

Let's learn about Natural Language Processing via these 420 free blog posts. They are ordered by HackerNoon reader engagement data. Visit the Learn Repo or LearnRepo.com to find the most read blog posts about any technology.
Natural Language Processing (NLP) is a field of AI that enables computers to understand, interpret, and generate human language. NLP is crucial for tasks like machine translation, sentiment analysis, and conversational AI, bridging the gap between human communication and computational understanding.
1. Why Is GPT Better Than BERT? A Detailed Review of Transformer Architectures
 Details of Transformer Architectures Illustrated by BERT and GPT Model
Details of Transformer Architectures Illustrated by BERT and GPT Model
2. Decoding Transformers' Superiority over RNNs in NLP Tasks
![]() Explore the intriguing journey from Recurrent Neural Networks (RNNs) to Transformers in the world of Natural Language Processing in our latest piece: 'The Trans
Explore the intriguing journey from Recurrent Neural Networks (RNNs) to Transformers in the world of Natural Language Processing in our latest piece: 'The Trans
3. How to Talk to ChatGPT: An Intro to Prompt Engineering
 Prompting is pretty much the only skill you now require to be a master of these new large and powerful generative models such as ChatGPT.
Prompting is pretty much the only skill you now require to be a master of these new large and powerful generative models such as ChatGPT.
4. ChatGPT Explained in 5 Minutes
 ChatGPT has taken over Twitter and pretty much the whole internet, thanks to its power and the meme potential it provides.
ChatGPT has taken over Twitter and pretty much the whole internet, thanks to its power and the meme potential it provides.
5. NLP Datasets from HuggingFace: How to Access and Train Them
 The Datasets library from hugging Face provides a very efficient way to load and process NLP datasets from raw files or in-memory data. These NLP datasets have been shared by different research and practitioner communities across the world.
The Datasets library from hugging Face provides a very efficient way to load and process NLP datasets from raw files or in-memory data. These NLP datasets have been shared by different research and practitioner communities across the world.
6. 14 Open Datasets for Text Classification in Machine Learning
 Text classification datasets are used to categorize natural language texts according to content. For example, think classifying news articles by topic, or classifying book reviews based on a positive or negative response. Text classification is also helpful for language detection, organizing customer feedback, and fraud detection. Though time consuming when done manually, this process can be automated with machine learning models. The result saves companies time while also providing valuable data insights.
Text classification datasets are used to categorize natural language texts according to content. For example, think classifying news articles by topic, or classifying book reviews based on a positive or negative response. Text classification is also helpful for language detection, organizing customer feedback, and fraud detection. Though time consuming when done manually, this process can be automated with machine learning models. The result saves companies time while also providing valuable data insights.
7. Why Can't AI Count the Number of "R"s in the Word "Strawberry"?
 Explore why AI struggles to count letters in words like 'strawberry,' delving into tokenization, language model limitations, and potential improvements.
Explore why AI struggles to count letters in words like 'strawberry,' delving into tokenization, language model limitations, and potential improvements.
8. An Essential Python Text-to-Speech Tutorial Using the pyttsx3 Library
 Basically, what we want to do is to give some piece of text to our program and it will convert that text into the speech and will read that to us.
Basically, what we want to do is to give some piece of text to our program and it will convert that text into the speech and will read that to us.
9. How to Convert Speech to Text in Python
 Speech Recognition is the ability of a machine or program to identify words and phrases in spoken language and convert them to textual information.
Speech Recognition is the ability of a machine or program to identify words and phrases in spoken language and convert them to textual information.
10. NLP Tutorial: Creating Question Answering System using BERT + SQuAD on Colab TPU

11. How to Build GenAI Applications with Amazon Bedrock
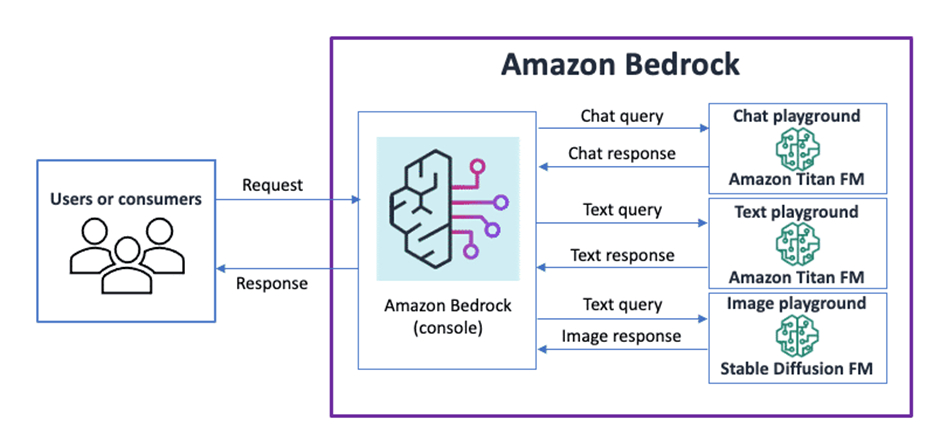 Discover how Amazon Bedrock revolutionizes Gen-AI application development by simplifying access to foundational models.
Discover how Amazon Bedrock revolutionizes Gen-AI application development by simplifying access to foundational models.
12. Open AI's ChatGPT Pricing Explained: How Much Does It Cost to Use GPT Models?
 How much does it cost to use GPT-3 in a commercial project? We ran an experiment and a project simulation based on the results.
How much does it cost to use GPT-3 in a commercial project? We ran an experiment and a project simulation based on the results.
13. How to Perform Emotion detection in Text via Python
 In this tutorial, I will guide you on how to detect emotions associated with textual data and how can you apply it in real-world applications.
In this tutorial, I will guide you on how to detect emotions associated with textual data and how can you apply it in real-world applications.
14. AI Chatbot Helps Manage Telegram Communities Like a Pro
 The Telegram chatbot will find answers to questions by extracting information from the history of chat messages.
The Telegram chatbot will find answers to questions by extracting information from the history of chat messages.
15. 5 Chatbot Ideas Businesses Should Consider in 2019
 If you are looking to add the most advanced chatbot to your website, you would have probably noticed that there are many things required to develop a chatbot.
If you are looking to add the most advanced chatbot to your website, you would have probably noticed that there are many things required to develop a chatbot.
16. Make LLM for Text Summarisation Great Again
 In recent months, LLMs have gained popularity and are now widely used in various applications. Data collection is essential for building these models, and crowd
In recent months, LLMs have gained popularity and are now widely used in various applications. Data collection is essential for building these models, and crowd
17. Creating a Domain Expert LLM: A Guide to Fine-Tuning
 In this article, we fine-tune a large language model to understand the plot of a Handel opera.
In this article, we fine-tune a large language model to understand the plot of a Handel opera.
18. Meta's New Model OPT is an Open-Source GPT-3
 We’ve all heard about GPT-3 and have somewhat of a clear idea of its capabilities. You’ve most certainly seen some applications born strictly due to this model, some of which I covered in a previous video about the model. GPT-3 is a model developed by OpenAI that you can access through a paid API but have no access to the model itself.
We’ve all heard about GPT-3 and have somewhat of a clear idea of its capabilities. You’ve most certainly seen some applications born strictly due to this model, some of which I covered in a previous video about the model. GPT-3 is a model developed by OpenAI that you can access through a paid API but have no access to the model itself.
19. 7 NLP Project Ideas to Enhance Your NLP Skills
 Learn different NLP project ideas that focus on practical implementation to help you master the NLP techniques and be able to solve different challenges.
Learn different NLP project ideas that focus on practical implementation to help you master the NLP techniques and be able to solve different challenges.
20. Getting Started with OpenAI API in JavaScript
 Learn beginner-friendly AI development using OpenAI API and JavaScript. Includes installation guide and code examples for building AI-enabled apps.
Learn beginner-friendly AI development using OpenAI API and JavaScript. Includes installation guide and code examples for building AI-enabled apps.
21. Sentiment Analysis and AI: Everything You Need to Know in 2025
 Discover how AI-powered sentiment analysis tools deliver accurate insights from customer reviews and feedback to help improve your business strategy.
Discover how AI-powered sentiment analysis tools deliver accurate insights from customer reviews and feedback to help improve your business strategy.
22. Using BERT Transformer with SpaCy3 to Train a Relation Extraction Model
 A step-by-step guide on how to train a relation extraction classifier using Transformer and spaCy3.
A step-by-step guide on how to train a relation extraction classifier using Transformer and spaCy3.
