeling?
139. What is an API, Simply Explained
 Connectivity is something amazing. Right now, we are used to use our computers or phones to buy, post, watch, etc. We can do lots of things actually. We are connected to the world and to each other.
Connectivity is something amazing. Right now, we are used to use our computers or phones to buy, post, watch, etc. We can do lots of things actually. We are connected to the world and to each other.
140. What You Need to Know About Python’s Data Model
 A Concise Overview of Data Model, Special Methods and the Collection API in Python.
A Concise Overview of Data Model, Special Methods and the Collection API in Python.
141. How to Chat With Your Data Using OpenAI, Pinecone, Airbyte and Langchain: A Guide
 Learn how to build an AI chat bot for your own data within 40 minutes. An end-to-end LLM tutorial.
Learn how to build an AI chat bot for your own data within 40 minutes. An end-to-end LLM tutorial.
142. Optimize Data Migration in MongoDB: Resharding Techniques for Speed and Scalability
 Distribute a MongoDB collection fast, "reshard-to-shard" distributes data quicker than others methods, spreading your workload across multiple shards in hours.
Distribute a MongoDB collection fast, "reshard-to-shard" distributes data quicker than others methods, spreading your workload across multiple shards in hours.
143. AI's Ethical Evolution: Vyvo Smart Chain's Mariana Krym on Redefining Data Ownership
 Discover how Mariana Krym, Co-Founder & COO of Vyvo Smart Chain, is building VAI OS to revolutionize AI with user-centric data privacy and ethical design.
Discover how Mariana Krym, Co-Founder & COO of Vyvo Smart Chain, is building VAI OS to revolutionize AI with user-centric data privacy and ethical design.
144. Dataism: Idea or Ideology?
 Dataism suggests that the entire universe can be interpreted as data flows and that all phenomena, including human behaviour, can be reduced to data processes.
Dataism suggests that the entire universe can be interpreted as data flows and that all phenomena, including human behaviour, can be reduced to data processes.
145. Handling ORM-Free Data Access Layer in TypeScript With MongoDB
 In this article, we’re going to discuss an alternative approach to handling data access layer in TypeScript with MongoDB, without using ORM.
In this article, we’re going to discuss an alternative approach to handling data access layer in TypeScript with MongoDB, without using ORM.
146. Facebook's Deepfake Challenge That Will defeat Deepfakes. Hopefully.
 Nowadays, we are seeing a new wave and great advancements in different technologies. Things like Deep Learning, Computer Vision, and Artificial Intelligence are improving every single day. And Researchers and scientists are having amazing use-cases with these technologies which can change the direction of our world.
Nowadays, we are seeing a new wave and great advancements in different technologies. Things like Deep Learning, Computer Vision, and Artificial Intelligence are improving every single day. And Researchers and scientists are having amazing use-cases with these technologies which can change the direction of our world.
147. 10 Ways to Reduce Data Loss and Potential Downtime Of Your Database
 In this article, you can find ten actionable methods to protect your mission-critical database.
In this article, you can find ten actionable methods to protect your mission-critical database.
148. A Detailed Guide To Using Apache Storm
 Continuous streams of data are ubiquitous and becoming even more so with the increasing number of IoT devices being used. Of course this data is stored, processed and analyzed to provide predictive, actionable results. But petabytes take long to analyze, even with Hadoop (as good as MapReduce may be) or Spark (a remedy to the limitations of MapReduce).
Continuous streams of data are ubiquitous and becoming even more so with the increasing number of IoT devices being used. Of course this data is stored, processed and analyzed to provide predictive, actionable results. But petabytes take long to analyze, even with Hadoop (as good as MapReduce may be) or Spark (a remedy to the limitations of MapReduce).
149. How 5 Massive Data Breaches Could Have Been Prevented
 One of the biggest losses for companies? Inadequate cybersecurity.
One of the biggest losses for companies? Inadequate cybersecurity.
150. Avoiding the Pitfalls of Data Mesh Adoption
 Chefs cook data in decentralized kitchens, but beware! Lack of training, clarity, & governance can turn your feast into a Kitchen Nightmare.
Chefs cook data in decentralized kitchens, but beware! Lack of training, clarity, & governance can turn your feast into a Kitchen Nightmare.
151. Using a REST API with Python
 Requesting fitness data (backlog) from Terra requires HTTP requests, so I’m writing an essential guide here on using a REST API with Python.
Requesting fitness data (backlog) from Terra requires HTTP requests, so I’m writing an essential guide here on using a REST API with Python.
152. How The Heck Did Robinhood Become So Popular? A Data Driven Analysis
 Robinhood launched over seven years ago as a stock prediction app, before it became the brokerage we have today.
Robinhood launched over seven years ago as a stock prediction app, before it became the brokerage we have today.
153. Hot-Cold Data Separation: How It Cuts Your Storage Costs by 70%
 Apparently hot-cold data separation is hot now. Let's figure out why.
Apparently hot-cold data separation is hot now. Let's figure out why.
154. Google Analytics Heartbeat Data Visualization
 An experiment in real-time data visualization
An experiment in real-time data visualization
155. Fenwick Tree Explained
 Fenwick Tree is an interesting data structure that uses binary number properties to solve point update and range queries in your code in some situations.
Fenwick Tree is an interesting data structure that uses binary number properties to solve point update and range queries in your code in some situations.
156. 4 iPaaS Use Cases for 2023
 iPaaS products and providers can help integrate data and applications between the cloud and businesses. Here are some compelling ways to use iPaaS solutions th
iPaaS products and providers can help integrate data and applications between the cloud and businesses. Here are some compelling ways to use iPaaS solutions th
157. Lying to the Blockchain: Applying The Garbage In, Garbage Out Problem to Decentralized Networks
 In this article, we address a notion that is often overlooked (mostly, intentionally) of how real-world data interacts with blockchains.
In this article, we address a notion that is often overlooked (mostly, intentionally) of how real-world data interacts with blockchains.
158. Create a Custom AI Slack Bot for Streamlined Data Analytics in Natural Language
 Organizations are always looking for ways to make their data analysis process more efficient. Here's an open-source Slack bot that does just that.
Organizations are always looking for ways to make their data analysis process more efficient. Here's an open-source Slack bot that does just that.
159. Spyse Introduction: Cybersecurity Search Engine for Data Gathering
 Data gathering has always been a long process which required multiple services running simultaneously and spending hours scanning alone. With new services like the Spyse search engine, these processes have been simplified drastically.
Data gathering has always been a long process which required multiple services running simultaneously and spending hours scanning alone. With new services like the Spyse search engine, these processes have been simplified drastically.
160. About the Wright Brothers Journey to Accurate Wind Tunnel Data
 I originally published this story for the Atlan Humans of Data publication.
I originally published this story for the Atlan Humans of Data publication.
161. Advancing User Data Governance with Data Lineage
 This article will discuss how data lineage can help in user data governance and explore how serverless technology can be incorporated to achieve better results.
This article will discuss how data lineage can help in user data governance and explore how serverless technology can be incorporated to achieve better results.
162. On the difficulty of creating a data science code of ethics

163. What is a Minidump?
 Adding minidump support came with a number of technical challenges that we had to address.
Adding minidump support came with a number of technical challenges that we had to address.
164. A Guide to Authoring Power BI Reports on Real-Time Google Sheets Data
 CData Power BI Connectors provide self-service integration with Microsoft Power BI. The CData Power BI Connector for Google Sheets links your Power BI reports to real-time Google Sheets data. You can monitor Google Sheets data through dashboards and ensure that your analysis reflects Google Sheets data in real-time by scheduling refreshes or refreshing on demand. This article details how to use the Power BI Connector to create real-time visualizations of Google Sheets data in Microsoft Power BI Desktop.
CData Power BI Connectors provide self-service integration with Microsoft Power BI. The CData Power BI Connector for Google Sheets links your Power BI reports to real-time Google Sheets data. You can monitor Google Sheets data through dashboards and ensure that your analysis reflects Google Sheets data in real-time by scheduling refreshes or refreshing on demand. This article details how to use the Power BI Connector to create real-time visualizations of Google Sheets data in Microsoft Power BI Desktop.
165. A Guide to Importing Smartsheet Data into SQL Server using SSIS
 Easily back up Smartsheet data to SQL Server using the SSIS components for Smartsheet.
Easily back up Smartsheet data to SQL Server using the SSIS components for Smartsheet.
166. These Companies Are Collecting Data From Your Car
 Most drivers have no idea what data is being transmitted from their vehicles, let alone who exactly is collecting, analyzing, and sharing that data...
Most drivers have no idea what data is being transmitted from their vehicles, let alone who exactly is collecting, analyzing, and sharing that data...
167. Football Data Analysis Using Machine Learning Models Can Potentially Boost Throw-Ins!
 “Can machine learning models help improve ball accuracy, precision and retention, leading to scoring after throw-ins?
“Can machine learning models help improve ball accuracy, precision and retention, leading to scoring after throw-ins?
168. What Will be the 3 Biggest Software Development Trends of 2022?
 The number of software developers globally is due to almost double by 2030, yet InterSystems research has found that more than 8 out of 10 developers currently feel they work in a pressured environment. Creating a better experience for developers is key for inciting innovation, but the current data environment continues to evolve in ways that challenge the experience at every turn.
The number of software developers globally is due to almost double by 2030, yet InterSystems research has found that more than 8 out of 10 developers currently feel they work in a pressured environment. Creating a better experience for developers is key for inciting innovation, but the current data environment continues to evolve in ways that challenge the experience at every turn.
169. How Can You Minimize Your Online Footprint