23. ChatGPD Doesn't Exist: It's ChatGPT
 ChatGPD is one of the most common misspellings of the viral language model developed by Open AI. The correct term is ChatGPT.
ChatGPD is one of the most common misspellings of the viral language model developed by Open AI. The correct term is ChatGPT.
24. Comprehensive Tutorial on Building a RAG Application Using LangChain
 Learn how to use LangChain, the massively popular framework for building RAG systems.
Learn how to use LangChain, the massively popular framework for building RAG systems.
25. How To Build and Deploy an NLP Model with FastAPI: Part 1
 Learn how to build an NLP model and deploy it with a fast web framework for building APIs called FastAPI.
Learn how to build an NLP model and deploy it with a fast web framework for building APIs called FastAPI.
26. LLMs Don't Understand Negation
 LLMs (like GPT) are really bad at following negative instructions. The post includes a demonstration, practice takeaways (prompt engineering), and some thought
LLMs (like GPT) are really bad at following negative instructions. The post includes a demonstration, practice takeaways (prompt engineering), and some thought
27. Getting Started with the Weaviate Vector Search Engine
 Everybody who works with data in any way shape or form knows that one of the most important challenges is searching for the correct answers to your questions. There is a whole set of excellent (open source) search engines available but there is one thing that they can’t do, search and related data based on context.
Everybody who works with data in any way shape or form knows that one of the most important challenges is searching for the correct answers to your questions. There is a whole set of excellent (open source) search engines available but there is one thing that they can’t do, search and related data based on context.
28. Text Classification With Zero Shot Learning
 Zero-shot text classification using trnasformers and TARSclassifier.
Zero-shot text classification using trnasformers and TARSclassifier.
29. How to Fine Tune a 🤗 (Hugging Face) Transformer Model
 How to fine-tune a Hugging Face Transformer model for Sequence Classification
How to fine-tune a Hugging Face Transformer model for Sequence Classification
30. ChatGPT is a Plague Upon Online Publications
 Ethics are a crucial part of Artificial Intelligence, which is why tech like ChatGPT must go through gruelling tests of bias.
Ethics are a crucial part of Artificial Intelligence, which is why tech like ChatGPT must go through gruelling tests of bias.
31. How to detect plagiarism in text using Python
 Intro
Intro
32. Stable Diffusion, Unstable Me: Text-to-image Generation
 Text to image generation is not a new idea. What if, you feed <your name> to a state-of-the-art image generation model?
Text to image generation is not a new idea. What if, you feed <your name> to a state-of-the-art image generation model?
33. From Chatbots to Guardians of Data: How BChat Harnesses AI for Secure Messaging
 AI is often associated with collecting personal data but what if AI helped protect user data? Read to know how BeldexAI protects your data on BChat.
AI is often associated with collecting personal data but what if AI helped protect user data? Read to know how BeldexAI protects your data on BChat.
34. AI Is Still Culturally Blind
 AI moderates content for 75% of non-English internet users with broken cultural understanding. Discover the Cultural Intelligence Standard fixing this crisis.
AI moderates content for 75% of non-English internet users with broken cultural understanding. Discover the Cultural Intelligence Standard fixing this crisis.
35. How To Compare Documents Similarity using Python and NLP Techniques
 In this post we are going to build a web application which will compare the similarity between two documents. We will learn the very basics of natural language processing (NLP) which is a branch of artificial intelligence that deals with the interaction between computers and humans using the natural language.
In this post we are going to build a web application which will compare the similarity between two documents. We will learn the very basics of natural language processing (NLP) which is a branch of artificial intelligence that deals with the interaction between computers and humans using the natural language.
36. How to Build a Multi-label NLP Classifier from Scratch
 Attacking Toxic Comments Kaggle Competition Using Fast.ai
Attacking Toxic Comments Kaggle Competition Using Fast.ai
37. How To Build An n8n Workflow To Manage Different Databases and Scheduling Workflows
 Learn how to build an n8n workflow that processes text, stores data in two databases, and sends messages to Slack.
Learn how to build an n8n workflow that processes text, stores data in two databases, and sends messages to Slack.
38. How To Build and Deploy an NLP Model with FastAPI: Part 2
 Learn how to build an NLP model and deploy it with a fast web framework for building APIs called FastAPI.
Learn how to build an NLP model and deploy it with a fast web framework for building APIs called FastAPI.
39. wav2vec2 for Automatic Speech Recognition In Plain English
 Plain English description of how Meta AI Research's wav2vec2 model works with respect to automatic speech recognition (ASR).
Plain English description of how Meta AI Research's wav2vec2 model works with respect to automatic speech recognition (ASR).
40. Sentiment Analysis with Python and AssemblyAI’s Speech Recognition API
 If you’ve never heard of Sentiment Analysis, I hadn’t either before I stumbled on it in the documentation. That’s why I thought it would be interesting to try.
If you’ve never heard of Sentiment Analysis, I hadn’t either before I stumbled on it in the documentation. That’s why I thought it would be interesting to try.
41. 10 Best Reddit Datasets for NLP and Other ML Projects
 In this post, I wanted to share a Reddit dataset list that gained a lot of traction on social media when it was first posted.
In this post, I wanted to share a Reddit dataset list that gained a lot of traction on social media when it was first posted.
42. Text Embedding Explained: How AI Understands Words
 Large language models are a specific type of machine learning-based algorithm that understand and can generate language
Large language models are a specific type of machine learning-based algorithm that understand and can generate language
43. Positional Embedding: The Secret behind the Accuracy of Transformer Neural Networks
 An article explaining the intuition behind the “positional embedding” in transformer models from the renowned research paper - “Attention Is All You Need”.
An article explaining the intuition behind the “positional embedding” in transformer models from the renowned research paper - “Attention Is All You Need”.
44. What is OpenAI's Whisper Model?
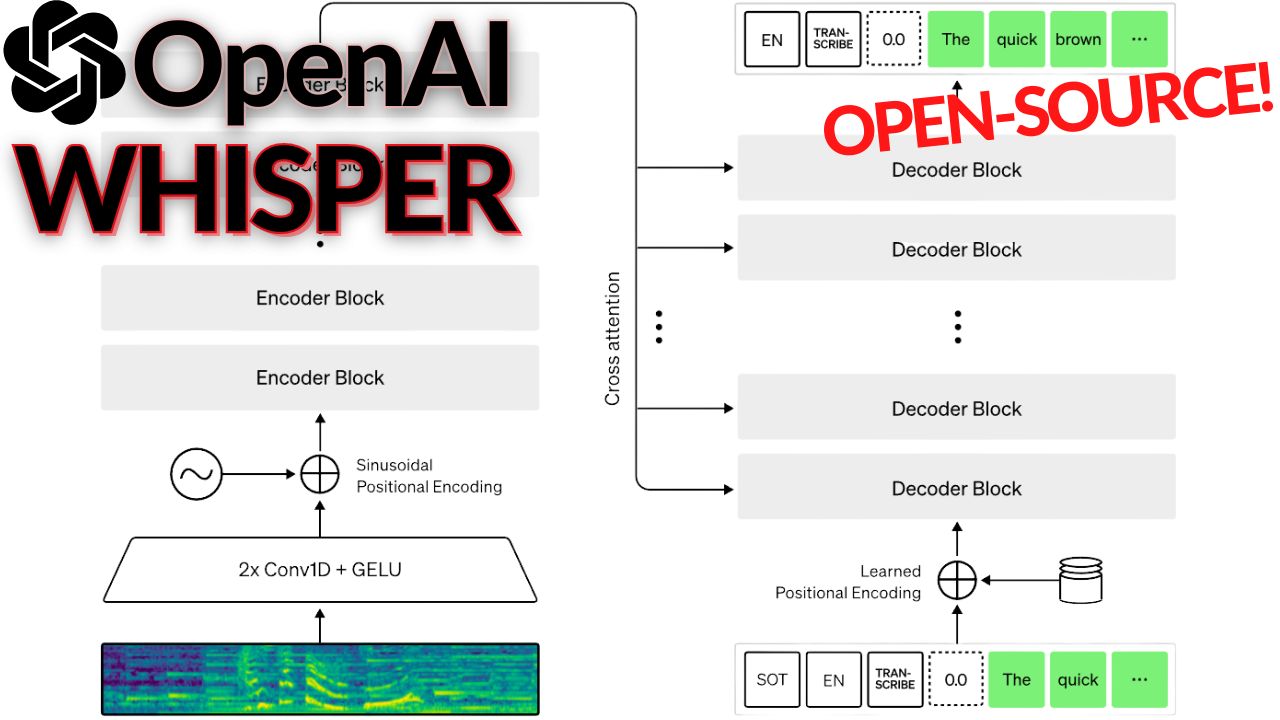 Have you ever dreamed of a good transcription tool that would accurately understand what you say and write it down? Not like the automatic YouTube translation tools… I mean, they are good but far from perfect. Just try it out and turn the feature on for the video, and you’ll see what I’m talking about.
Have you ever dreamed of a good transcription tool that would accurately understand what you say and write it down? Not like the automatic YouTube translation tools… I mean, they are good but far from perfect. Just try it out and turn the feature on for the video, and you’ll see what I’m talking about.
45. Everything You Need to Know About Google BERT
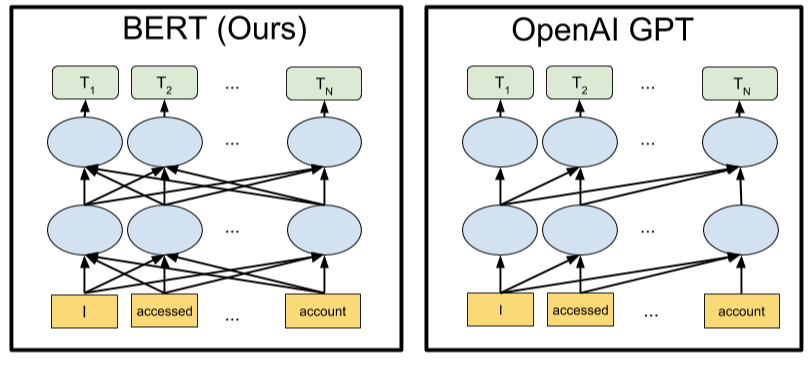 Google BERT will help you to kickstart your NLP journey by showing you how the transformer’s encoder and decoder work.
Google BERT will help you to kickstart your NLP journey by showing you how the transformer’s encoder and decoder work.
46. How to Remove Gender Bias in Machine Learning Models: NLP and Word Embeddings
 Most word embeddings used are glaringly sexist, let us look at some ways to de-bias such embeddings.
Most word embeddings used are glaringly sexist, let us look at some ways to de-bias such embeddings.
47. How to Get Started With Embeddings
 Getting started with embeddings using open-source tools.
Getting started with embeddings using open-source tools.
48. Training Your Own Text Classification Model From Scratch With Tensorflow Is As Easy As ABC

49. Can GPT-3 Finish Writing My Zombie Novel?
 My biggest worry (and excitement) is that AI will progress enough to become more creative than humans.
My biggest worry (and excitement) is that AI will progress enough to become more creative than humans.
50. How Far Are We From a Real World Jarvis?
 A Brief History of NLP Applications in the 21st Century
A Brief History of NLP Applications in the 21st Century
51. Spoken Language Understanding (SLU) vs. Natural Language Understanding (NLU)
 Differences between SLU (Spoken Language Understanding) and NLU (Natural Language Understanding). Top FOSS and paid engines and their approach to SLU.
Differences between SLU (Spoken Language Understanding) and NLU (Natural Language Understanding). Top FOSS and paid engines and their approach to SLU.
52. A Subreddit Where Only AI Chatbots Can Post
 There’s a subreddit with a called r/SubSimulator that took three years in the making and which is fully powered by bots
There’s a subreddit with a called r/SubSimulator that took three years in the making and which is fully powered by bots
53. How to Call ChatGPT with OpenAI's APIs
 Learn how Plivo is exploring the potential of ChatGPT to help automate text messaging and voice calls using OpenAI's APIs.
Learn how Plivo is exploring the potential of ChatGPT to help automate text messaging and voice calls using OpenAI's APIs.
54. ChatGPT Offers 5 Multi-Million Dollar Business Ideas Built With ChatGPT
 I wanted to ask ChatGPT about ideas worth millions of dollars. Here are the answers:
I wanted to ask ChatGPT about ideas worth millions of dollars. Here are the answers:
55. Conferencing and The Art of 'Paper Blitzing'
 There are soooo many papers in the field of machine learning, natural language processing nowadays. I’ll share the paper blitz method to "read them all".
There are soooo many papers in the field of machine learning, natural language processing nowadays. I’ll share the paper blitz method to "read them all".
56. These Politicians Are Using AI to Write Speeches
 Generative AI tools, such as Open AI’s ChatGPT, have become massively popular, even outside the world of tech.
Generative AI tools, such as Open AI’s ChatGPT, have become massively popular, even outside the world of tech.
57. AI Won't Replace Me Yet, But It Might Prove I Was Never That Original
 AI won’t replace me yet. But it might prove I was never that original. A witty, unsettling look at formulaic writing in the age of large language models.
AI won’t replace me yet. But it might prove I was never that original. A witty, unsettling look at formulaic writing in the age of large language models.
58. Natural Language Inference and NLP
 How it can give us something we hitherforto though cobblers: a computer-you-can-ask-anything!
How it can give us something we hitherforto though cobblers: a computer-you-can-ask-anything!
59. Scratching the Singularity Surface: The Past, Present and Mysterious Future of LLMs
 A brief overview of Natural Language Understanding industry and out current point of LLMs achieving human level reasoning abilities and becoming an AGI
A brief overview of Natural Language Understanding industry and out current point of LLMs achieving human level reasoning abilities and becoming an AGI
60. Large Language Models: Exploring Transformers - Part 2
 Transformer models are a type of deep learning neural network model that are widely used in Natural Language Processing (NLP) tasks.
Transformer models are a type of deep learning neural network model that are widely used in Natural Language Processing (NLP) tasks.
61. How to Use ChatGPT for Effective Sales Messaging
 ChatGPT is an ideal tool for crafting sales messages that resonate with potential customers.
ChatGPT is an ideal tool for crafting sales messages that resonate with potential customers.
62. A Deep Learning Overview: NLP vs CNN
 Artificial Intelligence is a lot more than a tech buzzword these days. This technology has disrupted almost every industry within a decade. Every company wants to implement this cutting edge technology in its system to cut costs, save time, and make the overall process more efficient with automation.
Artificial Intelligence is a lot more than a tech buzzword these days. This technology has disrupted almost every industry within a decade. Every company wants to implement this cutting edge technology in its system to cut costs, save time, and make the overall process more efficient with automation.
63. ReactJS and the Future of AI-Powered Web Components: What Will the Future Look Like?
 This article explores the benefits of using ReactJS to create intelligent web interfaces, including better user experiences and more customization possibilities
This article explores the benefits of using ReactJS to create intelligent web interfaces, including better user experiences and more customization possibilities
64. Inside Transformers: The Hidden Tech Behind LLM's and Chatbots like ChatGPT
 Transformers explained: The secret technology behind ChatGPT and how it’s reshaping AI chatbots worldwide.
Transformers explained: The secret technology behind ChatGPT and how it’s reshaping AI chatbots worldwide.
65. ELIZA: The Accidental Chatbot That Shaped AI History
 ELIZA, created by Joseph Weizenbaum, was never meant to be a chatbot. Learn how this research tool’s accidental release shaped the AI world for decades.
ELIZA, created by Joseph Weizenbaum, was never meant to be a chatbot. Learn how this research tool’s accidental release shaped the AI world for decades.
66. Natural Language Processing Is a Revolutionary Leap for Tech and Humanity: An Explanation
 Explore the fascinating world of Natural Language Processing - its history, growth, impact, future, and potential challenges. Dive into NLP now!
Explore the fascinating world of Natural Language Processing - its history, growth, impact, future, and potential challenges. Dive into NLP now!
67. What Kind of Scientist Are You?
 Data science came a long way from the early days of Knowledge Discovery in Databases (KDD) and Very Large Data Bases (VLDB) conferences.
Data science came a long way from the early days of Knowledge Discovery in Databases (KDD) and Very Large Data Bases (VLDB) conferences.
68. Getting Started with Natural Language Processing: US Airline Sentiment Analysis
 By: Comet.ml and Niko Laskaris, customer facing data scientist, Comet.ml
By: Comet.ml and Niko Laskaris, customer facing data scientist, Comet.ml
69. How to Enhance Your dbt Project With Large Language Models
 Automatically solve typical Natural Language Processing tasks for your text data using LLM for as cheap as $10 per 1M rows, staying in your dbt environment
Automatically solve typical Natural Language Processing tasks for your text data using LLM for as cheap as $10 per 1M rows, staying in your dbt environment
70. ChatGPT Writes The Great Gatsby Set in a Zombie Apocalypse
 I told OpenAI's ChatGPT model to write The Great Gatsby, but with zombies. Here's what happened...