170. Python: Effective Techniques for Managing Dates in DataFrame
 In data analysis and time series processing, working with date columns is essential for extracting meaningful insights from datasets.
In data analysis and time series processing, working with date columns is essential for extracting meaningful insights from datasets.
171. The Best Method for Bulk Fetching ERC20 Token Balances
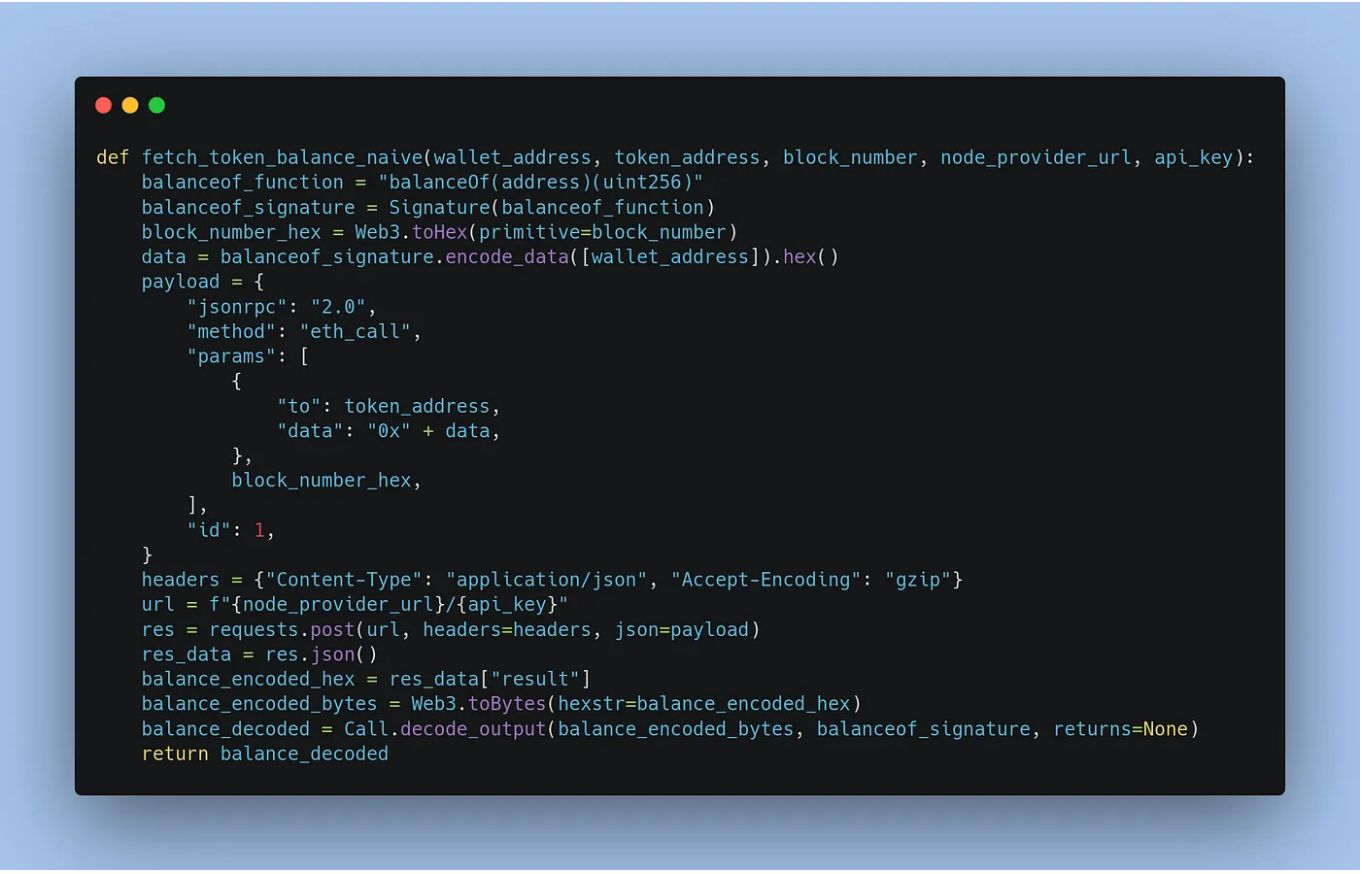 in this article, I'll show you the hassle and show you the best way to fetch token balances.
in this article, I'll show you the hassle and show you the best way to fetch token balances.
172. Artificial Intelligence and Big Data
 Artificial Intelligence and Big Data. These two terms seem to permeate the tech world in every possible way one can think of. Along with giant terms like Machine Learning, IoT, blockchain and related ones, AI and Big Data are set to dominate our world in the years ahead.
Artificial Intelligence and Big Data. These two terms seem to permeate the tech world in every possible way one can think of. Along with giant terms like Machine Learning, IoT, blockchain and related ones, AI and Big Data are set to dominate our world in the years ahead.
173. Harnessing Scalable Vector Graphics (SVG) for Effective Data Visualization
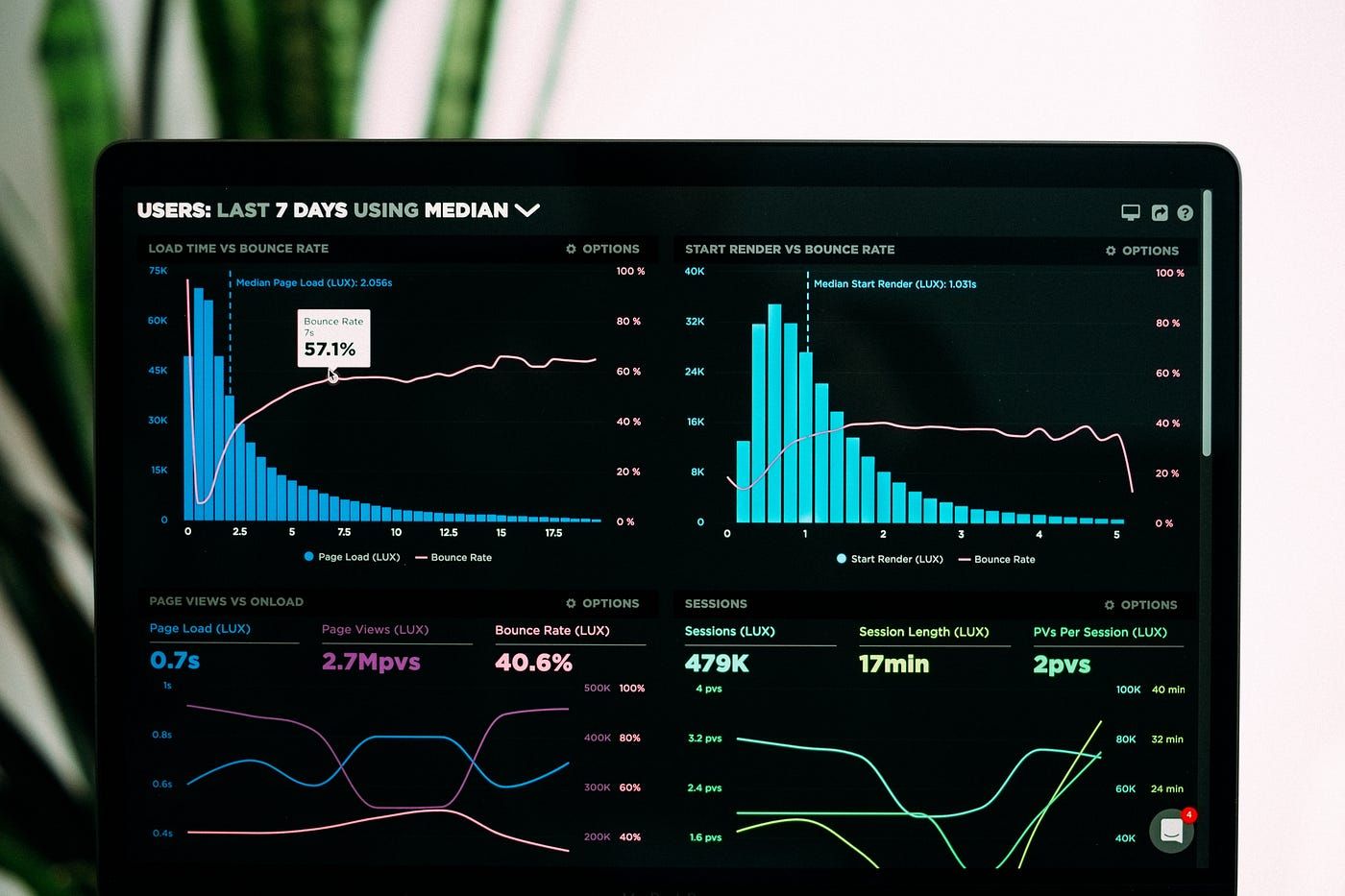 Learn About SVG for Data Visualization, to make Complex Information Clear and Beautiful.
Learn About SVG for Data Visualization, to make Complex Information Clear and Beautiful.
174. How Facebook Makes Money and Why You Should Worry
 Facebook sells ads, as Mark Zuckerberg famously and patiently explained to Congress, but it’s a little more complicated than that.
Facebook sells ads, as Mark Zuckerberg famously and patiently explained to Congress, but it’s a little more complicated than that.
175. A JavaScript Infographic: Data Science Salaries in 2022
 Data visualisation infographic with insights on salary level of data scientists - how to create the JavaScript dashboard and analyse its data
Data visualisation infographic with insights on salary level of data scientists - how to create the JavaScript dashboard and analyse its data
176. Integrate AI into Data Mapping to Drive Business Decision Making
 Prior to analyzing large chunks of data, enterprises must homogenize them in a way that makes them available and accessible to decision-makers. Presently, data comes from many sources, and every particular source can define similar data points in different ways. Say for example, the state field in a source system may exhibit “Illinois” but the destination keeps it is as “IL”.
Prior to analyzing large chunks of data, enterprises must homogenize them in a way that makes them available and accessible to decision-makers. Presently, data comes from many sources, and every particular source can define similar data points in different ways. Say for example, the state field in a source system may exhibit “Illinois” but the destination keeps it is as “IL”.
177. Leveraging Data Science in eCommerce: 7 Projects to Try
 As an online retailer, how can you improve your business? Of course through providing a better customer experience. An e-commerce company needs to have a well understanding of the following factors:
As an online retailer, how can you improve your business? Of course through providing a better customer experience. An e-commerce company needs to have a well understanding of the following factors:
178. Analyzing Data From U.S. Road Accidents With Data Visualization
 In this article, we would be analyzing data related to US road accidents, which can be utilized to study accident-prone locations and influential factors.
In this article, we would be analyzing data related to US road accidents, which can be utilized to study accident-prone locations and influential factors.
179. A Comprehensive Guide for Building Efficient Data Structures in Dart
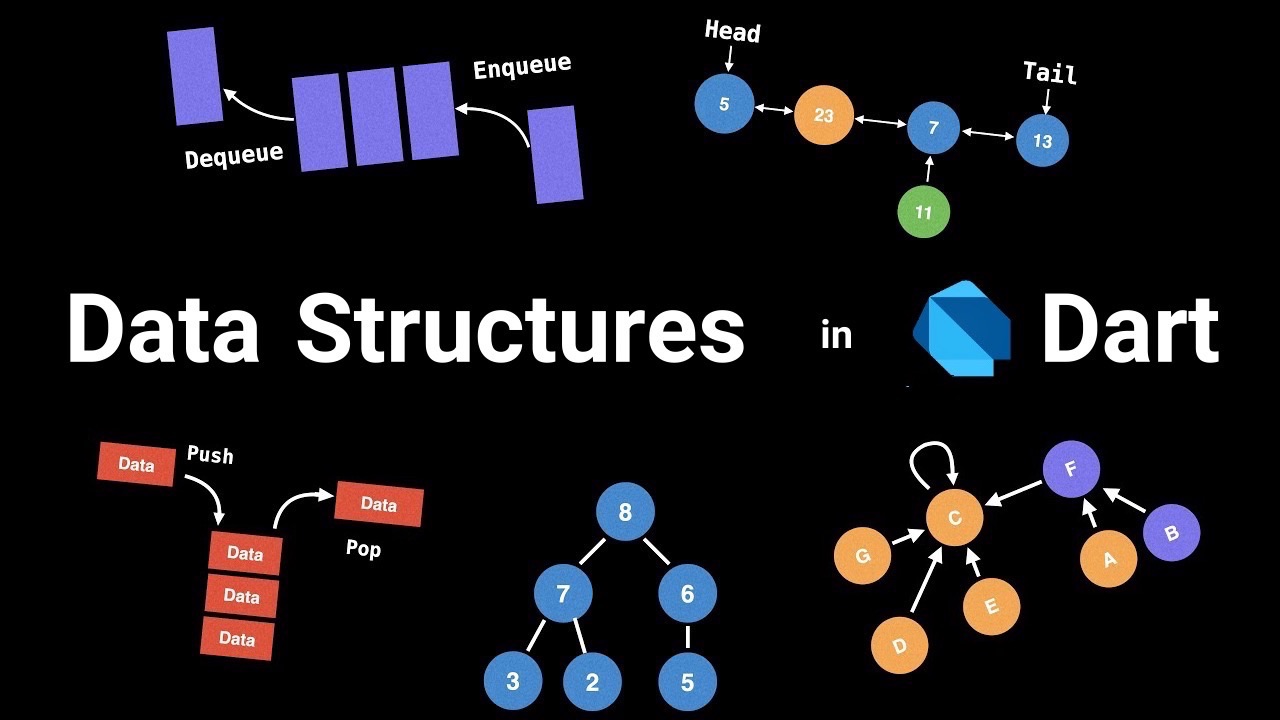 The most important Data structures explained in code for cracking the coding interview. Understand and learn how to implement them. Crack the interview
The most important Data structures explained in code for cracking the coding interview. Understand and learn how to implement them. Crack the interview
180. Why the Gaming Chip Shortage in the Gaming Industry is not Game Over
 The global chip shortage has taken the gaming industry by storm, as it is one of the biggest industries most affected, and the resupply of consoles can last unt
The global chip shortage has taken the gaming industry by storm, as it is one of the biggest industries most affected, and the resupply of consoles can last unt
181. How to Use Appsmith, Airtable, and Notion to Build a Video Sorting Tool
 According to Forbes, 82% of content generated this year is likely to be video.
According to Forbes, 82% of content generated this year is likely to be video.
182. Why Data Anomalies are More Important Than You Think
 It is easy to be annoyed by strange anomalies when they are sighted within otherwise clean (or perhaps not-quite-so-clean) datasets. This annoyance is immediately followed by eagerness to filter them out and move on. Even though having clean, well-curated datasets is an important step in the process of creating robust models, one should resist the urge to purge all anomalies immediately — in doing so, there is a real risk of throwing away valuable insights that could lead to significant improvements in your models, products, or even business processes.
It is easy to be annoyed by strange anomalies when they are sighted within otherwise clean (or perhaps not-quite-so-clean) datasets. This annoyance is immediately followed by eagerness to filter them out and move on. Even though having clean, well-curated datasets is an important step in the process of creating robust models, one should resist the urge to purge all anomalies immediately — in doing so, there is a real risk of throwing away valuable insights that could lead to significant improvements in your models, products, or even business processes.
183. Why Home Media Servers Are Worth Your Time
 Files are getting larger and space for your favorite content can be at a premium. Getting your own server can make storing data so much easier.
Files are getting larger and space for your favorite content can be at a premium. Getting your own server can make storing data so much easier.
184. Why Data Privacy is Important for Users in the Web3 Ecosystem
 Interview discussing why data privacy is important for users in the web3 ecosystem
Interview discussing why data privacy is important for users in the web3 ecosystem
185. How to Use Different Data Visualizations in the Grafana Dashboard
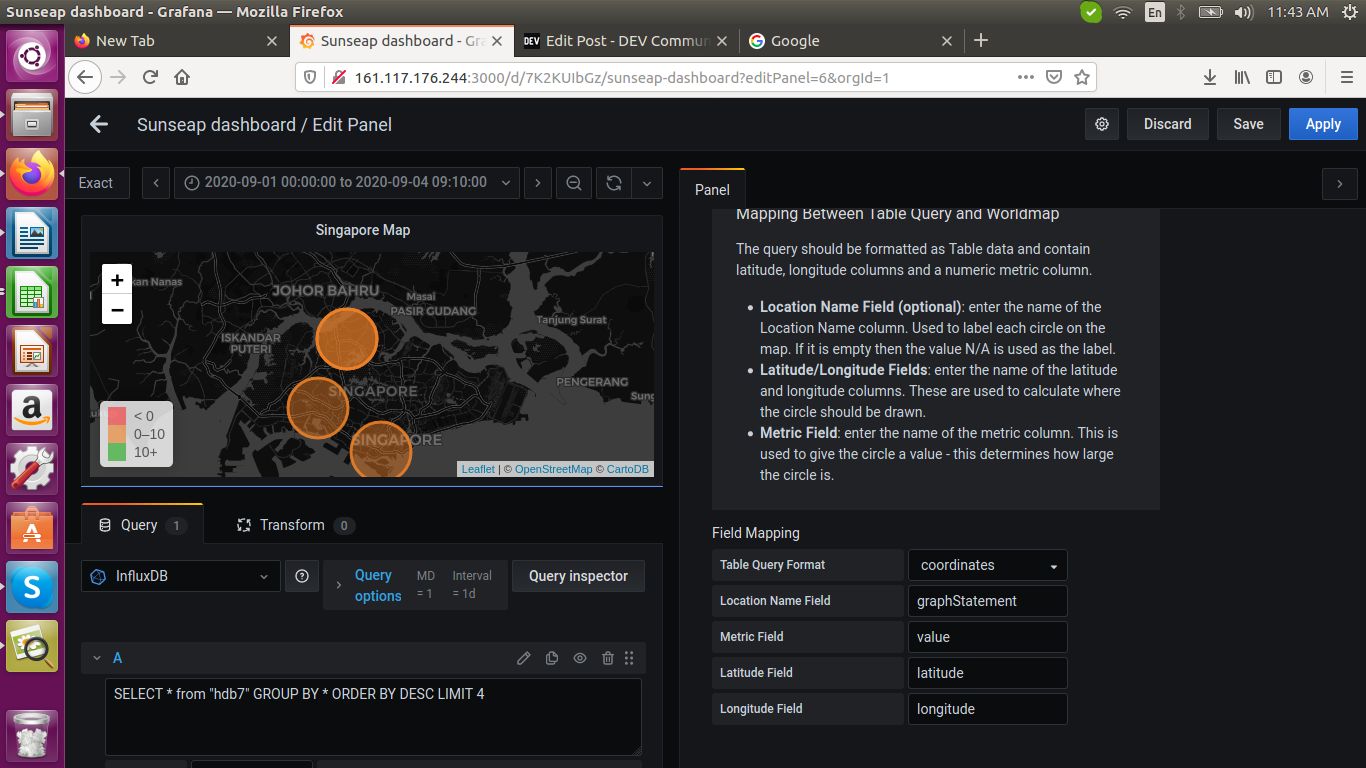 In this post, we will see how to use different visualizations, like the simple graph, pie chart, world map panel in the grafana dashboard by writing queries in Influx query language
In this post, we will see how to use different visualizations, like the simple graph, pie chart, world map panel in the grafana dashboard by writing queries in Influx query language
186. Why visualizations in Health don’t work
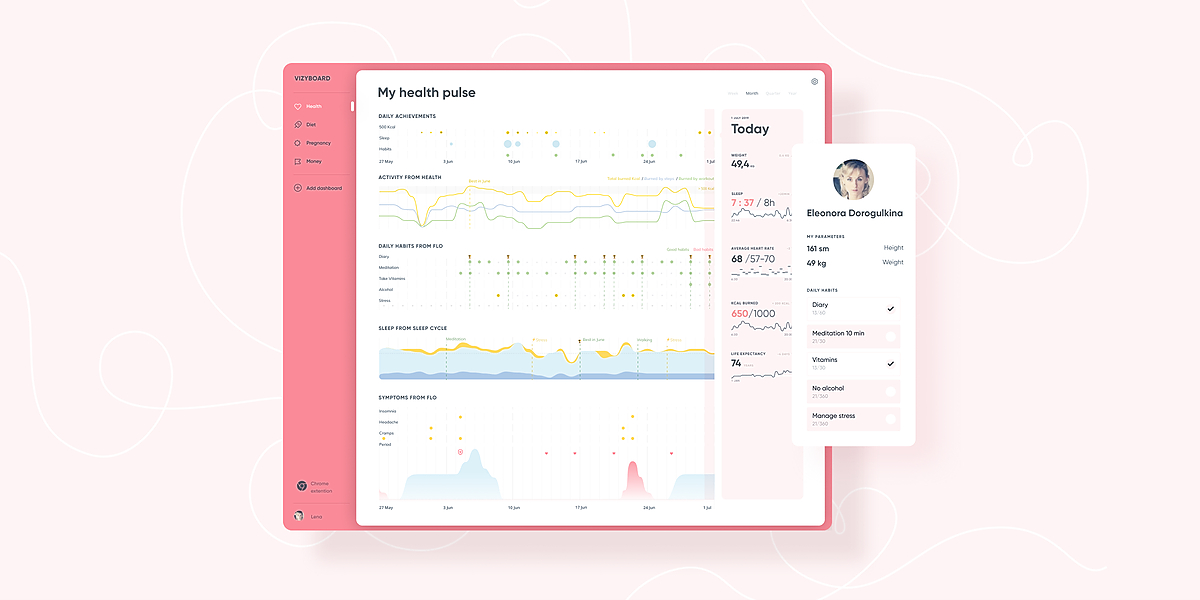 Visualizations in the most favorite health apps don’t have enough comparing and exploring possibilities.
Visualizations in the most favorite health apps don’t have enough comparing and exploring possibilities.
187. How to Make the Most of Playwright After the Latest Updates
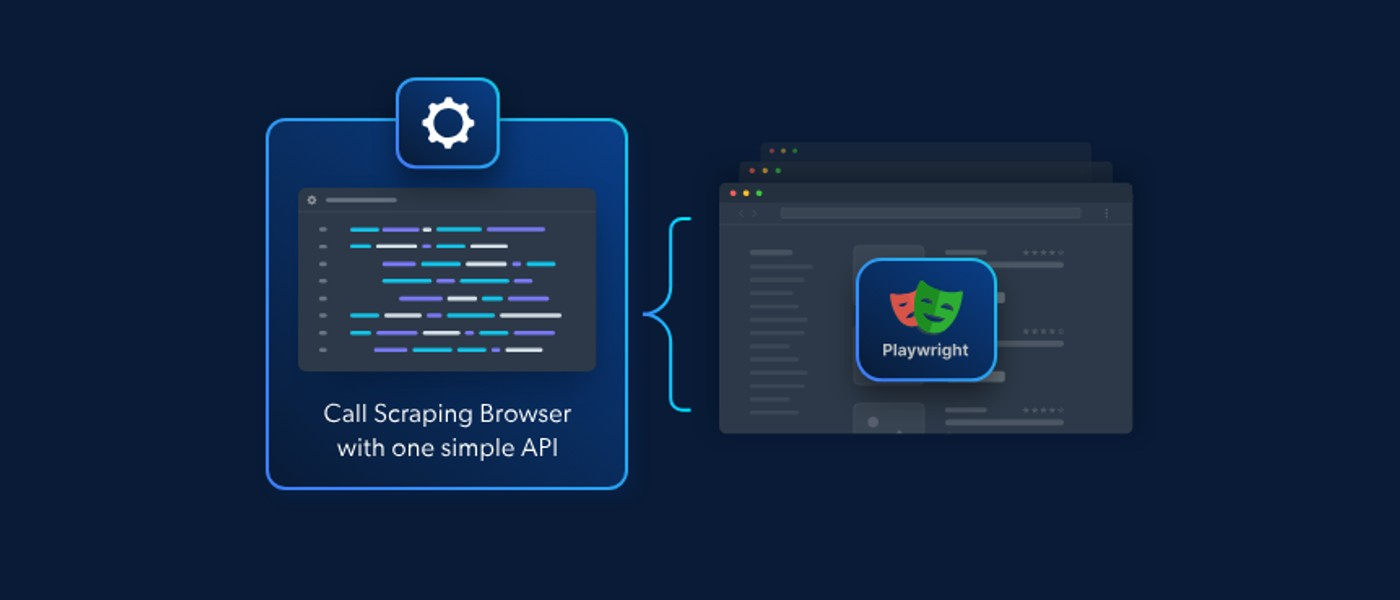 Playwright is the rock star of browser automation libraries, and just like Santa Claus delivers presents on Christmas Eve... Learn more about the latest update.
Playwright is the rock star of browser automation libraries, and just like Santa Claus delivers presents on Christmas Eve... Learn more about the latest update.
188. How The Metaverse Relies on The Data Economy
 The Metaverse isn't just built on the Data Economy, the Data Economy is the Metaverse.
The Metaverse isn't just built on the Data Economy, the Data Economy is the Metaverse.
189. Building a Propensity Model to Target Users Better in Marketing Campaigns
 Propensity model to figure out the likelihood of a person buying a product on their return visit.
We need to identify the probability to convert for each user.
Propensity model to figure out the likelihood of a person buying a product on their return visit.
We need to identify the probability to convert for each user.
190. Single Image 3D Scene Reconstruction: A Review of Recent Advances
 Take a deep dive into 3-D computer vision and explore the transition from 2D to 3D environments.
Take a deep dive into 3-D computer vision and explore the transition from 2D to 3D environments.
191. Introduction 5 Different Types of Text Annotation in NLP
 Natural language processing (NLP) is one of the biggest fields of AI development. Numerous NLP solutions like chatbots, automatic speech recognition, and sentiment analysis programs can improve efficiency and productivity in various businesses around the world.
Natural language processing (NLP) is one of the biggest fields of AI development. Numerous NLP solutions like chatbots, automatic speech recognition, and sentiment analysis programs can improve efficiency and productivity in various businesses around the world.
192. Hadoop for Hoops: Explore the Whole Ecosystem and to Know How It Really Works
 Technological evolution has changed the landscape, everything which we feel and hear today is revolving around some of the modern technology. This technology involves Artificial Intelligence, big data, cloud computing, data science, and much more, which has changed the landscape to a great extent. To integrate this technology, many of the IT professionals are finding and implementing the trajectory of today's modern technologies.
Technological evolution has changed the landscape, everything which we feel and hear today is revolving around some of the modern technology. This technology involves Artificial Intelligence, big data, cloud computing, data science, and much more, which has changed the landscape to a great extent. To integrate this technology, many of the IT professionals are finding and implementing the trajectory of today's modern technologies.
193. Everyone in AI Loves Synthetic Data—But No One Can Agree on What It Is
 Understand the 4 types of synthetic data—Imputation, User Creation, Insights Modeling, and Manufactured Outcomes—to enhance AI, analytics, and market research
Understand the 4 types of synthetic data—Imputation, User Creation, Insights Modeling, and Manufactured Outcomes—to enhance AI, analytics, and market research
194. How to Implement Digital Twin Architecture
 What technologies are behind the digital twin and how to reasonably approach its creation? Discover a detailed explanation in this article.
.
What technologies are behind the digital twin and how to reasonably approach its creation? Discover a detailed explanation in this article.
.
195. Are freelance developers different?
 Rise of the contract coder
Rise of the contract coder
196. A Step-by-Step Guide to Failing a Data Science Project
 As posited by Lev Tolstoy in his seminal work, Anna Karenina: “Happy families are all alike; every unhappy family is unhappy in its own way.” Likewise, all successful data science projects go through a very similar building process, while there are tons of different ways to fail a data science project. However, I’ve decided to prepare a detailed guide aimed at data scientists who want to make sure that their project will be a 100% disaster.
As posited by Lev Tolstoy in his seminal work, Anna Karenina: “Happy families are all alike; every unhappy family is unhappy in its own way.” Likewise, all successful data science projects go through a very similar building process, while there are tons of different ways to fail a data science project. However, I’ve decided to prepare a detailed guide aimed at data scientists who want to make sure that their project will be a 100% disaster.
197. COVID-19: Perceived Spread vs. True Spread in China, Italy and the US
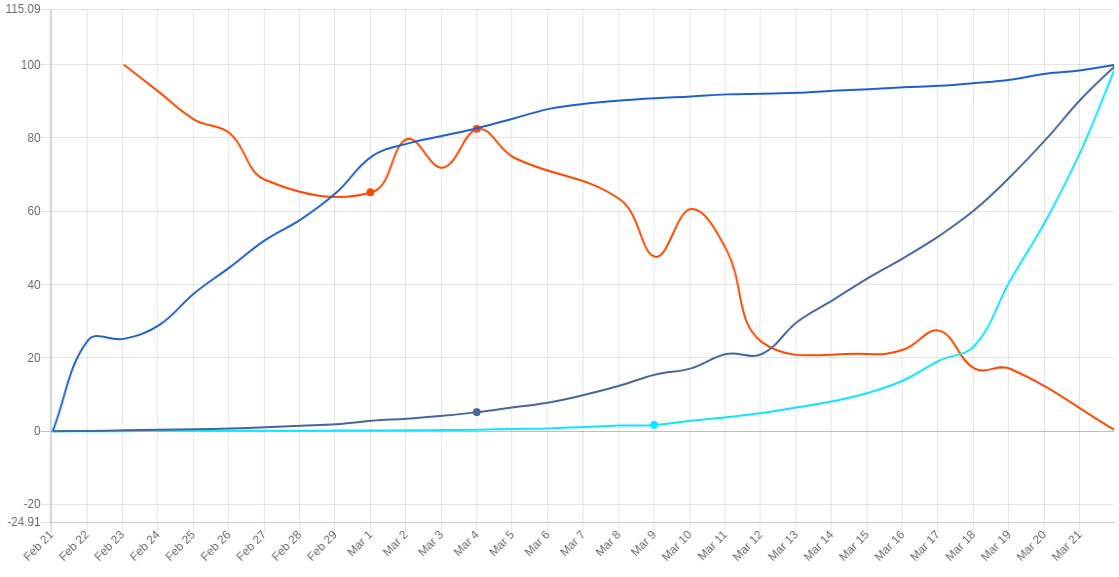 Here at TimeNet, we’re building a large time series database with the primary aim of benefitting society through access to data. In this post we’ll study different time series representing both the true, and the perceived spread of the coronavirus (COVID-19) pandemic. Daily COVID-19 numbers are currently available on TimeNet.cloud for many countries. We’re expanding these datasets with further variables measuring how we (people) perceive the significance of the pandemic. We use stock market movements and internet search trends to quantify the virus’s perceived spread.
Here at TimeNet, we’re building a large time series database with the primary aim of benefitting society through access to data. In this post we’ll study different time series representing both the true, and the perceived spread of the coronavirus (COVID-19) pandemic. Daily COVID-19 numbers are currently available on TimeNet.cloud for many countries. We’re expanding these datasets with further variables measuring how we (people) perceive the significance of the pandemic. We use stock market movements and internet search trends to quantify the virus’s perceived spread.
198. Data Gathering Methods: How to Crawl, Scrape, and Parse Data Online
 The internet is a treasure trove of valuable information. Read this article to find out how web crawling, scraping, and parsing can help you.
The internet is a treasure trove of valuable information. Read this article to find out how web crawling, scraping, and parsing can help you.
199. Data Science Teams are Doing it Wrong: Putting Technology Ahead of People
 Data Science and ML have become competitive differentiator for organizations across industries. But a large number of ML models fail to go into production. Why?
Data Science and ML have become competitive differentiator for organizations across industries. But a large number of ML models fail to go into production. Why?
200. 10 FinTech Trends in 2021 [Part II]
 You can read the first part of this article here. For those who for some reason don’t like to follow the links, let me remind you briefly: in the first part, we made a retrospective of fintech trends in 2020 and delved into the first 5 trends in 2021.
You can read the first part of this article here. For those who for some reason don’t like to follow the links, let me remind you briefly: in the first part, we made a retrospective of fintech trends in 2020 and delved into the first 5 trends in 2021.
201. The Ideal PRD for Web Analytics: Saying Goodbye to Google Analytics
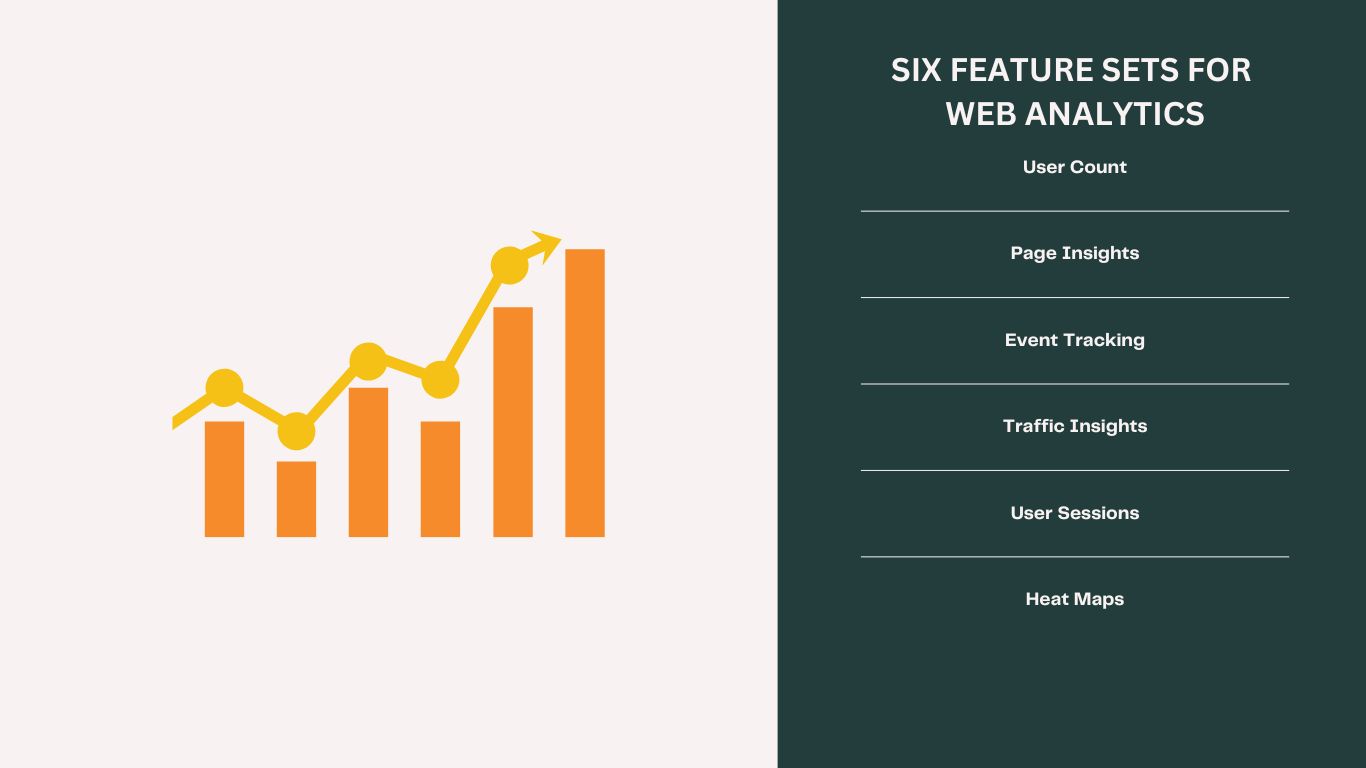 Basis my experience of using Google Analytics, Heap & FullStory, I think no one does a perfect job. Here's an ideal PRD for Web Analytics
Basis my experience of using Google Analytics, Heap & FullStory, I think no one does a perfect job. Here's an ideal PRD for Web Analytics
202. Migrate Data from S3 to Snowball
 In this article, I will show you how to migrate data from S3 to Snowball.
In this article, I will show you how to migrate data from S3 to Snowball.
203. The Importance Of On-chain Analysis
 A look at the importance of on-chain anlysis
A look at the importance of on-chain anlysis
204. Business Intelligence in microservices: improving performance
 Do you know why microservice design is so popular within the development of BI tools? The answer is clear: it helps to develop scalable and flexible solutions. But microservice architecture has a great drawback. Its performance usually requires great improvements.
Do you know why microservice design is so popular within the development of BI tools? The answer is clear: it helps to develop scalable and flexible solutions. But microservice architecture has a great drawback. Its performance usually requires great improvements.
205. Get ChatGPT to Focus on Coding on the Right APIs With Gptdoc Strings
 A new way to focus ChatGPT coding sessions on the APIs you want to use.
A new way to focus ChatGPT coding sessions on the APIs you want to use.
206. Langchain: Explained and Getting Started
 Langchain is a crucial component for developing LLM models. It helps in orchestration and act as building block
Langchain is a crucial component for developing LLM models. It helps in orchestration and act as building block
207. 10 Best African Language Datasets for Data Science Projects
 A list of African language datasets from across the web that can be used in numerous NLP tasks.
A list of African language datasets from across the web that can be used in numerous NLP tasks.
208. 9 Best Data Integration Software in 2022