I told OpenAI's ChatGPT model to write The Great Gatsby, but with zombies. Here's what happened...
71. How to Build a Plagiarism Checker Using Machine Learning
 Using machine learning, we can build our own plagiarism checker that searches a vast database for stolen content. In this article, we’ll do exactly that.
Using machine learning, we can build our own plagiarism checker that searches a vast database for stolen content. In this article, we’ll do exactly that.
72. How to Perform Data Augmentation in NLP Projects
 In machine learning, it is crucial to have a large amount of data in order to achieve strong model performance. Using a method known as data augmentation, you can create more data for your machine learning project. Data augmentation is a collection of techniques that manage the process of automatically generating high-quality data on top of existing data.
In machine learning, it is crucial to have a large amount of data in order to achieve strong model performance. Using a method known as data augmentation, you can create more data for your machine learning project. Data augmentation is a collection of techniques that manage the process of automatically generating high-quality data on top of existing data.
73. Softmax Temperature and Prediction Diversity
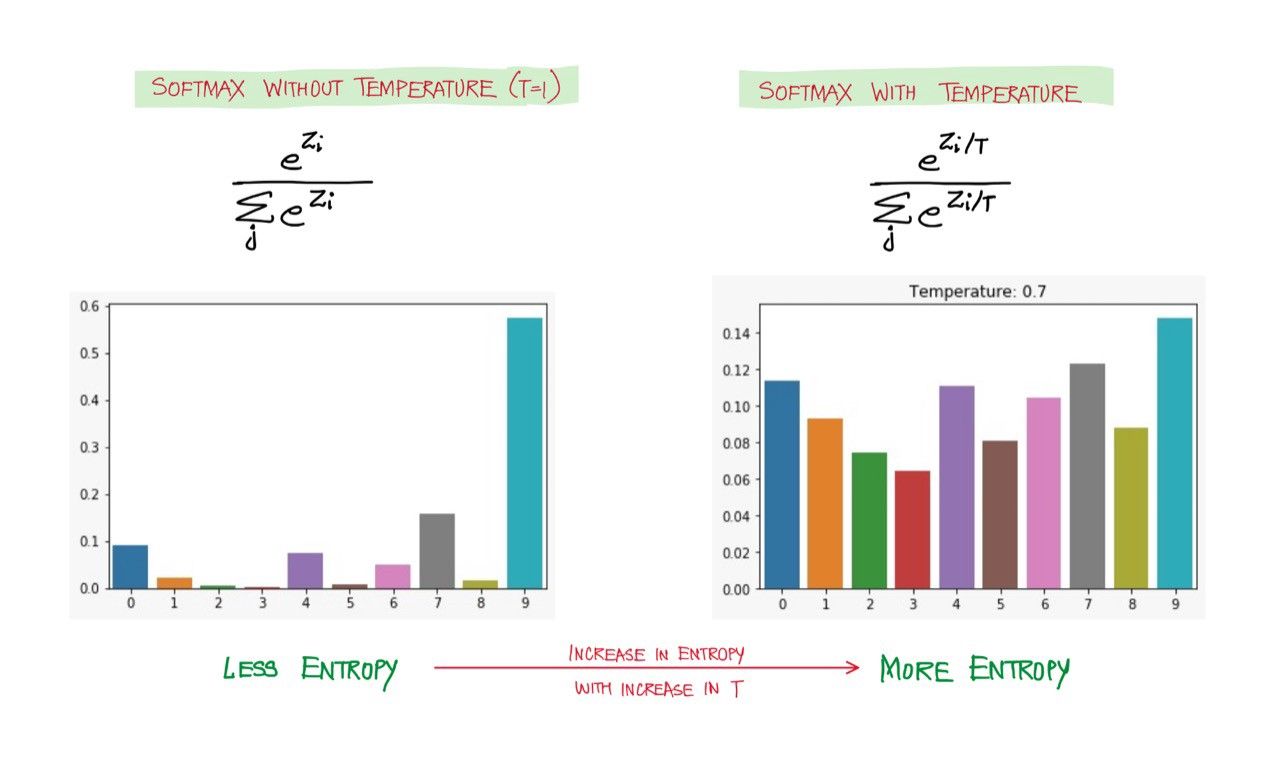 This article is about tweaking the softmax distribution to control how diverse and novel the predictions are.
This article is about tweaking the softmax distribution to control how diverse and novel the predictions are.
74. LangChain Promised an Easy AI Interface for MySQL—Here’s What It Really Took
 Learn how I built a multi-stage Langchain agent for MySQL. This article details my journey, challenges, and key steps in creating an intelligent database intera
Learn how I built a multi-stage Langchain agent for MySQL. This article details my journey, challenges, and key steps in creating an intelligent database intera
75. Common Problems with GitHub Copilot (And How to Solve Them)
 An in-depth analysis of 1,355 GitHub Copilot issues reveals key problems, causes, and solutions—and what Copilot’s team should improve next.
An in-depth analysis of 1,355 GitHub Copilot issues reveals key problems, causes, and solutions—and what Copilot’s team should improve next.
76. Behind the Scenes of an OCR Receipt and Invoice API Engine
 Find out how an accurate, adaptive and multi-lingual receipt OCR API engine works!
Find out how an accurate, adaptive and multi-lingual receipt OCR API engine works!
77. How to Build a Python Interpreter Inside ChatGPT
 You don't need an interpreter anymore!
You don't need an interpreter anymore!
78. A Beginner Guide to Incorporating Tabular Data via HuggingFace Transformers
 Transformer-based models are a game-changer when it comes to using unstructured text data. As of September 2020, the top-performing models in the General Language Understanding Evaluation (GLUE) benchmark are all BERT transformer-based models. At Georgian, we often encounter scenarios where we have supporting tabular feature information and unstructured text data. We found that by using the tabular data in these models, we could further improve performance, so we set out to build a toolkit that makes it easier for others to do the same.
Transformer-based models are a game-changer when it comes to using unstructured text data. As of September 2020, the top-performing models in the General Language Understanding Evaluation (GLUE) benchmark are all BERT transformer-based models. At Georgian, we often encounter scenarios where we have supporting tabular feature information and unstructured text data. We found that by using the tabular data in these models, we could further improve performance, so we set out to build a toolkit that makes it easier for others to do the same.
79. Meet Lettria: Our Place in the AI Revolution Begins with NLP
 While natural language processing has received tons of attention in the field of AI, generative AI is also making great strides.
While natural language processing has received tons of attention in the field of AI, generative AI is also making great strides.
80. How AI Has Changed Natural Language Processing
 How natural language processing has been revolutionized by Artificial Intelligence and how this is currently affecting businesses.
How natural language processing has been revolutionized by Artificial Intelligence and how this is currently affecting businesses.
81. Power Virtual Agents: Use GPT-3.5 to Help With Trigger Phrases and Custom Entities
 Use OpenAI Chat-GPT to help generate trigger phrases and content entities for power virtual agents.
Use OpenAI Chat-GPT to help generate trigger phrases and content entities for power virtual agents.
82. A Complete(ish) Guide to Python Tools You Can Use To Analyse Text Data
 Exploratory data analysis is one of the most important parts of any machine learning workflow and Natural Language Processing is no different.
Exploratory data analysis is one of the most important parts of any machine learning workflow and Natural Language Processing is no different.
83. The Main Patterns in Generative AI Lifecycles
 Discover the evolution and integration of generative AI in enterprise environments: from rule-based systems to large-scale real-time content generation.
Discover the evolution and integration of generative AI in enterprise environments: from rule-based systems to large-scale real-time content generation.
84. On AI Winters and What it Means for the Future
 The full history of AI winters is reviewed in great detail. The comprehensive coverage that we didn't find anywhere else.
The full history of AI winters is reviewed in great detail. The comprehensive coverage that we didn't find anywhere else.
85. B2B Sales Is Broken. New Tech Can Help
 Closing b2b deals is difficult. People are not buying aggressive selling techniques. Existing sales softwares aren't helping. New tech can help.
Closing b2b deals is difficult. People are not buying aggressive selling techniques. Existing sales softwares aren't helping. New tech can help.
86. Automated Essay Scoring Using Large Language Models
 Explore innovations in Automated Essay Scoring (AES), using models like Longformer and multi-task learning to address challenges in cohesion, grammar, and more.
Explore innovations in Automated Essay Scoring (AES), using models like Longformer and multi-task learning to address challenges in cohesion, grammar, and more.
87. How I Built a Demo App to Listen to 5000+ Hours of Joe Rogan With the Help of AI
 I’m consuming 5500+ hours of Joe Rogan with the help of AI
I’m consuming 5500+ hours of Joe Rogan with the help of AI
88. 5 Case Studies that Prove Bots Are Here to Help Businesses Scale
 It was about three years ago that Microsoft CEO, Satya Nadella, was quoted stating “Bots are the new apps,” during a 3-hour keynote to kick off the company’s Build conference. That statement has probably never been truer, especially since NLP bots Enterprise bots have appeared on the scene.
It was about three years ago that Microsoft CEO, Satya Nadella, was quoted stating “Bots are the new apps,” during a 3-hour keynote to kick off the company’s Build conference. That statement has probably never been truer, especially since NLP bots Enterprise bots have appeared on the scene.
89. This Entire Article Was Written by ChatGPT's Grandfather
 As a historical reference, here is what ChatGPT’s grandfather, GPT2 was able to produce all the way back in 2020. It’ll be interesting to compare it to what Cha
As a historical reference, here is what ChatGPT’s grandfather, GPT2 was able to produce all the way back in 2020. It’ll be interesting to compare it to what Cha
90. Artificial Intelligence is the Future, and It's Already Here
 By 2030, artificial intelligence is projected to contribute at least $15.7 trillion to the global economy.
By 2030, artificial intelligence is projected to contribute at least $15.7 trillion to the global economy.
91. Analyzing Sentiment Of Tweets Is Really Easy If You Follow This Tutorial
 Hello, Guys,
Hello, Guys,
92. Mistakes of Microsoft's New Bing: Can ChatGPT-like Generative Models Guarantee Factual Accuracy?
 We uncover several factual mistakes in Microsoft’s new Bing and Google’s Bard demonstrations, suggesting limitations in conversational AI models like ChatGPT.
We uncover several factual mistakes in Microsoft’s new Bing and Google’s Bard demonstrations, suggesting limitations in conversational AI models like ChatGPT.
93. Tools to Bypass AI Detection in 2024
 Explore AI in 2024 that bypasses detection systems, ensuring AI-generated content appears human-written.
Explore AI in 2024 that bypasses detection systems, ensuring AI-generated content appears human-written.
94. Analyzing Customer Reviews with Natural Language Processing
 In this article, we build a machine-learning model to guess the tone of customer reviews based on historical data.
In this article, we build a machine-learning model to guess the tone of customer reviews based on historical data.
95. How to Play Chess Using a GPT-2 Model
 OpenAI’s transformer-based language model GPT-2 definitely lives up to the hype. Following the natural evolution of Artificial Intelligence (AI), this generative language model drew a lot of attention by engaging in interviews and appearing in the online text adventure game AI Dungeon.
OpenAI’s transformer-based language model GPT-2 definitely lives up to the hype. Following the natural evolution of Artificial Intelligence (AI), this generative language model drew a lot of attention by engaging in interviews and appearing in the online text adventure game AI Dungeon.
96. How I Got to Top 24% on a Kaggle Text Classification Challenge Without Writing a Single Line of Code
 In this post, we will see how to use the platform and get a submission that achieves a respectable 83% Accuracy on the test set.
In this post, we will see how to use the platform and get a submission that achieves a respectable 83% Accuracy on the test set.
97. A New AI Tool Builds Knowledge Graphs So Good, They Could Rewire Scientific Discovery
 This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
98. Natural Language Processing and How it Could Improve Employee Engagement
 Internal communication and employee engagement are key when it comes to the smooth functioning of an organization and building a reputation, especially in today’s age when more and more people are opting to work remotely and teams are scattered across the world.
Internal communication and employee engagement are key when it comes to the smooth functioning of an organization and building a reputation, especially in today’s age when more and more people are opting to work remotely and teams are scattered across the world.
99. Tired of Sifting Through Science Papers? This AI Knowledge Graph Does It for You
 This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
100. 8 of the Best AI Chatbots for 2023
 Thanks to artificial intelligence and machine learning, chatbots are becoming a practical tool in the business world. This is good news for many companies, as chatbots can increase engagement, revenue and ROI. The potential of artificial intelligence is there to be harnessed, and AI-powered chatbots are examples of the effective usage of the technology. However, choosing a chatbot can be overwhelming. Let's take a look at the most popular AI chatbots currently on the market.
Thanks to artificial intelligence and machine learning, chatbots are becoming a practical tool in the business world. This is good news for many companies, as chatbots can increase engagement, revenue and ROI. The potential of artificial intelligence is there to be harnessed, and AI-powered chatbots are examples of the effective usage of the technology. However, choosing a chatbot can be overwhelming. Let's take a look at the most popular AI chatbots currently on the market.
101. The Noonification: Our World Has Become a WWE Stage (8/31/2023)
 8/31/2023: Top 5 stories on the Hackernoon homepage!
8/31/2023: Top 5 stories on the Hackernoon homepage!
102. Innovation Opportunities in Data, AI, AR, Robots, Biotech, More [Overview]
 Digital Technology is everywhere and it is redefining how we live, communicate, and work. Most importantly, it accelerates how we innovate.
Digital Technology is everywhere and it is redefining how we live, communicate, and work. Most importantly, it accelerates how we innovate.
103. Your Guide to Natural Language Processing (NLP)
 Everything we express (either verbally or in written) carries huge amounts of information. The topic we choose, our tone, our selection of words, everything adds some type of information that can be interpreted and value extracted from it. In theory, we can understand and even predict human behaviour using that information.
Everything we express (either verbally or in written) carries huge amounts of information. The topic we choose, our tone, our selection of words, everything adds some type of information that can be interpreted and value extracted from it. In theory, we can understand and even predict human behaviour using that information.
104. Content-Based Recommender Using Natural Language Processing (NLP)
 A guide to build a movie recommender model based on content-based NLP: When we provide ratings for products and services on the internet, all the preferences we express and data we share (explicitly or not), are used to generate recommendations by recommender systems. The most common examples are that of Amazon, Google and Netflix.
A guide to build a movie recommender model based on content-based NLP: When we provide ratings for products and services on the internet, all the preferences we express and data we share (explicitly or not), are used to generate recommendations by recommender systems. The most common examples are that of Amazon, Google and Netflix.
105. ChatGPT Is Making the Internet More Fun and Less Confusing
 This is a short story about the rise of ChatGPT :)
I hope you like it.
This is a short story about the rise of ChatGPT :)
I hope you like it.
106. Scientists Built a Knowledge Graph for Materials—And You Can Actually Use It
 This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
107. Is it Ethical for Media Outlets to Use AI to Write Stories?
 If media outlets are hiding their usage of AI-generated content, is it because this is ethically wrong?
If media outlets are hiding their usage of AI-generated content, is it because this is ethically wrong?
108. Importance of Sentiment Analysis as a Key Marketing Tool
 Sentiment Analytics can help your marketing team to understand the sentiment of your target audience and identify any potential issues or concerns.
Sentiment Analytics can help your marketing team to understand the sentiment of your target audience and identify any potential issues or concerns.
109. How to Make Your LLM Fully Utilize the Context
 A data-driven approach that introduces a novel pipeline to synthesize a novel dataset to train LLMs to cleverly use long contexts.
A data-driven approach that introduces a novel pipeline to synthesize a novel dataset to train LLMs to cleverly use long contexts.
110. AI Model Reads Thousands of Studies, Nails Battery Science Better Than Expected
 This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
111. Your Writing Has a Fingerprint—And This Cutting Edge AI Model Can Identify It
 Using grammatical structures from parsed text, this study explores a new method for detecting authorship, improving accuracy in AI and fake text identification.
Using grammatical structures from parsed text, this study explores a new method for detecting authorship, improving accuracy in AI and fake text identification.