209. How Data Teams Can Benefit From Running Like a Product Team
 Product teams have a lot of great practices that data teams would benefit from adopting. Namely: user-centricity and proactivity.
Product teams have a lot of great practices that data teams would benefit from adopting. Namely: user-centricity and proactivity.
210. Twitter Sentiment Analysis for the 2019 Lok Sabha Elections
 Introduction
Introduction
211. Unliked: Facebook’s Reign Could End
 Facebook shares went tumbling following the news after a ‘sell’ recommendation from Michael Levine of Pivotal Research Group. Levine cited concerns over Facebook’s Ad revenue as well as ongoing regulatory risks.
Facebook shares went tumbling following the news after a ‘sell’ recommendation from Michael Levine of Pivotal Research Group. Levine cited concerns over Facebook’s Ad revenue as well as ongoing regulatory risks.
212. How to Create World Leading Databases
 Jason Repp is the SVP of HarperDB, a world-leading database and development platform that is leading the charge in terms of performance, flexibility, and ease.
Jason Repp is the SVP of HarperDB, a world-leading database and development platform that is leading the charge in terms of performance, flexibility, and ease.
213. The Power State of Dark Data.
 Have you ever heard of “Dark Data”?
Have you ever heard of “Dark Data”?
214. The Usefulness Of Data Science In Law Enforcement
 Law enforcement agencies are not new to the data and its usage, but with the advancement in technology, Data science in law enforcement has become a need.
Law enforcement agencies are not new to the data and its usage, but with the advancement in technology, Data science in law enforcement has become a need.
215. 8 Crucial Tips for Hardening PostgreSQL 14.4 servers in 2022
 As of July 13th, 2022, there are 135 security flaws reported to the CVE database. Here are 8 essential measures you can take to protect your PostgreSQL server.
As of July 13th, 2022, there are 135 security flaws reported to the CVE database. Here are 8 essential measures you can take to protect your PostgreSQL server.
216. An Introduction to Automation in Vision AI
 Levels of Annotation Automation
Levels of Annotation Automation
217. How to Use DAX Studio to Retrieve All Measures in Power BI
 Using DAX Studio to retrieve all measures from a Power BI file is a straightforward process that provides valuable insights.
Using DAX Studio to retrieve all measures from a Power BI file is a straightforward process that provides valuable insights.
218. Why Databases and SQL Matter: The Pillars of Modern App Development
 As a beginner, you could be intrigued by the need for relational databases and SQL in software development. This article explains why databases are needed.
As a beginner, you could be intrigued by the need for relational databases and SQL in software development. This article explains why databases are needed.
219. The Future of the Internet Through the Web 3.0 Lens
 Jules Verne, John Brunner, Arthur Clarke, William Gibson, George Orwell — it’s a short list of writers who predicted the future in their books. They’ve written about social and technical changes that will take place in human society. Here we are, facing those changes good or bad.
Jules Verne, John Brunner, Arthur Clarke, William Gibson, George Orwell — it’s a short list of writers who predicted the future in their books. They’ve written about social and technical changes that will take place in human society. Here we are, facing those changes good or bad.
220. Context Matters in Semantic Ambiguity
 If we assume all items in the list above have the same semantic value, what is it exactly?
If we assume all items in the list above have the same semantic value, what is it exactly?
221. Decentralized Storage: Confronting the Challenges
 Decentralized storage is still far from mature. Three key obstacles - technical, regulatory and adoption - currently stand in its way.
Decentralized storage is still far from mature. Three key obstacles - technical, regulatory and adoption - currently stand in its way.
222. Data Playgrounds are The Cure for Slow and Inefficient DataOps
 Companies struggle with their DataOps due to a flawed, code-centric, and linear workflow. To succeed, they must build data playgrounds, not mere pipelines.
Companies struggle with their DataOps due to a flawed, code-centric, and linear workflow. To succeed, they must build data playgrounds, not mere pipelines.
223. Digital Public Infrastructure: Transforming 15-Minute Smart City Governance
 Digital Public Infrastructure (DPI) is like the digital ID to rule them all — over people, places & purchases to power a social credit system: perspective
Digital Public Infrastructure (DPI) is like the digital ID to rule them all — over people, places & purchases to power a social credit system: perspective
224. How Latin American Startups Can Make Their Own User Data Their Growth Superpower
 Investors are increasingly cautious when contributing to the growth of startups through personalized support. So, what can founders do about it?
Investors are increasingly cautious when contributing to the growth of startups through personalized support. So, what can founders do about it?
225. How Do You Hack Data Structures and Algorithms? Teach Us Sensei!
 Software Engineers are always on the lookout for better, more efficient ways to solve problems.
Software Engineers are always on the lookout for better, more efficient ways to solve problems.
226. Why Use Pandas? An Introductory Guide for Beginners
 Pandas is a powerful and popular library for working with data in Python. It provides tools for handling and manipulating large and complex datasets.
Pandas is a powerful and popular library for working with data in Python. It provides tools for handling and manipulating large and complex datasets.
227. Think You Know Why Google Acquired Fitbit? Think Again!
 There's more than meets the eye when it comes to Google's acquisition of Fitbit. Read on to learn more.
There's more than meets the eye when it comes to Google's acquisition of Fitbit. Read on to learn more.
228. How to Fetch Data from APIs Using useEffect React Hook
 In this article, we will take a look at useEffect React hook to fetch data from an API. We will create a sample React application to pull data from the provider and use it in our application.
In this article, we will take a look at useEffect React hook to fetch data from an API. We will create a sample React application to pull data from the provider and use it in our application.
229. Decoding MySQL EXPLAIN Query Results for Better Performance
 Understanding MySQL explains query output is essential to optimize the query. EXPLAIN is good tool to analyze your query.
Understanding MySQL explains query output is essential to optimize the query. EXPLAIN is good tool to analyze your query.
230. What Apple And Spotify Know About Me
 Unsurprisingly, the data that our apps have collected about us is both impressive and concerning, though it can be very interesting to review and explore it.
Unsurprisingly, the data that our apps have collected about us is both impressive and concerning, though it can be very interesting to review and explore it.
231. Not data-driven: purpose-driven and data-assisted

232. SocialFi — Social Networks on the Blockchain & What to Expect From Web 3
 How do social networks of the future differ from the usual ones, and what projects to expect in 2023.
How do social networks of the future differ from the usual ones, and what projects to expect in 2023.
233. Data Engineering Tools for Geospatial Data
 Location-based information makes the field of geospatial analytics so popular today. Collecting useful data requires some unique tools covered in this blog.
Location-based information makes the field of geospatial analytics so popular today. Collecting useful data requires some unique tools covered in this blog.
234. What is Data Analytics and How It Can Be Used

235. SubQuery to Make Blockchain Data Easily Accessible on the Cosmos Blockchain
 SubQuery is a blockchain developer toolkit that allows for web3 infrastructure through a custom open-source API between data and decentralized applications.
SubQuery is a blockchain developer toolkit that allows for web3 infrastructure through a custom open-source API between data and decentralized applications.
236. How to Achieve Optimal Business Results with Public Web Data
 Public web data unlocks many opportunities for businesses that can harness it. Here’s how to prepare for working with this type of data.
Public web data unlocks many opportunities for businesses that can harness it. Here’s how to prepare for working with this type of data.
237. How to Monetize User Data Like Reddit (Without Being Sketchy)
 Dive into Reddit's $60M data deal with Google, the ethics of data monetization, and how businesses can fairly profit with zero-party data licensing.
Dive into Reddit's $60M data deal with Google, the ethics of data monetization, and how businesses can fairly profit with zero-party data licensing.
238. 4 Tips To Become A Successful Entry-Level Data Analyst
 Companies across every industry rely on big data to make strategic decisions about their business, which is why data analyst roles are constantly in demand.
Companies across every industry rely on big data to make strategic decisions about their business, which is why data analyst roles are constantly in demand.
239. The Operational Analytics Loop: From Raw Data to Models to Apps, and Back Again
 Over the next decade or so, we’ll see an incredible transformation in how companies collect, process, transform and use data. Though it’s tired to trot out Marc Andreessen’s “software will eat the world” quote, I have always believed in the corollary: “Software practices will eat the business.” This is starting with data practices.
Over the next decade or so, we’ll see an incredible transformation in how companies collect, process, transform and use data. Though it’s tired to trot out Marc Andreessen’s “software will eat the world” quote, I have always believed in the corollary: “Software practices will eat the business.” This is starting with data practices.
240. What I Learned When I Changed the UX Research System at my Company
 SUS scale and why you should try to use it in your UX research.
SUS scale and why you should try to use it in your UX research.
241. How to Create A Funnel Chart In R
 Funnel Chart in R, A funnel chart is mainly used for demonstrates the flow of users through a business or sales process.
Funnel Chart in R, A funnel chart is mainly used for demonstrates the flow of users through a business or sales process.
242. Why Are the New AI Agents Choosing Markdown Over HTML?
 Let's find out why AI agents convert HTML to Markdown to cut token usage by up to 99%!
Let's find out why AI agents convert HTML to Markdown to cut token usage by up to 99%!
243. Utilizing Web Scraping and Alternative Data in Financial Markets
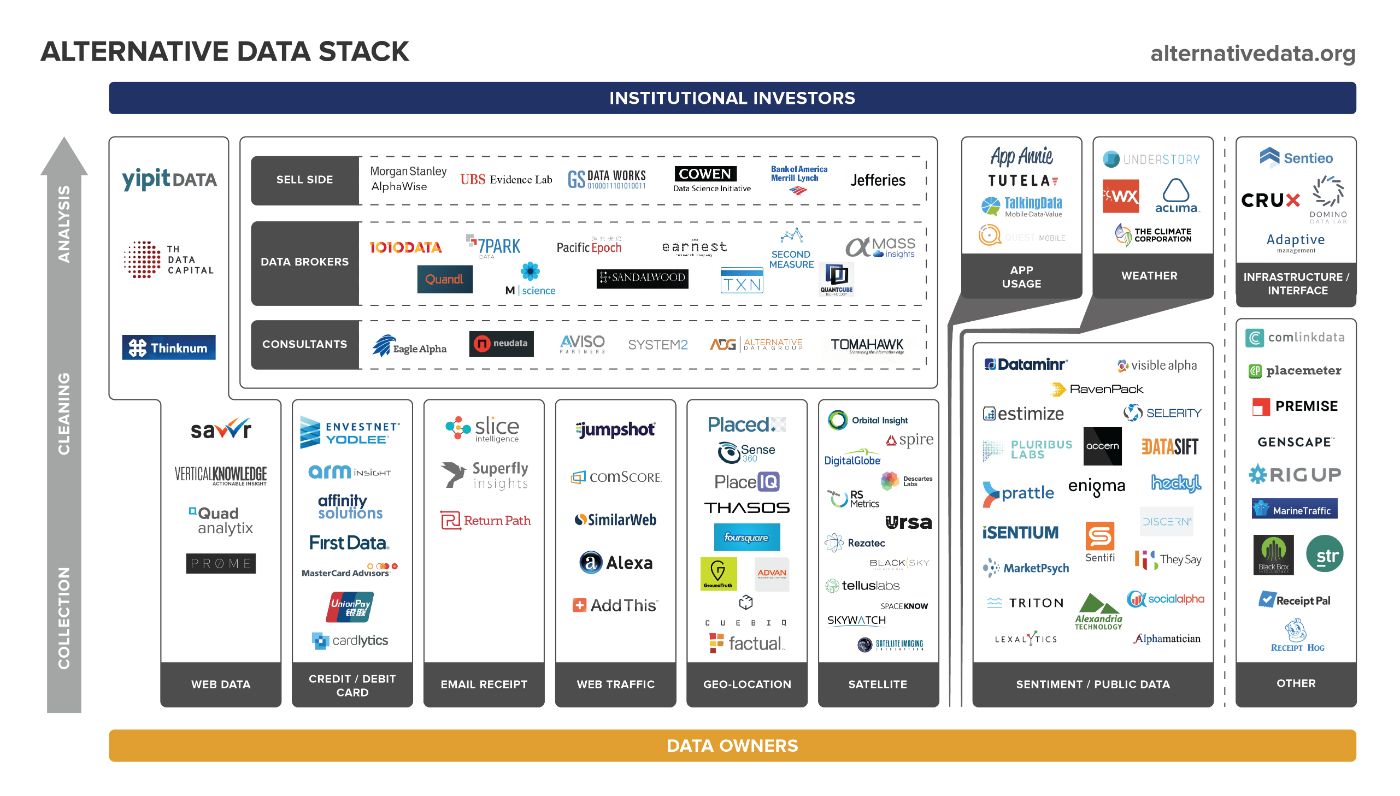 What are alternative data and how to use web scraping to build datasets for financial markets?
What are alternative data and how to use web scraping to build datasets for financial markets?
244. Top 13 Data Visualization Tools for 2023 and Beyond
 With the enormity of data, data visualization has become the most sought-after method to depict huge numbers in simpler versions of maps or graphs.
With the enormity of data, data visualization has become the most sought-after method to depict huge numbers in simpler versions of maps or graphs.
245. Data-Driven Advertising and Its Impact On Our Privacy-Driven World
 Do we actually need so much data to do effective marketing?
Do we actually need so much data to do effective marketing?
246. The Ethics of Data Collection and Privacy in the Tech Industry
 The term “Data Ethics“ is relative, and refers to the best practices, rules, and laws that seek to preserve the rights of users over their data.
The term “Data Ethics“ is relative, and refers to the best practices, rules, and laws that seek to preserve the rights of users over their data.
247. The Emerging Data Engineering Trends You Should Check Out In 2024
 Integrating data engineering with AI has led to the popularity of modern data integration and the expertise required.
Integrating data engineering with AI has led to the popularity of modern data integration and the expertise required.
248. Merging Datasets from Different Timescales
 One of the trickiest situations in machine learning is when you have to deal with datasets coming from different time scales.
One of the trickiest situations in machine learning is when you have to deal with datasets coming from different time scales.
249. What Qualifies You To Be A Cybersecurity Professional?
 Data breaches and ransomware attacks are getting more common. If you want to get in on this industry as a cybersecurity professional, you need qualifications.
Data breaches and ransomware attacks are getting more common. If you want to get in on this industry as a cybersecurity professional, you need qualifications.
250. 693 Stories To Learn About Data
 Learn everything you need to know about Data via these 693 free HackerNoon stories.
Learn everything you need to know about Data via these 693 free HackerNoon stories.
251. 5 Things to Watch Out for When Implementing Tableau BI

252. Executing a T-test in Python
 In today’s data-driven world, data is generated and consumed on a daily basis. All this data holds countless hidden ideas and information that can be exhausting
In today’s data-driven world, data is generated and consumed on a daily basis. All this data holds countless hidden ideas and information that can be exhausting
253. The Growth Marketing Writing Contest: Round 1 Results Announced!
 Growth marketers - the wait is OVER. The first round results announcement of the Growth Marketing Writing Contest is now LIVE!
Growth marketers - the wait is OVER. The first round results announcement of the Growth Marketing Writing Contest is now LIVE!
254. My Weird Career Transition From MBA to Data Science
 Yes you read it correctly! I am calling my transition from being an MBA to being the Analytics Manager in a well known consumer retail brand a "WEIRD" one. And why do I say that? Because during my 5 year journey in data science, I have had the opportunity to work with a lot of business stakeholders like marketing head, brand managers, sales heads etc. and many a times they have asked me about my educational background. I would like to think that they asked this because of my ability to present the solutions keeping the business context and execution feasibility in mind. Well, the reason for asking this might be different for every individual, when I tell them that I am an MBA, their reply has always been the same, which is "What made you choose a technical career path after pursuing MBA?" And hence I decided to write this post to share my thoughts over 2 things:
Yes you read it correctly! I am calling my transition from being an MBA to being the Analytics Manager in a well known consumer retail brand a "WEIRD" one. And why do I say that? Because during my 5 year journey in data science, I have had the opportunity to work with a lot of business stakeholders like marketing head, brand managers, sales heads etc. and many a times they have asked me about my educational background. I would like to think that they asked this because of my ability to present the solutions keeping the business context and execution feasibility in mind. Well, the reason for asking this might be different for every individual, when I tell them that I am an MBA, their reply has always been the same, which is "What made you choose a technical career path after pursuing MBA?" And hence I decided to write this post to share my thoughts over 2 things:
255. Predict Customer Churn With Machine Learning, Data Science and Survival Analysis
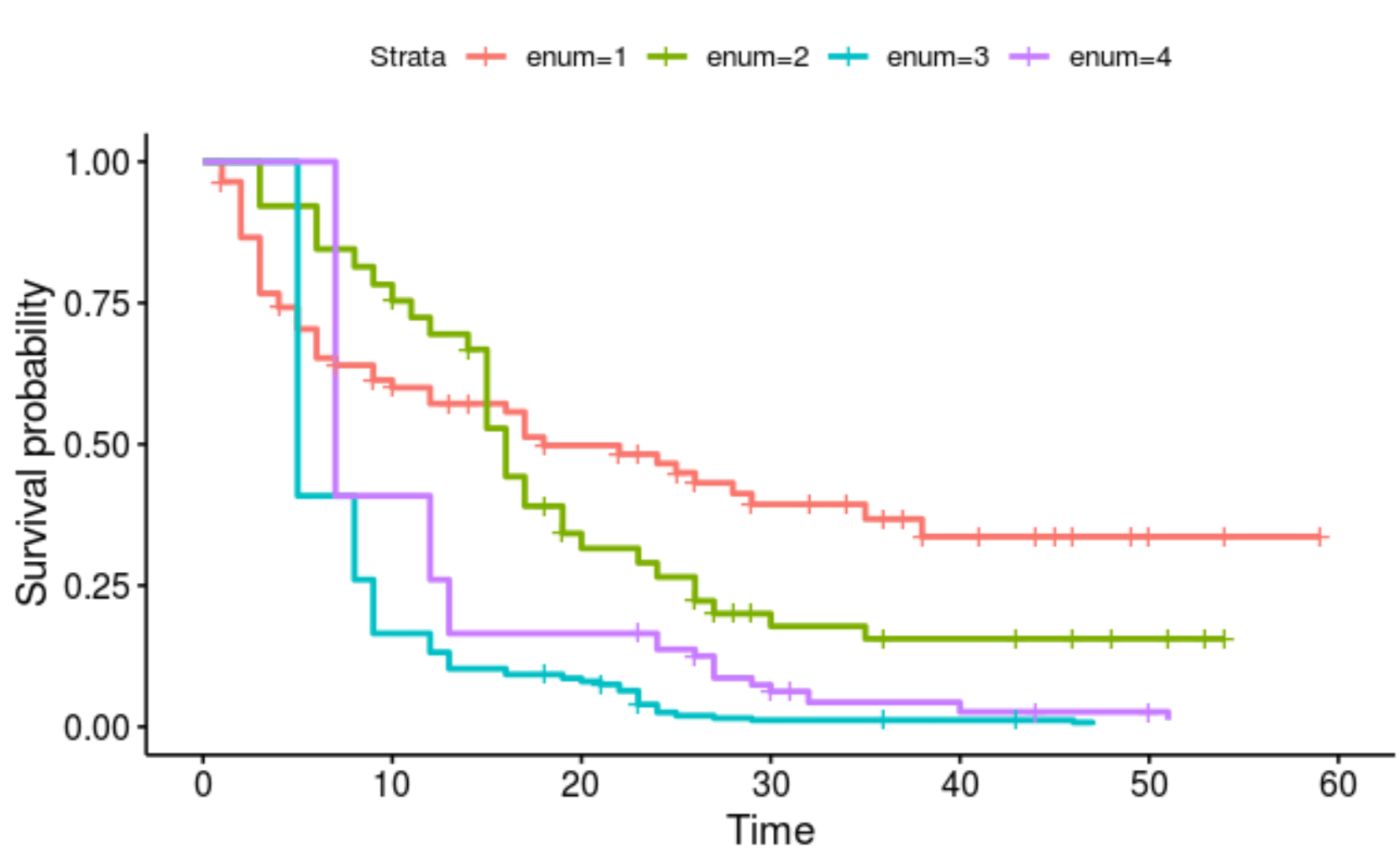 Predicting customer churn is very important because businesses have limited resources and cannot afford to lose customers if they want to stay profitable.
Predicting customer churn is very important because businesses have limited resources and cannot afford to lose customers if they want to stay profitable.
256. A New Netflix Style Reality Show for People Who Love Data
 Seven data professionals gear up to analyze and visualize one of the largest and robust datasets out there to win the title - The Iron Analyst!
Seven data professionals gear up to analyze and visualize one of the largest and robust datasets out there to win the title - The Iron Analyst!
257. How to Choose the Right Hyper-V Backup Strategy
 This post discusses the main data protection strategies that can help you keep your Hyper-V data secure at all times.
This post discusses the main data protection strategies that can help you keep your Hyper-V data secure at all times.
258. Top 3 Benefits of Insurance Data Analytics
 The Importance of data analytics and data-driven decisions across the board and in this case insurance data.
The Importance of data analytics and data-driven decisions across the board and in this case insurance data.
259. What is Web Data Collection?
 Everything you need to know to automate, optimize and streamline the data collection process in your organization!
Everything you need to know to automate, optimize and streamline the data collection process in your organization!
260. Daily Coding Problem: Next Biggest Number
 Finding the next biggest value in an array of integers
Finding the next biggest value in an array of integers
261. Tutorial: Swift and SwiftUI for Data Science iOS Development
 Swift and SwiftUI for Data Science
Swift and SwiftUI for Data Science
262. Have You Read Your Privacy Notice in Detail?
 Do you recall every company you have given consent to use your data as you browse a website or sign-up to a ‘free’ service? It's time we moved beyond consent
Do you recall every company you have given consent to use your data as you browse a website or sign-up to a ‘free’ service? It's time we moved beyond consent
263. How is Web Crawling Used in Data Science
 No-Code tools for collecting data for your Data Science project
No-Code tools for collecting data for your Data Science project
264. How a Data Scientist Sees a Deck of Cards

265. 5 Ways to Store Market Data: CSV, SQLite, Postgres, Mongo, Arctic
 What's the most efficient way to store market data? SQL or NoSQL? Let's compare 5 most common options and find out what is best.
What's the most efficient way to store market data? SQL or NoSQL? Let's compare 5 most common options and find out what is best.
266. The Black Market for Data is on the Rise
 Once the laughingstock of the Internet, hackers are now some of the most wanted criminals in the world.
Once the laughingstock of the Internet, hackers are now some of the most wanted criminals in the world.
267. Scraping with Selenium 101: The Big Hole on Data Scientists Toolset [Part 1]
 Usually forgotten in all Data Science masters and courses, Web Scraping is, in my honest opinion a basic tool in the Data Scientist toolset, as is the tool for getting and therefore using external data from your organization when public databases are not available.
Usually forgotten in all Data Science masters and courses, Web Scraping is, in my honest opinion a basic tool in the Data Scientist toolset, as is the tool for getting and therefore using external data from your organization when public databases are not available.
268. An Introduction to Data Connectors: Your First Step to Data Analytics
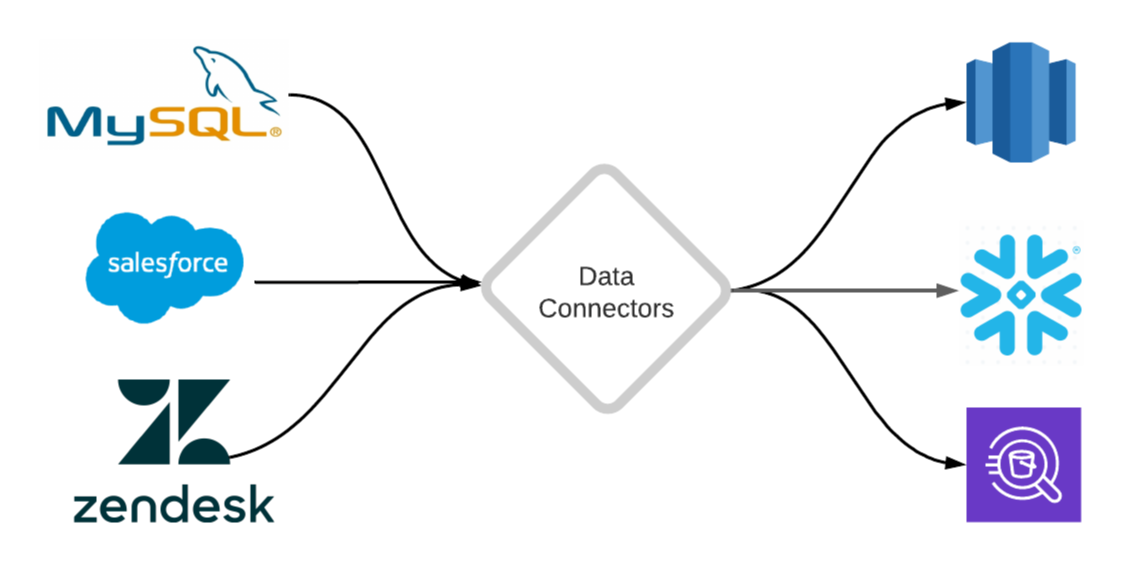 This post explains what a data connector is and provides a framework for building connectors that replicate data from different sources into your data warehouse
This post explains what a data connector is and provides a framework for building connectors that replicate data from different sources into your data warehouse
269. How to Drive Personalized Retail Offers with Vector Search
 Learn how vector search to drive results with customer promotions at a big-box retailer.
Learn how vector search to drive results with customer promotions at a big-box retailer.
270. 3 Ways You Can Build and Update Websites Using Data Pushes

Data is getting more and more accessible and is increasingly being used to inform the way businesses operate.
271. Machine Learning in Cybersecurity: 5 Real-Life Examples
 From real-time cybercrime mapping to penetration testing, machine learning has become a crucial part of cybersecurity. Here's how.
From real-time cybercrime mapping to penetration testing, machine learning has become a crucial part of cybersecurity. Here's how.
272. Are You Focusing on the Right Product Metrics?
 In this article, we'll delve into seven common mistakes that people often make when it comes to selecting and tracking product metrics.
In this article, we'll delve into seven common mistakes that people often make when it comes to selecting and tracking product metrics.
273. Data and Its Color
 I had the opportunity to speak with Bourgeois about her project, what she learned, and how others can use creative approaches to ask questions
I had the opportunity to speak with Bourgeois about her project, what she learned, and how others can use creative approaches to ask questions
274. What is Data-Centric AI?
 What makes GPT-3 and Dalle powerful is exactly the same thing: Data.
What makes GPT-3 and Dalle powerful is exactly the same thing: Data.
275. Developing, Packaging and Distributing a Python Library
 How to use new packaging standards with virtual environment tools — adapted from the official documentations of python.org and Pipenv
How to use new packaging standards with virtual environment tools — adapted from the official documentations of python.org and Pipenv
276. Sensor-based Control in Cobots: Its Opportunities and Challenges
 Introduction of the very basic formulation of the major sensor-servo problem, and then presenting its most common approaches like touch-based,
Introduction of the very basic formulation of the major sensor-servo problem, and then presenting its most common approaches like touch-based,
277. How The Graph Plans to Become the Data Layer for a $47 Billion Agentic AI Economy
 The Graph's 2026 roadmap targets AI agents, institutions, and DeFi with six modular data services on Horizon after processing 1.27 trillion queries.
The Graph's 2026 roadmap targets AI agents, institutions, and DeFi with six modular data services on Horizon after processing 1.27 trillion queries.
278. Getting High-Frequency Tennis Motion Data from Apple Watch [Part 2]
 Accruing real tennis motion data from Apple Watch and exploring insights, including acceleration, rotation, and more.
Accruing real tennis motion data from Apple Watch and exploring insights, including acceleration, rotation, and more.
279. HN Editor Picks: Top Tech Stories of March 2023
 Take a look at all the best HackerNoon stories, handpicked for your reading pleasure and education on trending tech topics.
Take a look at all the best HackerNoon stories, handpicked for your reading pleasure and education on trending tech topics.
280. Future of Marketing: How Data Science Predicts Consumer Behavior
 Gradually, as the post-pandemic phase arrived, one thing that helped marketers predict their consumer behavior was Data Science.
Gradually, as the post-pandemic phase arrived, one thing that helped marketers predict their consumer behavior was Data Science.
281. Four Novel Machine Learning Methods for Analyzing Blockchain Datasets
 Using machine learning to analyze blockchain datasets is a fascinating challenge. Beyond the incredible potential of uncovering unknown insights that help us understand the behavior of crypto-assets, blockchain datasets presents very unique challenges to a machine learning practitioner. Many of these challenges translate into major roadblocks for most traditional machine learning techniques. However, the rapid evolution of machine intelligence technologies has enabled the creation of novel machine learning methods that result very applicable to the analysis of blockchain datasets. At IntoTheBlock, we regularly experiment with these new methods to improve the efficiency of our market intelligence signals. Today, I would like to provide a brief overview of some novel ideas in the machine learning space that can yield interesting results in the analysis of blockchain data.
Using machine learning to analyze blockchain datasets is a fascinating challenge. Beyond the incredible potential of uncovering unknown insights that help us understand the behavior of crypto-assets, blockchain datasets presents very unique challenges to a machine learning practitioner. Many of these challenges translate into major roadblocks for most traditional machine learning techniques. However, the rapid evolution of machine intelligence technologies has enabled the creation of novel machine learning methods that result very applicable to the analysis of blockchain datasets. At IntoTheBlock, we regularly experiment with these new methods to improve the efficiency of our market intelligence signals. Today, I would like to provide a brief overview of some novel ideas in the machine learning space that can yield interesting results in the analysis of blockchain data.
282. How to Connect to Salesforce Data in AWS Glue Jobs Using JDBC
 Connect to Salesforce from AWS Glue jobs using the CData JDBC Driver hosted in Amazon S3.
Connect to Salesforce from AWS Glue jobs using the CData JDBC Driver hosted in Amazon S3.
283. How To Meaningfully Interpret COVID-19 Data
284. What’s Wrong With GraphQL?
 While GraphQL offers several benefits, there are some potential disadvantages and challenges to using it in C# to consider, before you decide to implement it.
While GraphQL offers several benefits, there are some potential disadvantages and challenges to using it in C# to consider, before you decide to implement it.
285. Data Lakes Are Crucial To Business Analytics and Big Data Processing
 While the term Data is in cognizance of business of all sizes even the most layman person is aware of the buzz and fuss around Data. So from Database to Data Warehouse and now this Data Lake, we have come a long way.
While the term Data is in cognizance of business of all sizes even the most layman person is aware of the buzz and fuss around Data. So from Database to Data Warehouse and now this Data Lake, we have come a long way.
286. Make Data-Driven Decisions With Power BI Consulting & Implementation
 Power BI offers a solution for businesses that need to manage large volumes of data. It's designed to help with even the heaviest data flows business have.
Power BI offers a solution for businesses that need to manage large volumes of data. It's designed to help with even the heaviest data flows business have.
287. Data Will Never Be Clean But You Can Make it Useful
 Understanding how to clean data is essential to ensure your data tells an accurate story
Understanding how to clean data is essential to ensure your data tells an accurate story
288. Understanding the 'Data is the New Oil' Analogy
 Earlier, we lived in industrial and post-industrial societies, and gas and oil were the only things of value. Now, it’s the age of information society and data has replaced petrol as the economy’s driving force. The reason is that with the help of Big Data, people significantly improve production efficiency and business economics. That’s true.
Earlier, we lived in industrial and post-industrial societies, and gas and oil were the only things of value. Now, it’s the age of information society and data has replaced petrol as the economy’s driving force. The reason is that with the help of Big Data, people significantly improve production efficiency and business economics. That’s true.
289. Hospital Websites are Giving Facebook Sensitive Information
 A tracking tool installed on many hospitals’ websites has been collecting patients’ sensitive health information—including details about their medical condition
A tracking tool installed on many hospitals’ websites has been collecting patients’ sensitive health information—including details about their medical condition
290. Stop Feeding the Algorithm: Creative Ways to Disconnect from Data-Hungry Platforms
 Learn how to reclaim your digital privacy with practical tips to reduce tracking, resist algorithms, and disconnect from data-hungry platforms.
Learn how to reclaim your digital privacy with practical tips to reduce tracking, resist algorithms, and disconnect from data-hungry platforms.
291. Facebook Has Been Receiving Your Financial Information From Tax Filing Websites
 Major tax filing services such as H&R Block, TaxAct, and TaxSlayer have been quietly transmitting sensitive financial information to Facebook...
Major tax filing services such as H&R Block, TaxAct, and TaxSlayer have been quietly transmitting sensitive financial information to Facebook...
292. Deep Dive into Data Apps with Streamlit
 Deep dive on building and deploying data apps with Streamlit
Deep dive on building and deploying data apps with Streamlit
293. Build a Live Dashboard with Materialize, Airbyte, MySQL and Redpanda/Kafka