112. Natural Language Processing: Explaining BERT to Business People
 <TLDR> BERT is certainly a significant step forward in the context of NLP. Business activities such as topic detection and sentiment analysis will be much easier to create and execute, and the results much more accurate. But how did you get to BERT, and how exactly does the model work? Why is it so powerful? Last but not least, what benefits it can bring to the business, and our decision to integrate it into the sandsiv+ Customer Experience platform.</TLDR>
<TLDR> BERT is certainly a significant step forward in the context of NLP. Business activities such as topic detection and sentiment analysis will be much easier to create and execute, and the results much more accurate. But how did you get to BERT, and how exactly does the model work? Why is it so powerful? Last but not least, what benefits it can bring to the business, and our decision to integrate it into the sandsiv+ Customer Experience platform.</TLDR>
113. Revamping Long Short-Term Memory Networks: XLSTM for Next-Gen AI
 XLSTMs, with novel sLSTM and mLSTM blocks, aim to overcome LSTMs' limitations and potentially surpass transformers in building next-gen language models.
XLSTMs, with novel sLSTM and mLSTM blocks, aim to overcome LSTMs' limitations and potentially surpass transformers in building next-gen language models.
114. How LinkedIn Uses NLP to Design their Help Search System
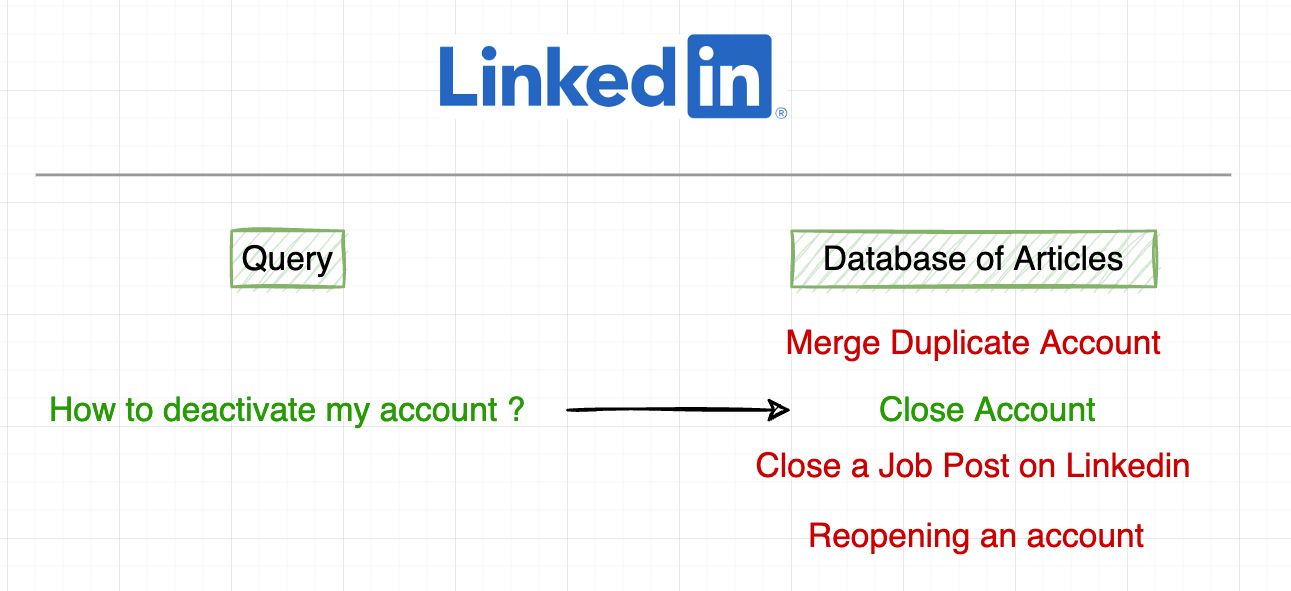 This is the summary and my key takeaways from the original post by LinkedIn on how NLP is being used (as of 2019) in designing its Help Search System.
This is the summary and my key takeaways from the original post by LinkedIn on how NLP is being used (as of 2019) in designing its Help Search System.
115. Data and Analytics Predictions for 2020 [A Top 5 List]
 It would be no exaggeration to say that the capacity of technology to advance itself is proceeding at a faster rate than our ability to process these changes all at the same time. This is both amazing and alarming in the same breath.
It would be no exaggeration to say that the capacity of technology to advance itself is proceeding at a faster rate than our ability to process these changes all at the same time. This is both amazing and alarming in the same breath.
116. Scientists Built a Smarter, Sharper Materials Graph by Teaching AI to Double-Check Its Work
 This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
117. The Rise of Text-to-Image Editing: How NLP is Changing Visual Content Creation
 Discover how AI text-to-image editing uses natural language to simplify visual content creation, boosting speed, creativity, and productivity.
Discover how AI text-to-image editing uses natural language to simplify visual content creation, boosting speed, creativity, and productivity.
118. DIY ChatGPT Plugin Connector
 How I connected an external app to ChatGPT
How I connected an external app to ChatGPT
119. Using AI to Build a Monte Carlo Simulation
 ChatGPT helps build a full Monte Carlo simulation for copula modeling—no human coding needed, just natural language and math prompts.
ChatGPT helps build a full Monte Carlo simulation for copula modeling—no human coding needed, just natural language and math prompts.
120. What is GPT-3 and Why Do We Need it?
 GPT has become a hot topic over the last few years, and with good reason. It provides a general-purpose “text in, text out” interface
GPT has become a hot topic over the last few years, and with good reason. It provides a general-purpose “text in, text out” interface
121. Scientists Built a Smart Filter for Science Papers—and It’s Cleaning Up the Data Chaos
 This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
122. Text Classification Models: All Tips And Tricks From 5 Kaggle Competitions
 In this article (originally posted by Shahul ES on the Neptune blog), I will discuss some great tips and tricks to improve the performance of your text classification model. These tricks are obtained from solutions of some of Kaggle’s top NLP competitions.
In this article (originally posted by Shahul ES on the Neptune blog), I will discuss some great tips and tricks to improve the performance of your text classification model. These tricks are obtained from solutions of some of Kaggle’s top NLP competitions.
123. Building Embodied Conversational AI: How We Taught a Robot to Understand, Navigate, and Interact
 This is exactly what I tackled in the Alexa Prize SimBot Challenge where we built an embodied conversational agent that could understand instructions
This is exactly what I tackled in the Alexa Prize SimBot Challenge where we built an embodied conversational agent that could understand instructions
124. Reflecting on AI in 2023: Magic, Hope, Innovation and Disruption
 Discover the transformative force of Artificial Intelligence. Explore the latest trends from NL to deep learning that are shaping the future of AI.
Discover the transformative force of Artificial Intelligence. Explore the latest trends from NL to deep learning that are shaping the future of AI.
125. How to Build a Text Summarizer with Gradio and Hugging Face Transformers
 Craft concise summaries like a pro: Build your text summarizer web app with Gradio and NLP magic.
Craft concise summaries like a pro: Build your text summarizer web app with Gradio and NLP magic.
126. Language Modeling - A Look at the Most Common Pre-Training Tasks
 This article is about putting all the popular pre-training tasks used in various language modelling tasks at a glance.
This article is about putting all the popular pre-training tasks used in various language modelling tasks at a glance.
127. Subtitles for Living: AR's Role in Language Translation
 AR shines when our relationship with technology becomes more intuitive and in 2022, emerging AR capabilities are taking language translation a step further.
AR shines when our relationship with technology becomes more intuitive and in 2022, emerging AR capabilities are taking language translation a step further.
128. This AI Reads Science Papers Like a Pro, Even When Humans Can’t Agree on the Words
 This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
129. AI Dungeon: An AI-Generated Adventure Game by Nick Walton
 The original AI Dungeon was made just over a year ago, the result of a curious gamer, a hackathon, and the GPT-2 text transformer. Fast forward to the present day, and AI Dungeon has expanded into a unique example of creative AI technology. The game now boasts 1.5 million players, multiple genres for stories, and even multiplayer adventures.
The original AI Dungeon was made just over a year ago, the result of a curious gamer, a hackathon, and the GPT-2 text transformer. Fast forward to the present day, and AI Dungeon has expanded into a unique example of creative AI technology. The game now boasts 1.5 million players, multiple genres for stories, and even multiplayer adventures.
130. Developing a Natural Language Understanding Model to Characterize Cable News Bias
 The increasing trend of political polarization in the U.S. is reflected in media consumption patterns that indicate partisan polarization.
The increasing trend of political polarization in the U.S. is reflected in media consumption patterns that indicate partisan polarization.
131. Researchers Build AI Knowledge Graph That Sifts Through Science Papers For You
 This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
132. The Ten Must Read NLP/NLU Papers from the ICLR 2020 Conference
 The International Conference on Learning Representations (ICLR) took place last week, and I had a pleasure to participate in it. ICLR is an event dedicated to research on all aspects of representation learning, commonly known as deep learning. This year the event was a bit different as it went virtual. However, the online format didn’t change the great atmosphere of the event. It was engaging and interactive and attracted 5600 attendees (twice as many as last year). If you’re interested in what organizers think about the unusual online arrangement of the conference, you can read about it here.