294. How to Train Computer Vision Models Efficiently
 The starting point of building a successful computer vision application is the model. Computer vision model training can be time-consuming and challenging if one doesn’t have a background in data science. Nonetheless, it is a requirement for customized applications.
The starting point of building a successful computer vision application is the model. Computer vision model training can be time-consuming and challenging if one doesn’t have a background in data science. Nonetheless, it is a requirement for customized applications.
295. How to Think Like a Data Systems Engineer: The Questions That Save You Later
 Learn how engineers think about reliability, scalability, and maintainability—by asking the right questions early.
Learn how engineers think about reliability, scalability, and maintainability—by asking the right questions early.
296. A Beginner's Introduction to Database Backup Security
 With more companies collecting customer data than ever, database backups are key.
With more companies collecting customer data than ever, database backups are key.
297. Use Up-Sampling and Weights to Address Imbalance Data Problem
 Have you worked on machine learning classification problem in the real world? If so, you probably have some experience with imbalance data problem. Imbalance data means the classes we want to predict are disproportional. Classes that make up a large proportion of the data are called majority classes. Those that make up a smaller portion are minority classes. For example, we want to use machine learning models to capture credit card fraud, and fraudulent activities happens approximately 0.1% out of millions of transactions. The majority of regular transactions will impede the machine learning algorithm to identify patterns for the fraudulent activities.
Have you worked on machine learning classification problem in the real world? If so, you probably have some experience with imbalance data problem. Imbalance data means the classes we want to predict are disproportional. Classes that make up a large proportion of the data are called majority classes. Those that make up a smaller portion are minority classes. For example, we want to use machine learning models to capture credit card fraud, and fraudulent activities happens approximately 0.1% out of millions of transactions. The majority of regular transactions will impede the machine learning algorithm to identify patterns for the fraudulent activities.
298. Streamlining AI Data Collection with Bright Data’s Scraping Browser
 Streamlining AI data serves as a means to support companies needing extensive training data and capitalizing on building efficient models.
Streamlining AI data serves as a means to support companies needing extensive training data and capitalizing on building efficient models.
299. Join to Write Data Into Your First Decentralized Database
 The DB3 Network is a start-up project to build a decentralized, permissionless platform for programmable data processing.
The DB3 Network is a start-up project to build a decentralized, permissionless platform for programmable data processing.
300. How We Use dbt (Client) In Our Data Team
 Here is not really an article, but more some notes about how we use dbt in our team.
Here is not really an article, but more some notes about how we use dbt in our team.
301. We Built a Modern Data Stack for Startups
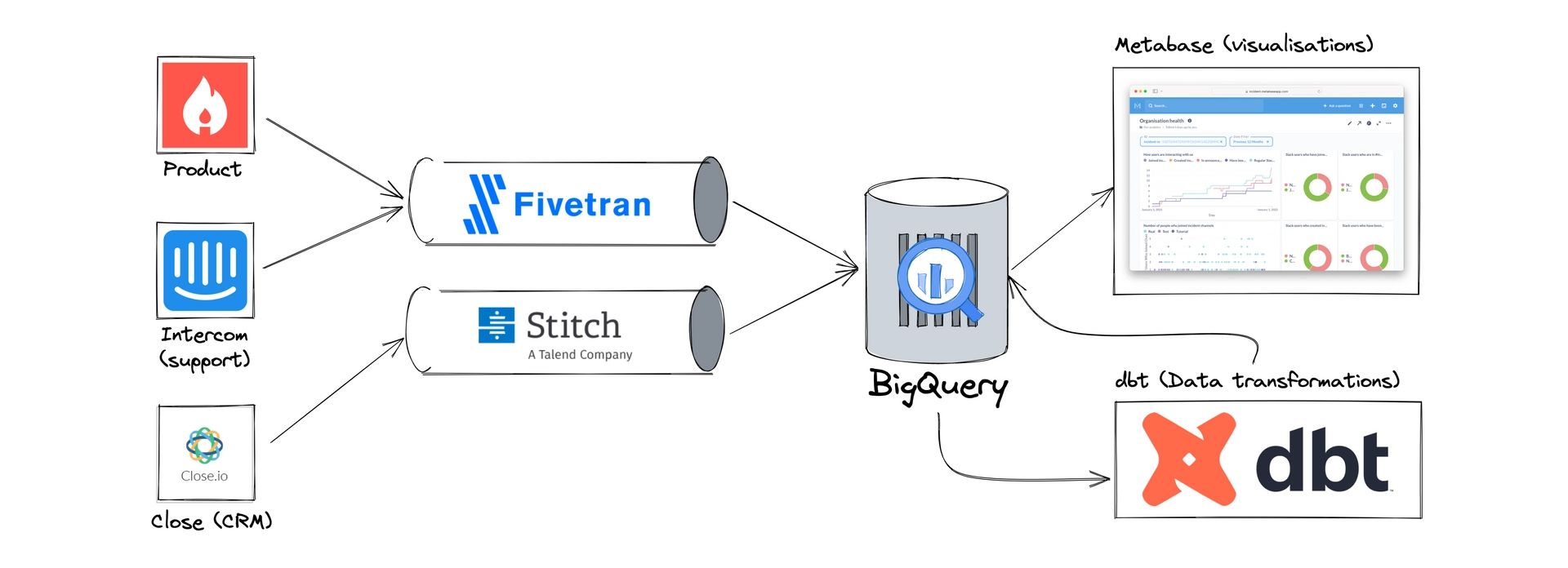 Here's how we built our data stack at incident.io. If you're a company that cares about data access for all, follow this guide and we guarantee great results.
Here's how we built our data stack at incident.io. If you're a company that cares about data access for all, follow this guide and we guarantee great results.
302. Data Lakehouses: The New Data Storage Model
 Data lakehouses are quickly replacing old storage options like data lakes and warehouses. Read on for the history and benefits of data lakehouses.
Data lakehouses are quickly replacing old storage options like data lakes and warehouses. Read on for the history and benefits of data lakehouses.
303. Here Are the Most Common Causes of Data Leakage in 2023: What You Should Know
 Discover the top culprits behind data leakage in 2023 and learn how to fortify your defenses. Stay informed and safeguard your valuable information today.
Discover the top culprits behind data leakage in 2023 and learn how to fortify your defenses. Stay informed and safeguard your valuable information today.
304. The hidden risk of ethics regulation
 Regulating the tech industry won’t fix its ethical problems, it might make them worse. Mike Monteiro has written the most compelling argument I have seen for regulation. Regulation would address many of the kinds of ethical risks that have made headlines recently. But I think it would leave many risks in place and introduce new risks — a more systemic risk, in fact — that in the long term would actually expose the public and the industry to more potential downside that it currently faces. Regulation at scale requires rules that stipulate what is ethical and what is not, in the case of the discussion of the ethics.
Regulating the tech industry won’t fix its ethical problems, it might make them worse. Mike Monteiro has written the most compelling argument I have seen for regulation. Regulation would address many of the kinds of ethical risks that have made headlines recently. But I think it would leave many risks in place and introduce new risks — a more systemic risk, in fact — that in the long term would actually expose the public and the industry to more potential downside that it currently faces. Regulation at scale requires rules that stipulate what is ethical and what is not, in the case of the discussion of the ethics.
305. How to Orchestrate Data for Machine Learning Pipelines
 I will propose a new technique, data orchestration, to optimize the data pipeline for machine learning.
I will propose a new technique, data orchestration, to optimize the data pipeline for machine learning.
306. Building the Next-Generation Data Lakehouse: 10X Performance
 How to connect various data sources easily and ensure high query performance.
How to connect various data sources easily and ensure high query performance.
307. The Five W's for Setting KPIs
 KPIs serve as the foundation for your data strategy, guiding you towards the metrics that matter.
KPIs serve as the foundation for your data strategy, guiding you towards the metrics that matter.
308. Quantum-resistant Encryption: Why You Urgently Need it
 The Second World War brought to the front burner the world of espionage, which is the precursor of cybersecurity, as is seen in the modern world. Technological advancements such as the quantum computer necessitate that we take the war against cybercrimes to another level.
The Second World War brought to the front burner the world of espionage, which is the precursor of cybersecurity, as is seen in the modern world. Technological advancements such as the quantum computer necessitate that we take the war against cybercrimes to another level.
309. The Best Options to Store Data and Keep it Safe Forever
 As technology evolved the options for storing the large amount of data have also changed. In this article we've discussed the terms Archiving and Backups.
As technology evolved the options for storing the large amount of data have also changed. In this article we've discussed the terms Archiving and Backups.
310. The Healthcare Revolution: How The Metaverse Can Transform Traditional Industries And Improve Them
 How new technology from the Metaverse and Web3 can help improve the healthcare industry by improving training, making better tools and making processes better.
How new technology from the Metaverse and Web3 can help improve the healthcare industry by improving training, making better tools and making processes better.
311. The Fastest Way to Become A Professional Data Analyst
 Sharyph, a tech writer, goes over how to become a professional data analyst.
Sharyph, a tech writer, goes over how to become a professional data analyst.
312. Data Labeling: A Comprehensive Guide
 This article offers a comprehensive guide to data labeling; covering types, challenges, and best practices for successful data labeling.
This article offers a comprehensive guide to data labeling; covering types, challenges, and best practices for successful data labeling.
313. 70 Stories To Learn About Statistics
 Learn everything you need to know about Statistics via these 70 free HackerNoon stories.
Learn everything you need to know about Statistics via these 70 free HackerNoon stories.
314. Why Lattica’s $3.25M Bet on Fully Homomorphic Encryption Could Change AI Privacy Forever
 Lattica raises $3.25M to make Fully Homomorphic Encryption viable for AI, tackling privacy risks in sensitive industries like healthcare and finance.
Lattica raises $3.25M to make Fully Homomorphic Encryption viable for AI, tackling privacy risks in sensitive industries like healthcare and finance.
315. Online Privacy is Not an Option: It's a Necessity

316. Useful Resources for Data Structure & Algorithm Practice
 These four resources may be useful for learning about data structures and practicing making algorithms for your advanced programming needs in your work.
These four resources may be useful for learning about data structures and practicing making algorithms for your advanced programming needs in your work.
317. Is Backup Testing Part of Your Security Strategy?
 Data backups are crucial in our age of ransomware attacks — but have you tested the effectiveness of your backups? Here's why backup testing is crucial.
Data backups are crucial in our age of ransomware attacks — but have you tested the effectiveness of your backups? Here's why backup testing is crucial.
318. Study: PR Professionals Struggle with Data Literacy, Impeding Communication of Value to Tech C-Suite
 Half of PR pros said they have presented a metric they didn't understand. Here's what reporting is needed to support the C-suite and show PR value.
Half of PR pros said they have presented a metric they didn't understand. Here's what reporting is needed to support the C-suite and show PR value.
319. Solving Data Integration: The Pros and Cons of Open Source and Commercial Software
 There was an awesome debate on DBT’s Slack last week discussing mainly two things:
There was an awesome debate on DBT’s Slack last week discussing mainly two things:
320. Advancing Data Quality: Exploring Data Contracts with Lyft
 Keen to delve into data contracts and discover how they can enhance your data quality? Join me as we explore Lyft's Verity data contract approach together!
Keen to delve into data contracts and discover how they can enhance your data quality? Join me as we explore Lyft's Verity data contract approach together!
321. 121 Stories To Learn About Databases
 Learn everything you need to know about Databases via these 121 free HackerNoon stories.
Learn everything you need to know about Databases via these 121 free HackerNoon stories.
322. How to Improve Data Quality in 2022
 Poor quality data could bring everything you built down. Ensuring data quality is a challenging but necessary task. 100% may be too ambitious, but here's what y
Poor quality data could bring everything you built down. Ensuring data quality is a challenging but necessary task. 100% may be too ambitious, but here's what y
323. The Crazy Tales of IP Geolocation in Real Life
 A report on various dimensions of incidences involving IP Geolocation.
A report on various dimensions of incidences involving IP Geolocation.
324. How to Improve the Table - Content Design Techniques to Simplify Data Reading and Speed Up Work
 I want to show you how to improve the tables by designing the content and information in the cells. How to simplify the reading of data and speed up work
I want to show you how to improve the tables by designing the content and information in the cells. How to simplify the reading of data and speed up work
325. How Digital Twins Are Constructed Through 3D Scanning
 Digital twins are among the most exciting technologies for businesses today. These “twins” are virtual representations of real-world objects, systems or processes that update in real-time as their physical counterparts change. Having these virtual models make it easier to notice potential issues or make informed decisions.
Digital twins are among the most exciting technologies for businesses today. These “twins” are virtual representations of real-world objects, systems or processes that update in real-time as their physical counterparts change. Having these virtual models make it easier to notice potential issues or make informed decisions.
326. How to Generate Synthetic Data?
 A synthetic data generation dedicated repository. This is a sentence that is getting too common, but it’s still true and reflects the market's trend, Data is the new oil. Some of the biggest players in the market already have the strongest hold on that currency.
A synthetic data generation dedicated repository. This is a sentence that is getting too common, but it’s still true and reflects the market's trend, Data is the new oil. Some of the biggest players in the market already have the strongest hold on that currency.
327. Distributed Storage is the Best Data Storage Tool for The Metaverse
 The most suitable data storage tool for Metaverse is undoubtedly distributed storage.
The most suitable data storage tool for Metaverse is undoubtedly distributed storage.
328. Your Children's Data Is Being Collected by Educational Technology Companies
 Vista Equity Partners is collecting data on children that go to school.
Vista Equity Partners is collecting data on children that go to school.
329. Why co-location is the best way to mine bitcoin
 Since the recent Bitcoin halving event, most small and medium crypto miners have had to shut down their mining rigs. Simply put, it is not profitable to have a mining rig in your home at current market prices. However, there are some solutions to the issue.
Since the recent Bitcoin halving event, most small and medium crypto miners have had to shut down their mining rigs. Simply put, it is not profitable to have a mining rig in your home at current market prices. However, there are some solutions to the issue.
330. Data Privacy is Becoming More Important for Users in 2022
 A look at how data privacy is becoming more important for users in 2022
A look at how data privacy is becoming more important for users in 2022
331. Is Cloud Computing Really More Sustainable?
 We've all heard the environmental benefits of cloud computing, but there are some cons as well. Is the cloud really more sustainable?
We've all heard the environmental benefits of cloud computing, but there are some cons as well. Is the cloud really more sustainable?
332. A Javascript Queue Structure for Buffered Data
 If you work with buffered data such as Audio/Video Frame data, you have no doubt appreciated the features of Typed Arrays that came with ES2017 javascript. The ability to move, duplicate, manipulate blocks of data using object methods is achieved by 'imposing' a dataview on the data blocks. These have made buffered data processing a breeze and fast (avoid slow for-loops and extra code ). A detailed discussion of typed arrays is found here: javascript typed arrays.
If you work with buffered data such as Audio/Video Frame data, you have no doubt appreciated the features of Typed Arrays that came with ES2017 javascript. The ability to move, duplicate, manipulate blocks of data using object methods is achieved by 'imposing' a dataview on the data blocks. These have made buffered data processing a breeze and fast (avoid slow for-loops and extra code ). A detailed discussion of typed arrays is found here: javascript typed arrays.
333. Big Data Analysis for the Clueless and the Curious
 Big data analytics has been a hot topic for quite some time now. But what exactly is it? Find out here.
Big data analytics has been a hot topic for quite some time now. But what exactly is it? Find out here.
334. Encoding Categorical Data for ML Algorithms
 Encoding is a technique used to convert categorical data to numerical representations to be able to use the data in machine learning algorithms.
Encoding is a technique used to convert categorical data to numerical representations to be able to use the data in machine learning algorithms.
335. In 2019, Securing Data Is No Easy Task. Clickjacking- A Case Study
 This article is about my journey to understand the current practice of de-anonymization via the clickjacking technique whereby a malicious website is able to uncover the identity of a visitor, including his full name and possibly other personal information. I don’t present any new information here that isn’t already publicly available, but I do look at how easy it is to compromise a visitor’s privacy and reveal his identity, even when he adheres to security best practices and uses an up-to-date browser and operating system.
This article is about my journey to understand the current practice of de-anonymization via the clickjacking technique whereby a malicious website is able to uncover the identity of a visitor, including his full name and possibly other personal information. I don’t present any new information here that isn’t already publicly available, but I do look at how easy it is to compromise a visitor’s privacy and reveal his identity, even when he adheres to security best practices and uses an up-to-date browser and operating system.
336. Data Teams Need Better KPIs. Here's How.
 Here are six important steps for setting goals for data teams.
Here are six important steps for setting goals for data teams.
337. Overfitting in Financial Model Building
 Creating a powerful predictive algorithm usually involves a certain amount of hyperparameter optimization. This involves tuning a model’s parameters to maximize a certain objective function, such as the Sharpe Ratio in finance. One of the most popular methods is Bayesian optimization, which is a significant improvement in computational efficiency and results over both random search and grid search — two other popular ways of optimizing hyperparameters. When evaluating a costly black-box function, Bayesian optimization is by far the most popular method for tuning hyperparameters.
Creating a powerful predictive algorithm usually involves a certain amount of hyperparameter optimization. This involves tuning a model’s parameters to maximize a certain objective function, such as the Sharpe Ratio in finance. One of the most popular methods is Bayesian optimization, which is a significant improvement in computational efficiency and results over both random search and grid search — two other popular ways of optimizing hyperparameters. When evaluating a costly black-box function, Bayesian optimization is by far the most popular method for tuning hyperparameters.
338. A High Level Explanation of Data Types for Decision Makers
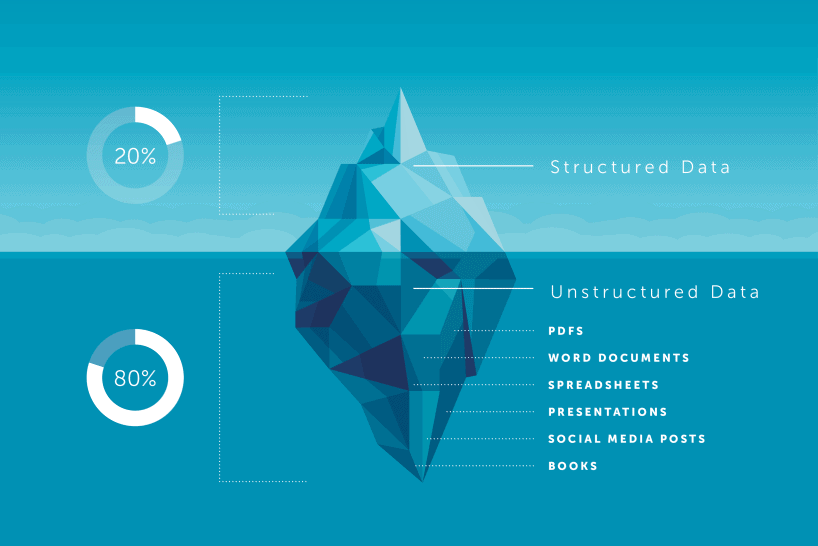 There are three different types of data: structured data, semi structured data, and unstructured data.
There are three different types of data: structured data, semi structured data, and unstructured data.
339. The Failed Promises of Extract, Transform, and Load—and What Comes Next
 Faster, Better Insights: Why Networked Data Platforms Matter for Telecommunications Companies
Faster, Better Insights: Why Networked Data Platforms Matter for Telecommunications Companies
340. A Quick Guide To Business Data Analytics
 For many businesses the lack of data isn’t an issue. Actually, it’s the contrary, there’s usually too much data accessible to make an obvious decision. With that much data to sort, you need additional information from your data.
For many businesses the lack of data isn’t an issue. Actually, it’s the contrary, there’s usually too much data accessible to make an obvious decision. With that much data to sort, you need additional information from your data.
341. Exploring the Pros and Cons of Common NAS Backup Strategies
 A modern data-driven world makes organizations of different scales and sizes use NAS devices as their data storage extensively.
A modern data-driven world makes organizations of different scales and sizes use NAS devices as their data storage extensively.
342. A Technologist Manifesto against Data Imperialism
 Tactical Mission
Tactical Mission
343. We Kinda Bypassed Firebase's Paywall: Here's How
 Some time ago, a few friends and I decided to build an app. We duck-taped our code together, launched our first version, then attracted a few users with a small marketing budget.
Some time ago, a few friends and I decided to build an app. We duck-taped our code together, launched our first version, then attracted a few users with a small marketing budget.
344. The Noonification: Immigrant Teens Are Working Dangerous Night Shifts in Factories (11/21/2022)
11/21/2022: Top 5 stories on the Hackernoon homepage!
345. A Look at COVID’s Impact on Data Privacy and Protection
 After more than a year into the pandemic, it’s clear that COVID-19 will have lasting impacts. As companies rapidly embraced digital transformation, data privacy and protection have seen some of the most significant changes. COVID data risks and policies will likely far outlast the virus itself.
After more than a year into the pandemic, it’s clear that COVID-19 will have lasting impacts. As companies rapidly embraced digital transformation, data privacy and protection have seen some of the most significant changes. COVID data risks and policies will likely far outlast the virus itself.
346. WhatsApp Users Hit 2 Billion: What Does This Mean for the Future of Privacy?