The International Conference on Learning Representations (ICLR) took place last week, and I had a pleasure to participate in it. ICLR is an event dedicated to research on all aspects of representation learning, commonly known as deep learning. This year the event was a bit different as it went virtual. However, the online format didn’t change the great atmosphere of the event. It was engaging and interactive and attracted 5600 attendees (twice as many as last year). If you’re interested in what organizers think about the unusual online arrangement of the conference, you can read about it here.
133. This AI Doesn’t Just Skim Scientific Papers—It Tags, Sorts, and Explains Them Too
 This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
This paper presents a new AI-powered knowledge graph that organizes real-world materials science research into an accessible, searchable database.
134. Is AI Affecting Your Business? Here's How To Make it Work For You Not Against You

135. What to do When Reviewing Academic Papers
 Academic paper reviews is a necessary civic duty for researchers in all fields, humanities, science, engineering or anything in between.
Academic paper reviews is a necessary civic duty for researchers in all fields, humanities, science, engineering or anything in between.
136. 6 Emerging Technologies Product Managers Need To Master By 2026
 There are quite a number of technologies to keep abreast with. But the good news is that these 6 emerging technologies will make you valuable.
There are quite a number of technologies to keep abreast with. But the good news is that these 6 emerging technologies will make you valuable.
137. CLIP: An Innovative Aqueduct Between Computer Vision and NLP
 A rudimentary article describing the concept behind the "CLIP" algorithm in deep learning, its approach, implementation, scope & limitations.
A rudimentary article describing the concept behind the "CLIP" algorithm in deep learning, its approach, implementation, scope & limitations.
138. The Basics Of Natural Language Processing in 10 Minutes
 Do you also want to learn NLP as Quick as Possible ? Perhaps you are here because you also want to learn natural language processing as quickly as possible, like me.
Do you also want to learn NLP as Quick as Possible ? Perhaps you are here because you also want to learn natural language processing as quickly as possible, like me.
139. Building a Job Entity Recognizer Using Amazon Comprehend - A How-To Guide
 With the advent of Natural Language Processing (NLP), traditional job searches based on static keywords are becoming less desirable because of their inaccuracy and will eventually become obsolete. While the traditional search engine performs simple keyword searches, the NLP based search engine extract named entities, key phrases, sentiment, etc. to enrich the documents with metadata and perform search query based on the extracted metadata. In this tutorial, we will build a model to extract entities, such as skills, diploma and diploma major, from job descriptions using Named Entity Recognition (NER).
With the advent of Natural Language Processing (NLP), traditional job searches based on static keywords are becoming less desirable because of their inaccuracy and will eventually become obsolete. While the traditional search engine performs simple keyword searches, the NLP based search engine extract named entities, key phrases, sentiment, etc. to enrich the documents with metadata and perform search query based on the extracted metadata. In this tutorial, we will build a model to extract entities, such as skills, diploma and diploma major, from job descriptions using Named Entity Recognition (NER).
140. Code Book for Annotation of Diverse Cross-Document Coreference: Annotation Guidelines
 This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
141. New Framework Simplifies Comparison of Language Processing Tools Across Multiple Languages
 Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
142. Shakespeare Meets Google's Flax
 Some are born great, some achieve greatness, and some have greatness thrust upon them.
Some are born great, some achieve greatness, and some have greatness thrust upon them.
William Shakespeare, Twelfth Night, or What You Will
143. GPTerm: Creating Intelligent Terminal Apps with ChatGPT and LLM Models
 In this article, the exciting realm of making terminal applications smarter is delved into by integrating ChatGPT, a cutting-edge language model.
In this article, the exciting realm of making terminal applications smarter is delved into by integrating ChatGPT, a cutting-edge language model.
144. LLMs Excel in NLP: Enabling Sophisticated Search Functionalities in E-commerce Platforms
 Provide exceptional shopping experiences, businesses must leverage the power of LLMs as the e-commerce industry continues to evolve.
Provide exceptional shopping experiences, businesses must leverage the power of LLMs as the e-commerce industry continues to evolve.
145. How I Built a Python Pipeline to Analyze 16,695 Arabic Tweets on X
 analyzing 16,695 Python pipeline Arabic tweets from X to detect linguistic uncertainty and examine how language influences social media engagement.
analyzing 16,695 Python pipeline Arabic tweets from X to detect linguistic uncertainty and examine how language influences social media engagement.
146. Introductory Guide to Automatic Language Translation in Python
 Today, I'm going to share with you guys how to automatically perform language translation in Python programming.
Today, I'm going to share with you guys how to automatically perform language translation in Python programming.
147. 11 Proven Solutions to Common GitHub Copilot Problems
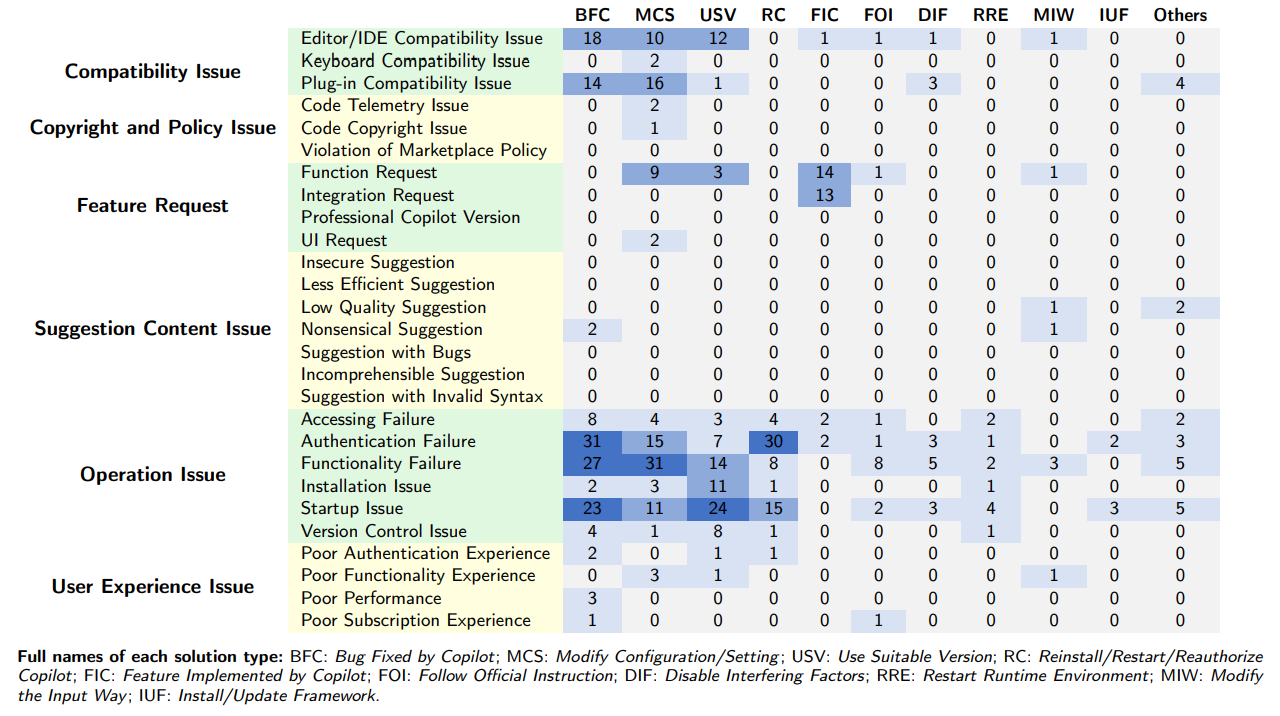 Discover 11 solution types used to fix GitHub Copilot problems—based on 497 real cases across bugs, settings, versions, features, and more.
Discover 11 solution types used to fix GitHub Copilot problems—based on 497 real cases across bugs, settings, versions, features, and more.
148. Top 6 Applications of Natural Language Processing in Healthcare
 For many healthcare providers, the industry is shaping up to be more of a shifting quandary of regulatory issues, financial turmoil, and unforeseeable eruptions of resentment from practitioners on the edge of revolt. The industry is now taking the opportunity to scale up their big data defenses and develop the technological infrastructure required to meet the imminent challenges.