347. 20 Herramientas de Inteligencia Empresarial (BI) más Populares en 2020
 Business Intelligence (BI) es un negocio basado en datos, un proceso de toma de decisiones basado en datos recopilados. A menudo es utilizado por gerentes y ejecutivos para generar ideas procesables. Como resultado, BI siempre se conoce indistintamente como "Business Analytics" o "Data Analytics".
Business Intelligence (BI) es un negocio basado en datos, un proceso de toma de decisiones basado en datos recopilados. A menudo es utilizado por gerentes y ejecutivos para generar ideas procesables. Como resultado, BI siempre se conoce indistintamente como "Business Analytics" o "Data Analytics".
348. Improving Our MongoDB Write Throughput with SQS
 Deep dive on how we got our MongoDB load at a steady sub 50% CPU load by using an SQS layer between our Node application and the database to save costs.
Deep dive on how we got our MongoDB load at a steady sub 50% CPU load by using an SQS layer between our Node application and the database to save costs.
349. Best Types of Data Visualization
 Learning about best data visualisation tools may be the first step in utilising data analytics to your advantage and the benefit of your company
Learning about best data visualisation tools may be the first step in utilising data analytics to your advantage and the benefit of your company
350. Why Did Twilio Acquire Segment for $3.2 Billion? To Better Understand End User Data
 This week the API-based communications platform giant Twilio formally announced that it would acquire the customer data platform startup Segment for $3.2 billion in all stocks. The market responded quite positively to the news, driving Twilio’s stock price up by 7.7%, bring Twilio’s market cap to a staggering $49 billion.
This week the API-based communications platform giant Twilio formally announced that it would acquire the customer data platform startup Segment for $3.2 billion in all stocks. The market responded quite positively to the news, driving Twilio’s stock price up by 7.7%, bring Twilio’s market cap to a staggering $49 billion.
351. IP Geolocation: The Good, The Bad, and The Ugly
 IP Geolocation (IPG) has been a part of our digital lives, for quite a few years now. It is the process of identifying the physical location of an internet user
IP Geolocation (IPG) has been a part of our digital lives, for quite a few years now. It is the process of identifying the physical location of an internet user
352. How to Install and Use Materialize to Run SQL Queries on your nginx Logs
 In this tutorial, I will show you how Materialize works by using it to run SQL queries on continuously produced nginx logs. By the end of the tutorial, you will
In this tutorial, I will show you how Materialize works by using it to run SQL queries on continuously produced nginx logs. By the end of the tutorial, you will
353. Defining the Problem in Your Data Science Project Can Lead to Success
 Defining the Data Science Problems the right way is hard work. The failure rate of various data science initiatives is really high — often ~70-80%.
Defining the Data Science Problems the right way is hard work. The failure rate of various data science initiatives is really high — often ~70-80%.
354. Data-driven Autonomous Driving: AI Needs Diverse Training Datasets to Ensure Security and Robustness
 AI training data solutions will drive the evolution of autonomous driving by providing diverse, high-quality datasets necessary for handling real-world scenerio
AI training data solutions will drive the evolution of autonomous driving by providing diverse, high-quality datasets necessary for handling real-world scenerio
355. Free Mobile App Analytics Tools: A Comprehensive Review
 Free Mobile App Analytics Tools: Explore our comprehensive reviews. Uncover key features, benefits, and make an informed choice for your app success.
Free Mobile App Analytics Tools: Explore our comprehensive reviews. Uncover key features, benefits, and make an informed choice for your app success.
356. Analyzing 110 Million Comments from Hacker News
 In this article, we’ll observe another test with1.1M Hacker News curated comments with numeric fields
In this article, we’ll observe another test with1.1M Hacker News curated comments with numeric fields
357. Mastering AI Operations
 The data whisperer is the function sitting between the business and the technologists.
The data whisperer is the function sitting between the business and the technologists.
358. Decoding MySQL EXPLAIN Query Results for Better Performance (Part 2)
 Understanding MySQL explains query output is essential to optimize the query. EXPLAIN is good tool to analyze your query.
Understanding MySQL explains query output is essential to optimize the query. EXPLAIN is good tool to analyze your query.
359. Metrics, logs, and lineage: 3 Key Elements of Data Observability
 Data observability is built on three core blocks: metrics, logs, and lineage. What are they, and what do they mean for your data quality program?
Data observability is built on three core blocks: metrics, logs, and lineage. What are they, and what do they mean for your data quality program?
360. Data Democratization With AI and What It Means for Business
 AI is dismantling data barriers and changing how organizations make decisions. Learn why broad data access is now key to speed, agility, and growth.
AI is dismantling data barriers and changing how organizations make decisions. Learn why broad data access is now key to speed, agility, and growth.
361. How to Scrape Any Website Using Bright Data MCP Server and AI Agents
 Built a real-time sneaker scraper using Bright Data’s MCP Server, LangChain, Claude, and FastAPI. This tool bypasses scraping blocks and extracts live Nike prod
Built a real-time sneaker scraper using Bright Data’s MCP Server, LangChain, Claude, and FastAPI. This tool bypasses scraping blocks and extracts live Nike prod
362. Predicting 12 Artificial Intelligence Trends for 2024
 From "Lawless AIs" to the industry's environmental cost, the next big thing is going to be a wild ride
From "Lawless AIs" to the industry's environmental cost, the next big thing is going to be a wild ride
363. 6 Tips for Tracking Software Licenses
 If you are looking to manage your software licenses better, Read on to know how you can track and document software used in your company with ease.
If you are looking to manage your software licenses better, Read on to know how you can track and document software used in your company with ease.
364. How to Implement Heap in Data Structure
 Heap data structure is a balanced binary tree data structure where the child node is placed in comparison to the root node and then arranged accordingly.
Heap data structure is a balanced binary tree data structure where the child node is placed in comparison to the root node and then arranged accordingly.
365. Common RAID Failure Scenarios And How to Deal with Them
 Most businesses these days use RAID systems to gain improved performance and security. Redundant Array of Independent Disks (RAID) systems are a configuration of multiple disk drives that can improve storage and computing capabilities. This system comprises multiple hard disks that are connected to a single logical unit to provide more functions. As one single operating system, RAID architecture (RAID level 0, 1, 5, 6, etc.) distributes data over all disks.
Most businesses these days use RAID systems to gain improved performance and security. Redundant Array of Independent Disks (RAID) systems are a configuration of multiple disk drives that can improve storage and computing capabilities. This system comprises multiple hard disks that are connected to a single logical unit to provide more functions. As one single operating system, RAID architecture (RAID level 0, 1, 5, 6, etc.) distributes data over all disks.
366. Ultimate Guide to React Data Grid And its Mind-blowing Features
 Indisputably, React is always the first choice for front-end web developers and simultaneously Data Grid is also the priority for the visual software elements since the evidence of UIs themselves.
Indisputably, React is always the first choice for front-end web developers and simultaneously Data Grid is also the priority for the visual software elements since the evidence of UIs themselves.
367. Data Mesh - A Contrarian View
 You've heard of "Data Mesh" and want to know if it really is all that and a side of fries?
You've heard of "Data Mesh" and want to know if it really is all that and a side of fries?
368. A Guide on The Future of ETL: EL(T) not ELT
 How we store and manage data has completely changed over the last decade. We moved from an ETL world to an ELT world, with companies like Fivetran pushing the trend. However, we don’t think it is going to stop there; ELT is a transition in our mind towards EL(T) (with EL decoupled from T). And to understand this, we need to discern the underlying reasons for this trend, as they might show what’s in store for the future.
How we store and manage data has completely changed over the last decade. We moved from an ETL world to an ELT world, with companies like Fivetran pushing the trend. However, we don’t think it is going to stop there; ELT is a transition in our mind towards EL(T) (with EL decoupled from T). And to understand this, we need to discern the underlying reasons for this trend, as they might show what’s in store for the future.
369. 5 Reasons Why the Blockchain is NOT A Good Fit for Your Business
 Alexandr Kurbatov, EnCata Soft CBDO, tells why businesses should abandon the introduction of popular technology and cases when it still needed.
Alexandr Kurbatov, EnCata Soft CBDO, tells why businesses should abandon the introduction of popular technology and cases when it still needed.
370. Revolutionizing the Value of Data with cheqd
 In this Slogging AMA, the team at Cheqd joined us to explain why and how their platform enables the average user and business to take control of their data.
In this Slogging AMA, the team at Cheqd joined us to explain why and how their platform enables the average user and business to take control of their data.
371. What is RFM (Recency, Frequency, Monetary) Analysis?
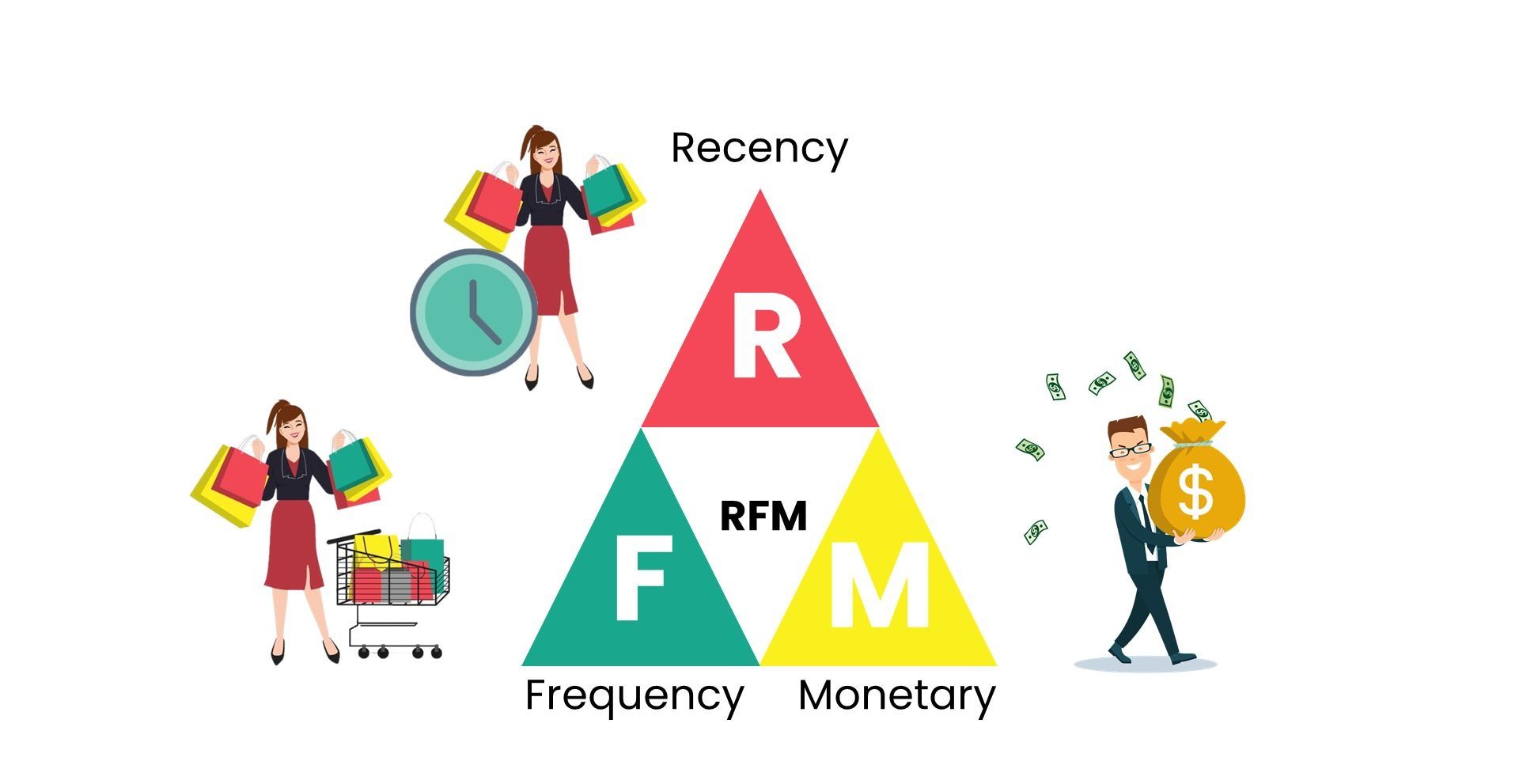 RFM analysis is a data-driven customer segmentation technique that allows marketing professionals to take tactical decisions based on severe data refining
RFM analysis is a data-driven customer segmentation technique that allows marketing professionals to take tactical decisions based on severe data refining
372. New ChatGPT-4o: A Game-Changer That Could Replace Data Analysts
 In this article, I will highlight a few things that may help you decide on your data analysis career path with ChatGPT.
In this article, I will highlight a few things that may help you decide on your data analysis career path with ChatGPT.
373. Benefits of Corporate Data Backup and Best Practices to Keep in Place
 Nowadays, companies are increasingly relying on corporate data backup solutions to guarantee the safety and recoverability of their data. Read on to learn more
Nowadays, companies are increasingly relying on corporate data backup solutions to guarantee the safety and recoverability of their data. Read on to learn more
374. Your Data is the DNA of Artificial Intelligence
 As society becomes increasingly AI-driven, the essential raw material to create artificial intelligence is your data.
As society becomes increasingly AI-driven, the essential raw material to create artificial intelligence is your data.
375. Best Practices For Backend Data Security
 Backend data security relies in encryption, access control, data backup and other such features to exist. These best practices are intended for the backend.
Backend data security relies in encryption, access control, data backup and other such features to exist. These best practices are intended for the backend.
376. How to Become a Private Home Trader and 10 Tips to Help You Get There
 Trading is a booming sector that today attracts many people. Here are 10 tips to help you succeed as a trader.
Trading is a booming sector that today attracts many people. Here are 10 tips to help you succeed as a trader.
377. Debugging My Love Life
 Tinder's "Top Spotify Artists" feature is relatively shallow, but could be fixed easily. Here is a demonstration of how it works currently and what can change.
Tinder's "Top Spotify Artists" feature is relatively shallow, but could be fixed easily. Here is a demonstration of how it works currently and what can change.
378. Data Persistent Prometheus-Grafana Intergration with Jenkins
 Prometheus is an open-source application monitoring and alerting software solution. It is a web application which can be deployed anywhere — in a PC, virtual machine, or even in a container. It scrapes data from the exporters (small programs convert system data to Prometheus metrics) periodically and records the real-time metrics in a time series database.
Prometheus is an open-source application monitoring and alerting software solution. It is a web application which can be deployed anywhere — in a PC, virtual machine, or even in a container. It scrapes data from the exporters (small programs convert system data to Prometheus metrics) periodically and records the real-time metrics in a time series database.
379. Choosing A Colocation Data Centre That’s Right For You
 Data and computer systems are at the heart of most companies, which is why it is paramount that where you store your IT infrastructure meets your needs.
Data and computer systems are at the heart of most companies, which is why it is paramount that where you store your IT infrastructure meets your needs.
380. The Internet Has a Pulse, and This Sequencer Lets You Hear It
 The social sequencer is a new media synth interactive art piece to explore the concept of the emergence theory through sound.
The social sequencer is a new media synth interactive art piece to explore the concept of the emergence theory through sound.
381. The 3 Main Reasons Manufacturers and Distributors Should Use Data Integration Tools
 Many manufacturers, distributors, and supply chain organizations use data integration tools to gain meaningful insights from their ERPs.
Many manufacturers, distributors, and supply chain organizations use data integration tools to gain meaningful insights from their ERPs.
382. The Role of Data Scientists in the Age of AI and Automation
 In this, we'll explore the world of data scientists and the role they play in this age of technological wonders.
In this, we'll explore the world of data scientists and the role they play in this age of technological wonders.
383. Startup Cerebral Agrees to Pay $7 Million Fine and More Under Order by the FTC
 Telehealth company Cerebral will limit the consumer health data it uses for advertising purposes under a new order announced by the FTC last week.
Telehealth company Cerebral will limit the consumer health data it uses for advertising purposes under a new order announced by the FTC last week.
384. Data-Driven Approach for Software Engineering: How to Avoid Common Problems

385. How Technological Progress Takes Affiliate Marketing to the Next Level
 The world around us is changing at a rate that’s often incomprehensible to us. We’re seeing new inventions everywhere we look, and it’s happening every single day. 5G, AI, VR, satellite Wi-Fi - these and other inventions are constantly hitting our cognitive system, making it overwhelmed.
The world around us is changing at a rate that’s often incomprehensible to us. We’re seeing new inventions everywhere we look, and it’s happening every single day. 5G, AI, VR, satellite Wi-Fi - these and other inventions are constantly hitting our cognitive system, making it overwhelmed.
386. The Beginner's Guide to The Google HEART Framework
 In this post, we will dig into the Google HEART framework: a simple way to ensure you take into consideration every aspect of the user journey.
In this post, we will dig into the Google HEART framework: a simple way to ensure you take into consideration every aspect of the user journey.
387. Agentic AI and Agentic RAG: Hyped Buzzwords or Game-Changers?
 Let's dig into the new Agentic AI and Agentic RAG trends to understand what they truly are.
Let's dig into the new Agentic AI and Agentic RAG trends to understand what they truly are.
388. Data Services for the Masses
 I’ve held several roles in my career in IT, ranging from software developer to enterprise architect to developer advocate. I’ve always been fascinated by the role that data plays in our applications—putting it into databases, getting it back out quickly, making sure it remains accurate when transferred between systems. Many of the hardest problems I’ve encountered have centered around data. For example:
I’ve held several roles in my career in IT, ranging from software developer to enterprise architect to developer advocate. I’ve always been fascinated by the role that data plays in our applications—putting it into databases, getting it back out quickly, making sure it remains accurate when transferred between systems. Many of the hardest problems I’ve encountered have centered around data. For example:
389. The Role of Data Destruction in Cybersecurity
 What happens to information when it's no longer necessary? If you're concerned with cybersecurity, you should destroy it.
What happens to information when it's no longer necessary? If you're concerned with cybersecurity, you should destroy it.
390. 9 Dropbox Alternatives for Evidence Management in Law Enforcement
 For evidence management and storage, there are multiple alternatives to Dropbox available which can save time and be customized for your specific needs.
For evidence management and storage, there are multiple alternatives to Dropbox available which can save time and be customized for your specific needs.
391. 4 Ways Cities Are Utilizing Data for Public Safety
 Cities have been using data for public safety for years. What new technology is emerging in public safety, and how does it affect you?
Cities have been using data for public safety for years. What new technology is emerging in public safety, and how does it affect you?
392. A How-to Guide for Data Backup and VM Modernization
 Data is everywhere it is something that we all rely on. It is used by individuals and large organizations that collect and store hundreds of files a day.
Data is everywhere it is something that we all rely on. It is used by individuals and large organizations that collect and store hundreds of files a day.
393. Fetch.ai Releases DabbaFlow: Encrypted File Sharing Platform for Secure Data Transfers
 DabbaFlow, an end-to-end encrypted file-sharing platform developed by Fetch.ai, a Cambridge-based artificial intelligence lab, was launched recently.
DabbaFlow, an end-to-end encrypted file-sharing platform developed by Fetch.ai, a Cambridge-based artificial intelligence lab, was launched recently.
394. The Mass Storing of Data Can Turn The Consumer into The New Farmer
 Google’s cloud is an interesting example of how information flips the supply chain upside down.
Google’s cloud is an interesting example of how information flips the supply chain upside down.
395. Mortgage Brokers Are Sending Personal Data to Facebook
 As users filled out mortgage applications or requested quotes for mortgage rates, the pixel tracked information about their credit, veteran status, and more
As users filled out mortgage applications or requested quotes for mortgage rates, the pixel tracked information about their credit, veteran status, and more
396. Putting Value back in the Data Economy with Pool Data CEO Shiv Malik
 In this slogging AMA, we host the CEO of Pool Data, Shiv Malik. Shiv walks us through Pool Data and how it supports data unions.
In this slogging AMA, we host the CEO of Pool Data, Shiv Malik. Shiv walks us through Pool Data and how it supports data unions.
397. 75 Stories To Learn About Datasets
 Learn everything you need to know about Datasets via these 75 free HackerNoon stories.
Learn everything you need to know about Datasets via these 75 free HackerNoon stories.
398. Ultimate Guide to Synthetic Monitoring Products
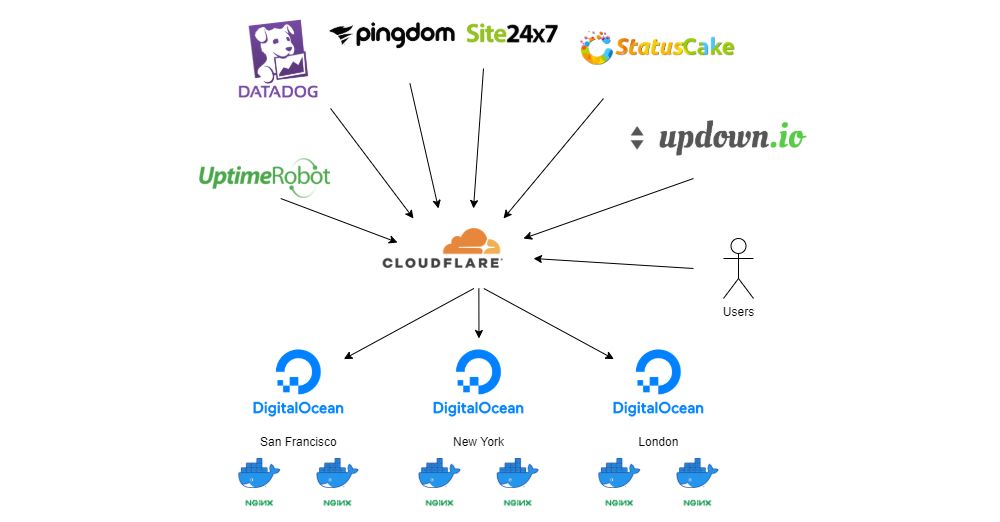 As we look forward to 2021, Synthetic Monitoring continues to be as important as ever in understanding the performance of your app or website. But your synthetic monitoring is only as good as the tool you're using and there are a lot of product choices. Since selecting the best one for you is critical, the choice can be overwhelming. Price, setup ease, accuracy, and more play a part in the best solution.
As we look forward to 2021, Synthetic Monitoring continues to be as important as ever in understanding the performance of your app or website. But your synthetic monitoring is only as good as the tool you're using and there are a lot of product choices. Since selecting the best one for you is critical, the choice can be overwhelming. Price, setup ease, accuracy, and more play a part in the best solution.
399. Using Arrow Flight SQL Protocol in Apache Doris 2.1 For Super Fast Data Transfer
 Apache Doris 2.1 just got a major speed boost with Arrow Flight SQL for up to 10x faster data transfers.
Apache Doris 2.1 just got a major speed boost with Arrow Flight SQL for up to 10x faster data transfers.
400. Why Governments Can’t Stay Away from Blockchain

401. Using SPyQL and Python to Run Command Line Analytics
 SPyQL combines Python and SQL to make querying of CSV and JSON data easy. In this tutorial we analyse the geographical distribution of cell towers.
SPyQL combines Python and SQL to make querying of CSV and JSON data easy. In this tutorial we analyse the geographical distribution of cell towers.
402. The Importance of a Single Source of Truth for Enterprises
 A single source of truth (SSOT) enables that synchronization. A company with SSOT relies on one and only one point of reference for the latest, aggregated info.
A single source of truth (SSOT) enables that synchronization. A company with SSOT relies on one and only one point of reference for the latest, aggregated info.
403. Web Scraping Using Node.js
 While there are a few different libraries for scraping the web with Node.js, in this tutorial, i'll be using the puppeteer library.
While there are a few different libraries for scraping the web with Node.js, in this tutorial, i'll be using the puppeteer library.
404. Why Data Governance is Vital for Data Management
 Both data governance and data management workflows are critical to ensuring the security and control of an organization’s most valuable asset-data.
Both data governance and data management workflows are critical to ensuring the security and control of an organization’s most valuable asset-data.
405. How To Manage and Debug Data Pipelines in Airflow
 Learn how to manage and debug data pipelines in Airflow with real-world practical examples. Use the Grid View for observability and manual debugging.
Learn how to manage and debug data pipelines in Airflow with real-world practical examples. Use the Grid View for observability and manual debugging.
406. How To Use Change Data Capture for Fraud Detection
 Still relying on overnight processes to drive your decision making? Maybe it’s time to consider an evaluation of your CDC pattern that uses new technology.
Still relying on overnight processes to drive your decision making? Maybe it’s time to consider an evaluation of your CDC pattern that uses new technology.
407. Data Breaches: Why You Should Never Share Your Passwords
 Data Breaches: Why You Should Never Share Your Passwords
Data Breaches: Why You Should Never Share Your Passwords
408. From 1999 to 2020, Google Grew from 10k to 4.6B Daily Searches
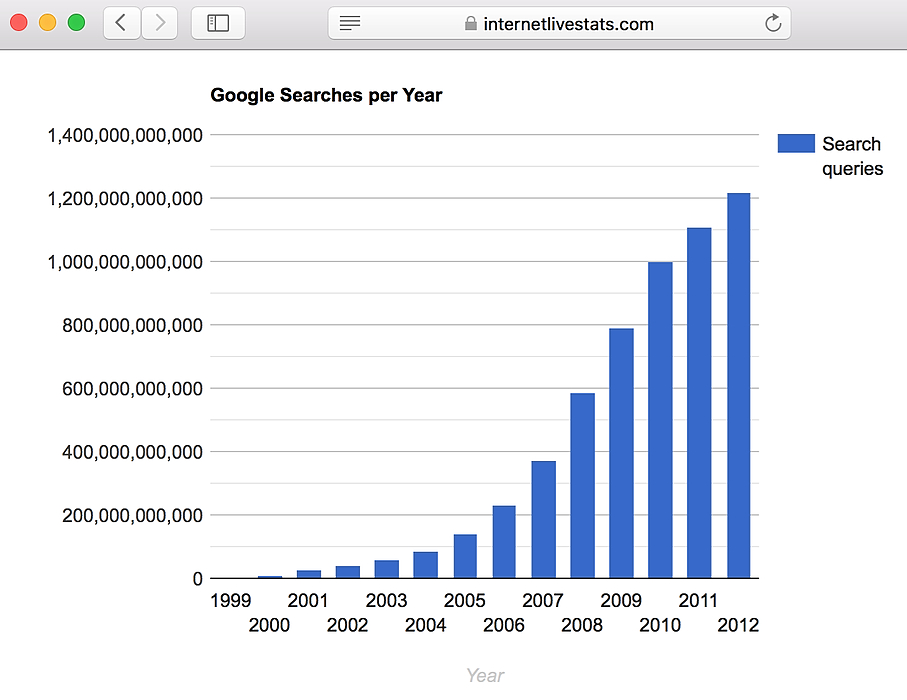 The Internet Live Stats graph above pictures Google's first 13 years. Today they report 4,517,847,993 DA(internet)Us currently do 4,781,309,755 daily Google searches, according to Internet Live Stats.
The Internet Live Stats graph above pictures Google's first 13 years. Today they report 4,517,847,993 DA(internet)Us currently do 4,781,309,755 daily Google searches, according to Internet Live Stats.
409. The Critical Role of Customer Data in Creating Personalized Product Experiences
 With 97.2% of businesses investing in data and AI, one thing is clear: data isn’t a “nice to have” anymore; it’s a necessity.
With 97.2% of businesses investing in data and AI, one thing is clear: data isn’t a “nice to have” anymore; it’s a necessity.
410. Accelerating Excavation and Refinement of Data Gold Mines
 Unlock the potential of data-driven decision-making with generative AI and NLP.
Unlock the potential of data-driven decision-making with generative AI and NLP.
411. Antonio Reza's Top 10 Secrets to Mastering Sheets Like a Pro
 I've created hundreds of financial models in Google Sheets using SQL and AI to help the company sell billions of dollars.
I've created hundreds of financial models in Google Sheets using SQL and AI to help the company sell billions of dollars.
412. Why "Big Data" is No Longer Relevant in the Age of Machine Learning and Deep Learning
 Discover why "Big Data" is no longer relevant with the rise of Machine Learning and Deep Learning. Learn how these technologies transform data analytics.
Discover why "Big Data" is no longer relevant with the rise of Machine Learning and Deep Learning. Learn how these technologies transform data analytics.
413. If a Data Broker Goes Bankrupt, What Happens to Your Sensitive Data?
 What happens to Near’s mountain of location data? Any company could gain access to it through purchasing the company’s assets.
What happens to Near’s mountain of location data? Any company could gain access to it through purchasing the company’s assets.
414. HIPAA Does Not Prevent Period-Tracking Apps From Selling Location Data
 The Health Insurance Portability and Accountability Act, the federal patient privacy law known as HIPAA, does not apply to most apps that track menstrual cycles
The Health Insurance Portability and Accountability Act, the federal patient privacy law known as HIPAA, does not apply to most apps that track menstrual cycles
415. How Big Tech Influences Privacy Laws
 The Markup reviewed public hearing testimony in all 31 states that have considered consumer data privacy legislation since 2021 and found a campaign by Big Tech
The Markup reviewed public hearing testimony in all 31 states that have considered consumer data privacy legislation since 2021 and found a campaign by Big Tech
416. What to Expect from AI in 2022
 AI is too complex and dynamic a technology to be approached one-sidedly, only from the business or IT side. Read the article and find out more
AI is too complex and dynamic a technology to be approached one-sidedly, only from the business or IT side. Read the article and find out more
417. Blockchain Technology Improves Data Authentication and Transparency in Healthcare
 Blockchain is the secret to trusting the data as it moves into our healthcare ecosystem.
Blockchain is the secret to trusting the data as it moves into our healthcare ecosystem.
418. Data Can Help You: How Technologies Fight Mental Health Issues
 Medical technologies are not limited to remote examinations, robotic surgical controllers and diagnostic algorithms. Today they transform mental health domain, specifically, work methods with patients and the doctor’s role.
Medical technologies are not limited to remote examinations, robotic surgical controllers and diagnostic algorithms. Today they transform mental health domain, specifically, work methods with patients and the doctor’s role.
419. Planning for Your Startup: The Data Team's Guide to 2021
 Planning in a startup can feel like an exercise in futility — especially when it comes to data — especially when your data team is small and scrappy.
Planning in a startup can feel like an exercise in futility — especially when it comes to data — especially when your data team is small and scrappy.
420. How to Track Form Completions with Google Tag Manager
 Setting up a website is relatively easy in 2020. Gone are the days when you had to code the whole thing on notepad and then connect to your host with some additional FTP software.
Setting up a website is relatively easy in 2020. Gone are the days when you had to code the whole thing on notepad and then connect to your host with some additional FTP software.
421. 87 Stories To Learn About Data Structures
 Learn everything you need to know about Data Structures via these 87 free HackerNoon stories.
Learn everything you need to know about Data Structures via these 87 free HackerNoon stories.
422. Is Your Data Biased? How To Overcome Survivorship Bias
 In this post, we study the Survivorship bias — the danger to concentrate your data analysis solely on existing power users
In this post, we study the Survivorship bias — the danger to concentrate your data analysis solely on existing power users
423. SQLite the New Hotness?! 🤔
 A survey of why SQLite is trending up in many places. Because of its ease of use, it is used in many places behind the scenes.
A survey of why SQLite is trending up in many places. Because of its ease of use, it is used in many places behind the scenes.
424. Public Web Data for Business: Common Challenges And How to Solve Them
 Businesses working with public web data experience various challenges. This article covers the most common ones and how to overcome them.
Businesses working with public web data experience various challenges. This article covers the most common ones and how to overcome them.
425. Holy Land of Crypto Users: How does Web3.0 Data Empower Centralized Exchanges?
 Designing a data-oriented, user-incentive mechanism is a good path when developing the future of centralised exchanges for the cryptocurrency industry.
Designing a data-oriented, user-incentive mechanism is a good path when developing the future of centralised exchanges for the cryptocurrency industry.
426. 361 Stories To Learn About Big Data
 Learn everything you need to know about Big Data via these 361 free HackerNoon stories.
Learn everything you need to know about Big Data via these 361 free HackerNoon stories.
427. How Different Analyst Types Can Positively Impact Your Small Business
 Data analysis used to be considered a luxury of big business.
Data analysis used to be considered a luxury of big business.
428. Public Health Improvements as a Result of Data Usage and Analysis in Healthcare
 Big data has made a slow transition from being a vague boogie man to being a force of profound and meaningful change. Though it’s far from reaching its full potential, data is already having an enormous impact onhealthcare outcomes across the world — both at the public and individual levels.
Big data has made a slow transition from being a vague boogie man to being a force of profound and meaningful change. Though it’s far from reaching its full potential, data is already having an enormous impact onhealthcare outcomes across the world — both at the public and individual levels.
429. So You Just Became a Data Science Manager... Now What?
 With the rise of data science there has been the rise of data science managers. So what do you need to keep in mind if you wish to join these data translators that are acting as a conduit between the business and technical data teams? Going from a practitioner to a manager — your job now is to make sure that data resources are being used optimally so how do you go about doing this effectively?
With the rise of data science there has been the rise of data science managers. So what do you need to keep in mind if you wish to join these data translators that are acting as a conduit between the business and technical data teams? Going from a practitioner to a manager — your job now is to make sure that data resources are being used optimally so how do you go about doing this effectively?
430. Data Science With R Programming — Coding Interview Questions
 R is a tool used for data management, storage, and analysis in the field of data science. It has applications in statistical analysis and modeling.
R is a tool used for data management, storage, and analysis in the field of data science. It has applications in statistical analysis and modeling.
431. How Will Blockchain Fix the Centralization of Data?
 “In order to have a standard of value [cryptocurrency] must stand outside all value schemes. It must have value in and of itself."
“In order to have a standard of value [cryptocurrency] must stand outside all value schemes. It must have value in and of itself."
432. The Effectiveness of AI and ML on Supply Chains Amidst a Global Pandemic
 Covid-19 's impact on the supply chain industry has been very predominant. How to mitigate the situation by making the best of different optimization.
Covid-19 's impact on the supply chain industry has been very predominant. How to mitigate the situation by making the best of different optimization.
433. Digital Consumers: It's Time to Grow Up
 The recent release of Netflix's film “The Social Dilemma” has boosted existing questions and fears looming among consumers regarding their privacy on social media platforms. Putting aside the behavioral effects of social media, one must wonder why the modern consumer has become so critical and scared of the data-gathering and targeted ads behind social media when they have made our lives so much better.
The recent release of Netflix's film “The Social Dilemma” has boosted existing questions and fears looming among consumers regarding their privacy on social media platforms. Putting aside the behavioral effects of social media, one must wonder why the modern consumer has become so critical and scared of the data-gathering and targeted ads behind social media when they have made our lives so much better.
434. The Day the Cloud Cracked: AWS Outage Exposes Fragility of Centralized Internet
 AWS crashed for 15 hours taking down Snapchat, Fortnite and 2,500+ companies. 11M users affected. What went wrong.
AWS crashed for 15 hours taking down Snapchat, Fortnite and 2,500+ companies. 11M users affected. What went wrong.
435. My Bot Helps You Trade Data - Introducing ARBot
 Data is becoming increasingly recognised as an asset of value. So much so, in fact, that data marketplaces have opened up, establishing an emerging data economy. This has opened up a wealth of profit-making opportunities that most people are still unaware of. Having worked closely with leading data marketplaces for over a year, I decided to try my hand at something new: arbitrage with data as an asset.
Data is becoming increasingly recognised as an asset of value. So much so, in fact, that data marketplaces have opened up, establishing an emerging data economy. This has opened up a wealth of profit-making opportunities that most people are still unaware of. Having worked closely with leading data marketplaces for over a year, I decided to try my hand at something new: arbitrage with data as an asset.
436. CS Data Structures: Fixed Array
 A fixed array is an array that has a max amount of items. Such arrays are used when the programmer knows how many elements an array should hold.
A fixed array is an array that has a max amount of items. Such arrays are used when the programmer knows how many elements an array should hold.
437. 3 Best Data Recovery Tools for Windows and Mac
 Going through a hard drive crash and having to start your data recovery efforts all over again from scratch can be frustrating and time-consuming.
Going through a hard drive crash and having to start your data recovery efforts all over again from scratch can be frustrating and time-consuming.
438. As Internet Usage Spikes During COVID-19 Pandemic: How Are ISPs Holding Up?
 As communities worldwide grapple with the reality of an extended COVID-19 induced lock-down, Internet usage has, understandably, significantly increased. As more and more countries are forced into lock-down in an effort to curb the spread of the deadly virus, the growing number of people forced into working remotely and finding online entertainment is seeing the Internet absolutely explode. In fact COVID-19 has pushed up Internet use by a whopping 70 percent in some countries while streaming services are up by more than 12 percent, figures last month revealed.
As communities worldwide grapple with the reality of an extended COVID-19 induced lock-down, Internet usage has, understandably, significantly increased. As more and more countries are forced into lock-down in an effort to curb the spread of the deadly virus, the growing number of people forced into working remotely and finding online entertainment is seeing the Internet absolutely explode. In fact COVID-19 has pushed up Internet use by a whopping 70 percent in some countries while streaming services are up by more than 12 percent, figures last month revealed.
439. MongoDB vs. DynamoDB: Choosing the Best Database for Your Business
 All about MongoDB vs DynamoDB. Explore benefits, and in-depth comparison to find out the best choice for your business app.
All about MongoDB vs DynamoDB. Explore benefits, and in-depth comparison to find out the best choice for your business app.
440. Why Python Is Leading the Charge in Data Analytics

441. How to Grow your Video Business with Data
 TV watching used to be a family affair a decade ago, but today in most households, content watching has become a personal activity.
TV watching used to be a family affair a decade ago, but today in most households, content watching has become a personal activity.
442. Efficient Dockerized Database Monitoring with Dockerized PMM
 Learn how to monitor your databases with ease using Docker and Percona Monitoring and Management (PMM). PMM is a free and open-source platform for monitoring an
Learn how to monitor your databases with ease using Docker and Percona Monitoring and Management (PMM). PMM is a free and open-source platform for monitoring an
443. How Data Scientists Start Automating Their Tasks With Python
 Introduction to automation with python and my top 3 most used code snippets.
Introduction to automation with python and my top 3 most used code snippets.
444. AI Will Reshape the Cybersecurity World in 2021
 Cybersecurity providers will step up AI development to merge human and machine understanding to outpace cybercriminals' goal of staging an arms race.
Cybersecurity providers will step up AI development to merge human and machine understanding to outpace cybercriminals' goal of staging an arms race.
445. Data Privacy Concerns in the World of Generative AI
 Discover the impact of generative AI tools on data privacy and explore their potential while safeguarding sensitive information.
Discover the impact of generative AI tools on data privacy and explore their potential while safeguarding sensitive information.
446. This Data Set Shows How Our Emotions Affect the Weather
 An interesting observation on the emotional effect of weather. Correlation does not equate causation but the situation remains fascinating to readers anyway.
An interesting observation on the emotional effect of weather. Correlation does not equate causation but the situation remains fascinating to readers anyway.
447. Linear Regression vs. Logistic Regression for Classification Tasks
 This article explains why logistic regression performs better than linear regression for classification problems, and 2 reasons why linear regression is not suitable:
This article explains why logistic regression performs better than linear regression for classification problems, and 2 reasons why linear regression is not suitable:
448. Facebook and Anti-Abortion Clinics Have Your Info
 Facebook is collecting ultrasensitive personal data about abortion seekers and enabling anti-abortion organizations to use that data
Facebook is collecting ultrasensitive personal data about abortion seekers and enabling anti-abortion organizations to use that data
449. Leveraging Data Analytics to Improve Patient Adherence
 Role of of pharma analytics to enumerate the factors accountable for falling medication adherence and the increasing role of data analytics and machine learnin
Role of of pharma analytics to enumerate the factors accountable for falling medication adherence and the increasing role of data analytics and machine learnin
450. How to Forecast Purchase Orders for Shopify Stores Using Open-Source
 Use the open-source integrated machine learning in MindsDB and the open-source data integration platform Airbyte to forecast Shopify store metrics.
Use the open-source integrated machine learning in MindsDB and the open-source data integration platform Airbyte to forecast Shopify store metrics.
451. Understanding Partitioned Services in Distributed Systems
 A short tutorial on how Partitioned Services work and how to implement them in Python using Consistency Hashing,
A short tutorial on how Partitioned Services work and how to implement them in Python using Consistency Hashing,
452. Hospitals Remove Facebook Tracker but Questions Still Remain
 Meanwhile, developments in another legal case suggest Meta may have a hard time providing the Senate committee with a complete account of the health data.
Meanwhile, developments in another legal case suggest Meta may have a hard time providing the Senate committee with a complete account of the health data.
453. Which Database Is Right For You?Graph Database vs. Relational Database
 Learn about the main differences between graph and relational databases. What kind of use-cases are best suited for each type, their strengths, and weaknesses.
Learn about the main differences between graph and relational databases. What kind of use-cases are best suited for each type, their strengths, and weaknesses.
454. Getting Started With Python Bokeh: 25+ Data Visualization Examples With Source Code
 Discover dynamic data visualization with Python Bokeh, featuring interactive graphs and easy examples.
Discover dynamic data visualization with Python Bokeh, featuring interactive graphs and easy examples.
455. Tamper Proofing in the Digital Age: A Look at Proof of SQL
 Interview with Jay White discussing the ZK-Proof Proof and it's development.
Interview with Jay White discussing the ZK-Proof Proof and it's development.
456. The Added Value of GPU-Accelerated Analytics
 GPUs are now being put to the test in the three fastest developing applications in today’s tech ecosystem.
GPUs are now being put to the test in the three fastest developing applications in today’s tech ecosystem.
457. AWS Regions and Availability Zones: A Useful Guide for Beginners
 High Availability in the cloud: why us-east-1 alone is not a strategy (it's a gamble)
High Availability in the cloud: why us-east-1 alone is not a strategy (it's a gamble)
458. 4 Best Data Recovery Tools For SD cards, USB Drives, and Hard Drives
 Oh no! I lost all my vacation pictures. What do I do now? Is it possible to recover all the deleted files from the SD card? Will I ever get to see my photos from the vacation again?
Oh no! I lost all my vacation pictures. What do I do now? Is it possible to recover all the deleted files from the SD card? Will I ever get to see my photos from the vacation again?
459. 16 Guides to Get You Started with Apache Iceberg
 These guides are designed to provide you with practical experience in working with Apache Iceberg.
These guides are designed to provide you with practical experience in working with Apache Iceberg.
460. The One Tool You Absolutely Need to Efficiently Scale Retrieval-Augmented Generation
 Achieve efficiency and reliability in your GenAI RAG workflows with KubeMQ for seamless message handling and FalkorDB for fast, scalable data storage/retrieval.
Achieve efficiency and reliability in your GenAI RAG workflows with KubeMQ for seamless message handling and FalkorDB for fast, scalable data storage/retrieval.
461. Debunking the 15 Biggest Myths About Data Quality
 Data quality misconceptions can negatively impact business outcomes. Here are 15 common myths — and why they're wrong.
Data quality misconceptions can negatively impact business outcomes. Here are 15 common myths — and why they're wrong.
462. Denial Of Service (DoS) Attacks: Nature And Method Of Infection
 Denial Of Service or DoS attacks work by overloading the target host’s bandwidth, preventing other users from accessing the affected server, denying service.
Denial Of Service or DoS attacks work by overloading the target host’s bandwidth, preventing other users from accessing the affected server, denying service.
463. Not So Fast: Valuable Lessons from the FastCompany Hack
 When FastCompany's website was hacked recently, it sent shockwaves through the media world, underscoring the importance of routine cybersecurity hygiene.
When FastCompany's website was hacked recently, it sent shockwaves through the media world, underscoring the importance of routine cybersecurity hygiene.
464. Storing data with Vinyl
 This article describes how the developers of the in-memory computing platform Tarantool implemented disk storage.
This article describes how the developers of the in-memory computing platform Tarantool implemented disk storage.
465. In the future, your data is more valuable than gold
 The value of your data is defined by the persona built about you, including who you are and all your preferences.
The value of your data is defined by the persona built about you, including who you are and all your preferences.
466. How to Migrate Data from an MSSQL Server to PostGreSQL?
 Thinking of shifting to a new database management engine? Here's how to migrate data from SQL server to PostgreSQL.
Thinking of shifting to a new database management engine? Here's how to migrate data from SQL server to PostgreSQL.
467. How to Navigate Privacy Regulations and Still Leverage User Data
 User data has become the cornerstone of almost every company trying to create value in the digital space.
User data has become the cornerstone of almost every company trying to create value in the digital space.
468. The Burgeoning Global Surveillance State - What's Going On?
 What is a surveillance state? Privacy International defines it as one which “collects information on everyone without regard to innocence or guilt” and “deputizes the private sector by compelling access to their data”.
What is a surveillance state? Privacy International defines it as one which “collects information on everyone without regard to innocence or guilt” and “deputizes the private sector by compelling access to their data”.
469. Automated Offline Backups Can Save the World
 Ransomware is worse than malware: Systems and data are all locked up, and backups are all encrypted, too.
Ransomware is worse than malware: Systems and data are all locked up, and backups are all encrypted, too.
470. How to Make Rough Estimates of SQL Queries
 To do estimates of SQL queries we need to understand how DB works with queries. Let's find out what exactly the db do with queries.
To do estimates of SQL queries we need to understand how DB works with queries. Let's find out what exactly the db do with queries.
471. Identifying The Poor in India: A Data Driven Analysis
 Ever since I quit the corporate world, the story I have been telling myself is that I want to work on uplifting the poorest. It sounds romantic at the onset but like most things, is a lot more complicated when you get down into the weeds.
Ever since I quit the corporate world, the story I have been telling myself is that I want to work on uplifting the poorest. It sounds romantic at the onset but like most things, is a lot more complicated when you get down into the weeds.
472. Synesis One Launches World's First AI Data Outsourcing App on Solana Mainnet
 Synesis One announced today the launch of its new Train2Earn App ‘Workspace by Synesis' on IOS, Android, Saga and Web browsers.
Synesis One announced today the launch of its new Train2Earn App ‘Workspace by Synesis' on IOS, Android, Saga and Web browsers.
473. Chinese Apps in Crosshairs: Will SHEIN, CapCut and Temu Face Regulations Next?
 How these three popular apps could face bans and lawsuits in the US and other countries.
How these three popular apps could face bans and lawsuits in the US and other countries.
474. Data Observability: The First Step Towards Being Data-Driven
 In a nutshell, data reliability is a BIG challenge and there is a need for a solution that is easy to use, understand, and deploy, and also not hea
In a nutshell, data reliability is a BIG challenge and there is a need for a solution that is easy to use, understand, and deploy, and also not hea
475. 4 Data Transformations Made Spreadsheet-Easy
 Gigasheet combines the ease of a spreadsheet, the power of a database, and the scale of the cloud.
Gigasheet combines the ease of a spreadsheet, the power of a database, and the scale of the cloud.
476. Rust DataFrame Alternatives to Polars: Meet Elusion v4.0.0
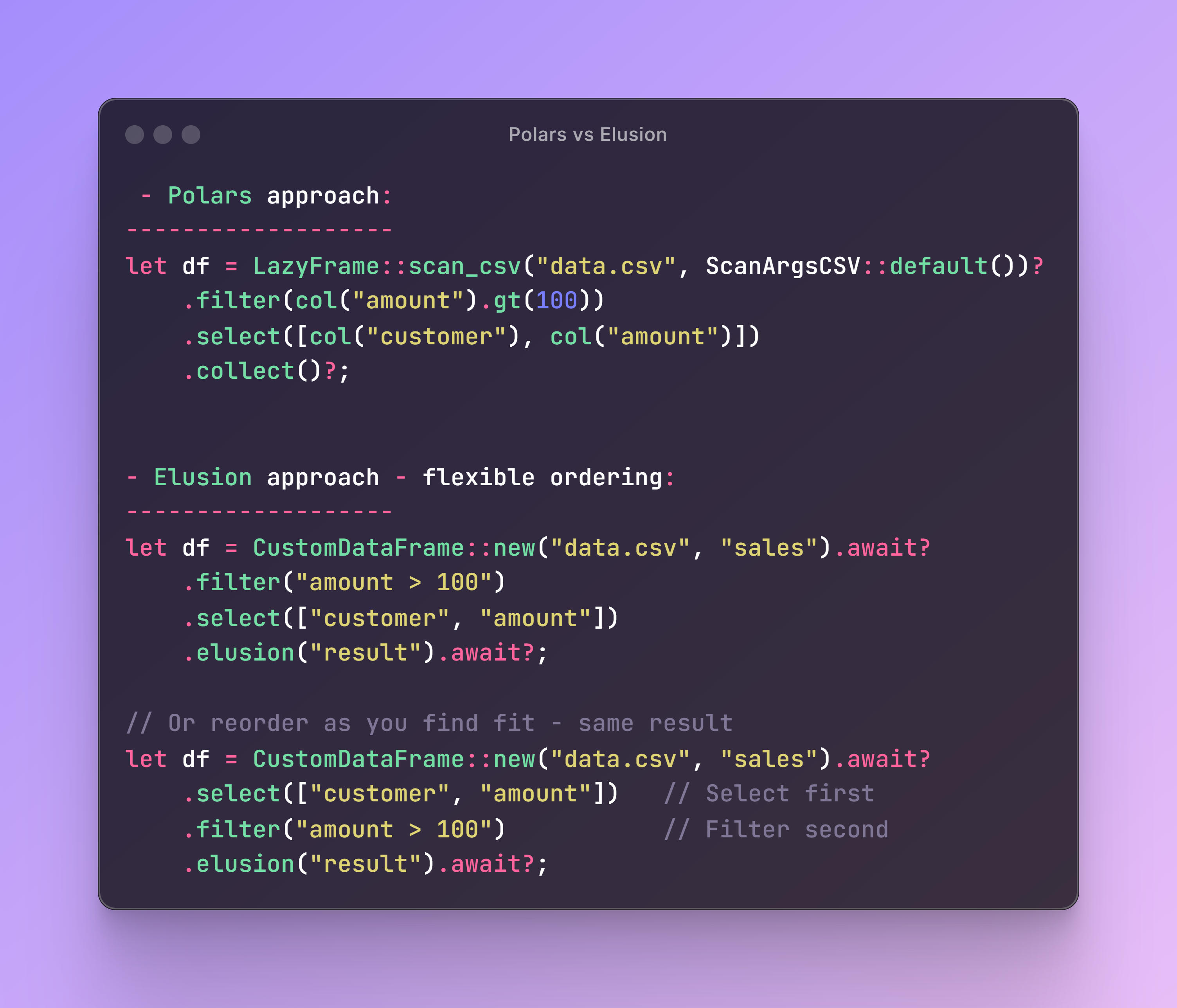 Elusion is a new contender that takes a fundamentally different approach to data engineering and analysis.
Elusion is a new contender that takes a fundamentally different approach to data engineering and analysis.
477. Raising Funds as a Blockchain Startup: A KYVE Interview
 This article talks about how to raise funding as a blockchain startup and decentralized storage systems.
This article talks about how to raise funding as a blockchain startup and decentralized storage systems.
478. Big Data Analysis on Blockchain with CEO of Covalent, Ganesh Swami
 I sat down with Ganesh Swami, co-founder and CEO at Covalent, a Blockchain Big Data analytics firm, to discuss the Ethereum ecosystem.
I sat down with Ganesh Swami, co-founder and CEO at Covalent, a Blockchain Big Data analytics firm, to discuss the Ethereum ecosystem.
479. FTC Takes Action Against Monument for Sharing Health Data
 The FTC took action against telehealth company Monument, affirming its promise to crack down on digital health companies’ misuse of personal health data.
The FTC took action against telehealth company Monument, affirming its promise to crack down on digital health companies’ misuse of personal health data.
480. Using Data Science To Deal With RTOs
 Considering how much fraudulent RTOs can cost a business, using data science to mitigate their frequency can help save an e-commerce business money over time.
Considering how much fraudulent RTOs can cost a business, using data science to mitigate their frequency can help save an e-commerce business money over time.
481. Machine Generated Whiskey
 Thanks to Microsoft, and a lot of whiskey data.
Thanks to Microsoft, and a lot of whiskey data.
482. Why FHIR Capabilities of Healthcare Data Platform is Critical to Quality and Cost of Care Delivery
 The flexibility of interoperability in the healthcare system has enhanced patient-doctor interaction to a great extent.
The flexibility of interoperability in the healthcare system has enhanced patient-doctor interaction to a great extent.
483. Introduction to Redis: The In-memory Database
 Redis is a type of database and it can be added to your production level application to make it more performant. I will cover the basics of Redis and show a real world example of Redis.
Redis is a type of database and it can be added to your production level application to make it more performant. I will cover the basics of Redis and show a real world example of Redis.
484. How to Build a Decoupled Microservice Using Materialize
 One way to handle data in microservice architectures is to use decoupled microservices architecture. This form of architecture can bring many benefits.
One way to handle data in microservice architectures is to use decoupled microservices architecture. This form of architecture can bring many benefits.
485. Go vs Rust: A Sto-array of Arrays

486. What Are The Challenges of Monetizing and Selling Data?
 There have been great advancements in monetization opportunities in the last decade, but there are still challenges when it comes to generating big data analyti
There have been great advancements in monetization opportunities in the last decade, but there are still challenges when it comes to generating big data analyti
487. It's Not Okay For Your Tax Data to Be Up for Grabs
 The article—which I co-wrote with Simon Fondrie-Teitler and Angie Waller—revealed how major tax filing services sent data to Facebook through code...
The article—which I co-wrote with Simon Fondrie-Teitler and Angie Waller—revealed how major tax filing services sent data to Facebook through code...
488. Machine Learning Trends Businesses Should Know In 2020
 Have you ever considered how much data exists in our world? Data growth has been immense since the creation of the Internet and has only accelerated in the last two decades. Today the Internet hosts an estimated 2 billion websites for 4.2 billion active users.
Have you ever considered how much data exists in our world? Data growth has been immense since the creation of the Internet and has only accelerated in the last two decades. Today the Internet hosts an estimated 2 billion websites for 4.2 billion active users.
489. Ledger Recover: What Is It and How Does It Work?
 Last night Ledger accidentally leaked some info on their new recovery subscription service, and today they revealed the details.
Last night Ledger accidentally leaked some info on their new recovery subscription service, and today they revealed the details.
490. Building a Serverless Data Pipeline to Analyze Meetup data
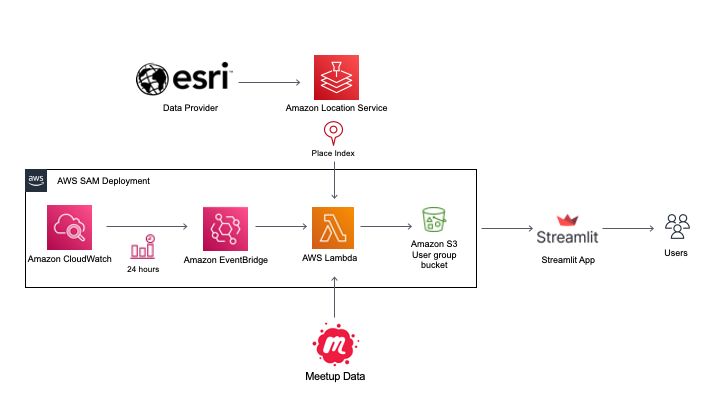 Building a Serverless Data Pipeline to Analyze Meetup data
Building a Serverless Data Pipeline to Analyze Meetup data
491. Tableau Vs. Power BI: The Complete Comparison
 The world of analytics is continually evolving, introducing new goods and adjustments to the modern market. New companies are entering the market and well-know
The world of analytics is continually evolving, introducing new goods and adjustments to the modern market. New companies are entering the market and well-know
492. How to Use Python Automatically Get the Sap BO Temporary License keys?
 Unlock the secrets of SAP Temporary License Keys with a guide on acquisition and automated retrieval using Python. Stay compliant effortlessly!
Unlock the secrets of SAP Temporary License Keys with a guide on acquisition and automated retrieval using Python. Stay compliant effortlessly!
493. An Introductory Guide to Variables and Data Types in Go
 Hello there! So today we would be learning about Go variables and the different data types associated with Go.
Hello there! So today we would be learning about Go variables and the different data types associated with Go.
494. Building an Efficient AI Platform for Data Preprocessing and Model Training
 Lei Li, AI Platform Lead, and Zifan Ni, Senior Software Engineer from Bilibili, share how they increased the training efficiency on their AI platform.
Lei Li, AI Platform Lead, and Zifan Ni, Senior Software Engineer from Bilibili, share how they increased the training efficiency on their AI platform.
495. Why Data Quality is Key to Successful ML Ops
 In this first post in our 2-part ML Ops series, we are going to look at ML Ops and highlight how and why data quality is key to ML Ops workflows.
In this first post in our 2-part ML Ops series, we are going to look at ML Ops and highlight how and why data quality is key to ML Ops workflows.
496. How to Efficiently Manage Queues in SQL Databases
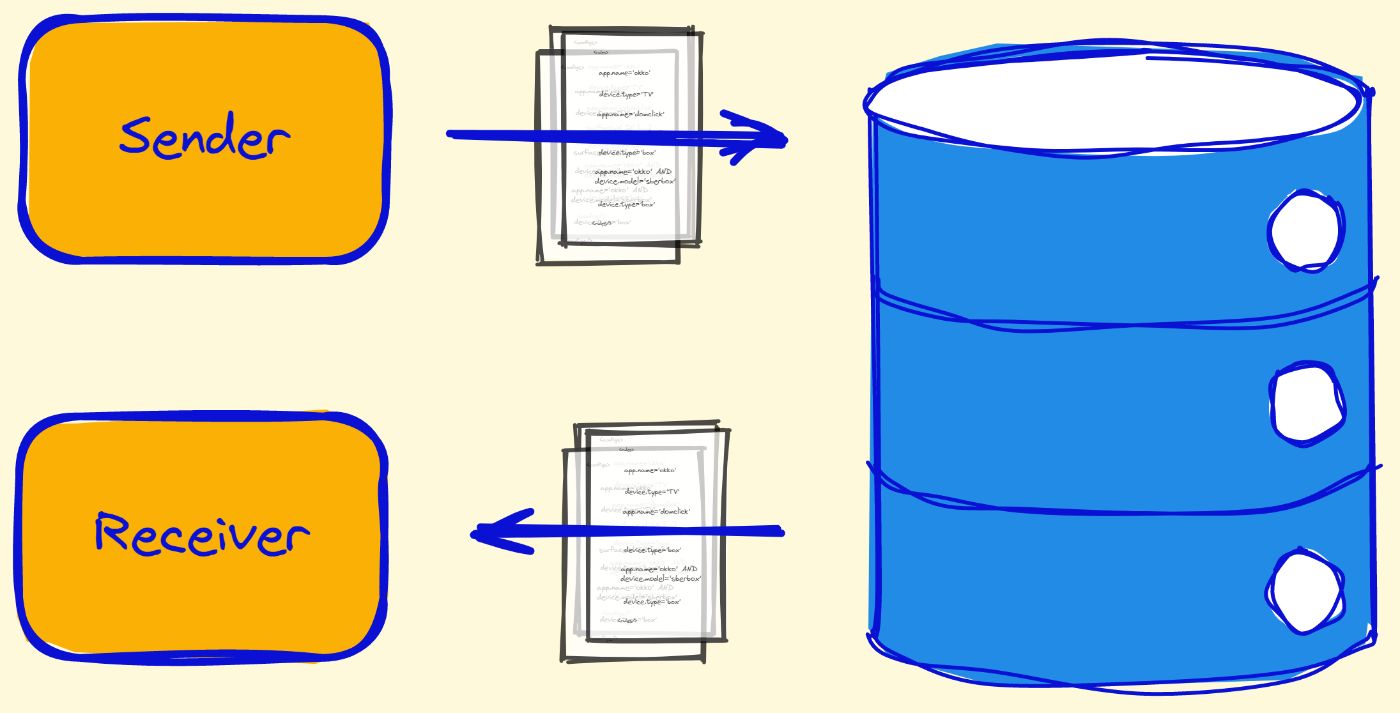 A queue using an SQL-database? well, you need to know pros and cons, and a typical implementation.
A queue using an SQL-database? well, you need to know pros and cons, and a typical implementation.
497. How Tencent uses Prometheus and Grafana to Set Up a Monitoring System in 10 Minutes
 This blog will introduce how Tencent uses Prometheus and Grafana to set up monitoring system for data platform.
This blog will introduce how Tencent uses Prometheus and Grafana to set up monitoring system for data platform.
498. "Stick 'Em Up! Give Me All Your Receipts!" - Why Everyone Wants Your Receipt Data
 When it comes to market research, marketing and advertising campaigns, and more, SKU-level receipt data is a new hot commodity.
When it comes to market research, marketing and advertising campaigns, and more, SKU-level receipt data is a new hot commodity.
499. MODEL-CENTRIC vs DATA-CENTRIC Approaches in Machine Learning
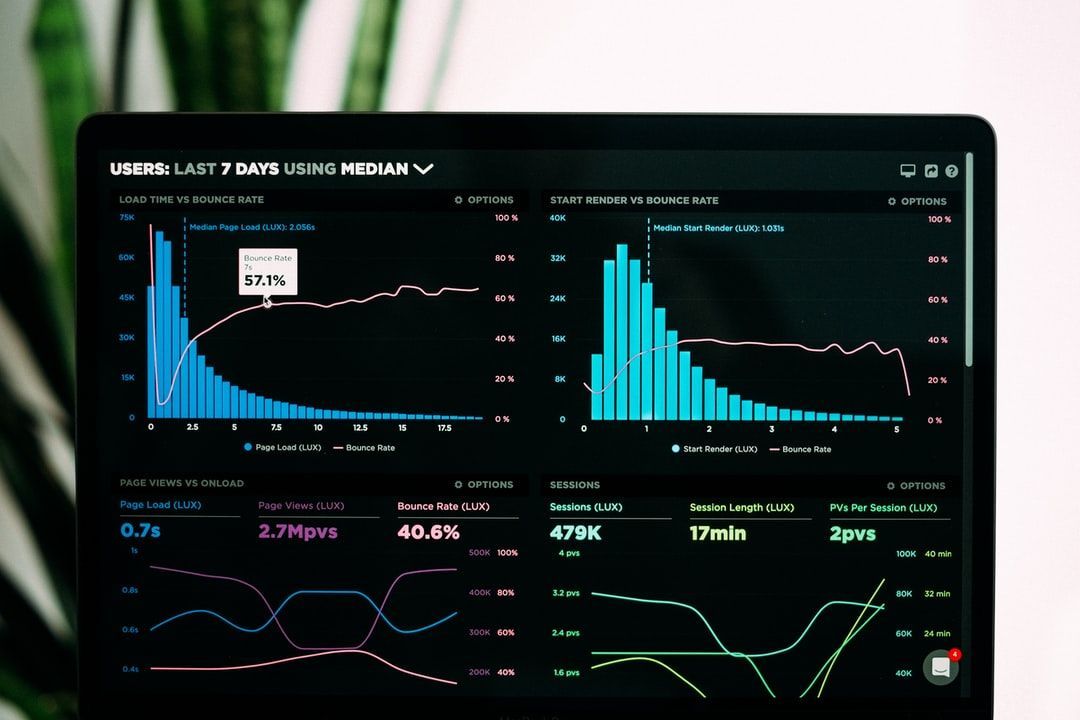 Machine learning is an area of artificial intelligence (AI) and computer science that focuses on using data and algorithms to mimic the way humans learn
Machine learning is an area of artificial intelligence (AI) and computer science that focuses on using data and algorithms to mimic the way humans learn
500. Big Tech Is Acquiring Access to Your Health & Home
 SMART HOMES: THE FINAL FRONTIER
SMART HOMES: THE FINAL FRONTIER
Thank you for checking out the 500 most read blog posts about Data on HackerNoon.
Visit the /Learn Repo to find the most read blog posts about any technology.