For many healthcare providers, the industry is shaping up to be more of a shifting quandary of regulatory issues, financial turmoil, and unforeseeable eruptions of resentment from practitioners on the edge of revolt. The industry is now taking the opportunity to scale up their big data defenses and develop the technological infrastructure required to meet the imminent challenges.
149. The Hitchhikers's Guide to PyTorch for Data Scientists
 PyTorch has sort of became one of the de facto standard for creating Neural Networks now, and I love its interface. Yet, it is somehow a little difficult for beginners to get a hold of.
PyTorch has sort of became one of the de facto standard for creating Neural Networks now, and I love its interface. Yet, it is somehow a little difficult for beginners to get a hold of.
150. What Is Conversational AI: Principles and Examples
 In this article, we will take the time to explain what conversational AI is: principles and examples to have a better idea of how you can implement it.
In this article, we will take the time to explain what conversational AI is: principles and examples to have a better idea of how you can implement it.
151. Diverse Cross-document Coreference and Media Bias Analysis
 This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
152. 5 Trends Shaping the Future of Data Analytics and Insights
 Discover the 5 key trends shaping the future of data analytics—from synthetic data to NLP, data interoperability, data storytelling, and new data-centric roles.
Discover the 5 key trends shaping the future of data analytics—from synthetic data to NLP, data interoperability, data storytelling, and new data-centric roles.
153. NO! GPT-3 Will Not Steal Your Programming Job
 TL;DR; GPT-3 will not take your programming job (Unless you are a terrible programmer, in which case you would have lost your job anyway)
TL;DR; GPT-3 will not take your programming job (Unless you are a terrible programmer, in which case you would have lost your job anyway)
154. Code Book for Annotation of Diverse Cross-Document Coreference: Acknowledgements
 This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
155. Code Book for Annotation of Diverse Cross-Document Coreference: Bibliographical References
 This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
156. Code Book for Annotation of Diverse Cross-Document Coreference: Abstract and Intro
 This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
157. How Do Chatbots Work in Call Centers?
 Machine learning technologies help to significantly reduce the cost of providing services, as well as increase the efficiency of call centers.
Machine learning technologies help to significantly reduce the cost of providing services, as well as increase the efficiency of call centers.
158. 15 Must-read Machine Learning Articles for Data Scientists
 As always, the fields of deep learning and natural language processing are as busy as ever. Despite many industries being hindered by the quarantine restrictions in many countries, the machine learning industry continues to move forward.
As always, the fields of deep learning and natural language processing are as busy as ever. Despite many industries being hindered by the quarantine restrictions in many countries, the machine learning industry continues to move forward.
159. Automating Multilingual Customer Service with Power Virtual Agent and Azure Cognitive Services
 PVA is getting better with each release, but there are situations where you can use Azure Services to improve your user's experience. Here's one such example!
PVA is getting better with each release, but there are situations where you can use Azure Services to improve your user's experience. Here's one such example!
160. Converting Epics/Stories into Pseudocode using Transformers
 Automate Agile development with an NLP-based methodology to convert user stories into pseudocode, enhancing efficiency and reducing project time.
Automate Agile development with an NLP-based methodology to convert user stories into pseudocode, enhancing efficiency and reducing project time.
161. A Novel Method for Analysing Racial Bias: Collection of Person Level References: Analysis and Result
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
162. Cutting AI Costs Without Losing Capability: The Rise of Small Language Models
 Learn how small language models are helping teams cut AI costs, run locally, and deliver fast, private, and scalable intelligence.
Learn how small language models are helping teams cut AI costs, run locally, and deliver fast, private, and scalable intelligence.
163. A Novel Method for Analysing Racial Bias: Collection of Person Level References: Appendix: Wikidata
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
164. A New Era for Procurement Text Mining
 Exploring NLP for healthcare procurement, this study offers insights, challenges, and recommendations for practical, domain-specific text mining solutions.
Exploring NLP for healthcare procurement, this study offers insights, challenges, and recommendations for practical, domain-specific text mining solutions.
165. Building a Metaverse For Everyone

166. Another Wave: A BASIC ELIZA Turns the PC Generation On to AI
 In 1977, a BASIC version of ELIZA captivated personal computer users, spreading AI curiosity during the PC explosion, while the original MAD-SLIP ELIZA faded.
In 1977, a BASIC version of ELIZA captivated personal computer users, spreading AI curiosity during the PC explosion, while the original MAD-SLIP ELIZA faded.
167. Code Book for Annotation of Diverse Cross-Document Coreference: Annotation Tool
 This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
168. How to Build a Twitter Sentiment Analysis System
 Understanding the sentiment of tweets is important for a variety of reasons: business marketing, politics, public behavior analysis, and information gathering are just a few examples. Sentiment analysis of twitter data can help marketers understand the customer response to product launches and marketing campaigns, and it can also help political parties understand the public response to policy changes or announcements.
Understanding the sentiment of tweets is important for a variety of reasons: business marketing, politics, public behavior analysis, and information gathering are just a few examples. Sentiment analysis of twitter data can help marketers understand the customer response to product launches and marketing campaigns, and it can also help political parties understand the public response to policy changes or announcements.
169. Cocktail Alchemy: Creating New Recipes With Transformers
 Build a transformer model with natural language processing to create new cocktail recipes from a cocktail database.
Build a transformer model with natural language processing to create new cocktail recipes from a cocktail database.
170. Text Classification in iOS using tensorflowlite [A How-To Guide]
 Text classification is task of categorising text according to its content. It is the fundamental problem in the field of Natural Language Processing(NLP). More general applications of text classifications are in email spam detection, sentiment analysis and topic labelling etc.
Text classification is task of categorising text according to its content. It is the fundamental problem in the field of Natural Language Processing(NLP). More general applications of text classifications are in email spam detection, sentiment analysis and topic labelling etc.
171. Biomedical Knowledge Graphs and Question Answering Systems
 Learn how knowledge graphs and NLP enable question answering in biomedicine, aiding researchers and doctors with organized data (COVID-19, EHR examples).
Learn how knowledge graphs and NLP enable question answering in biomedicine, aiding researchers and doctors with organized data (COVID-19, EHR examples).
172. I Got Cancer, my Doctors Gave up on my Quality of Life, I Built an AI-app to Help Myself and Others
 Suneeta Modekurty wanted to help cancer survivors regain control over their health through personalized, data-backed recommendations.
Suneeta Modekurty wanted to help cancer survivors regain control over their health through personalized, data-backed recommendations.
173. Biomedical NLP: Text Generation & Knowledge Reasoning Tasks
 Discover NLP tasks in biomedicine: question/dialogue generation (CHIP, CCKS), medical reading comprehension, and diagnostic reasoning (CCL, CHIP).
Discover NLP tasks in biomedicine: question/dialogue generation (CHIP, CCKS), medical reading comprehension, and diagnostic reasoning (CCL, CHIP).
174. A Novel Method for Analysing Racial Bias: Appendix: Hyperparameter Sensitivity
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
175. What Happens to Mobile Apps When AI and Machine Learning Join Forces?
 A model can take into consideration a lot more parameters than the human brain.
A model can take into consideration a lot more parameters than the human brain.
176. How a natural gas company is using machine learning in natural gas exploration
 The modern business world is becoming increasingly technology-driven and machine learning (MD) is currently at the forefront. While one might not inherently in
The modern business world is becoming increasingly technology-driven and machine learning (MD) is currently at the forefront. While one might not inherently in
177. Maximizing NLP Capabilities with Large Language Models
 While NLP effectively facilitates machines to understand human language, the LLM capabilities have been greatly enhanced. Read this blog post to learn more.
While NLP effectively facilitates machines to understand human language, the LLM capabilities have been greatly enhanced. Read this blog post to learn more.
178. Top Tips For Competing in a Kaggle Competition
 Hi, my name is Prashant Kikani and in this blog post, I share some tricks and tips to compete in Kaggle competitions and some code snippets which help in achieving results in limited resources. Here is my Kaggle profile.
Hi, my name is Prashant Kikani and in this blog post, I share some tricks and tips to compete in Kaggle competitions and some code snippets which help in achieving results in limited resources. Here is my Kaggle profile.
179. Understanding and Generating Dialogue between Characters in Stories: Abstract and Intro
 Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
180. Future Perspectives in the Era of Large Language Models, and References
 Explore future perspectives for enhancing biomedical text mining community challenges in the era of large language models.
Explore future perspectives for enhancing biomedical text mining community challenges in the era of large language models.
181. Neural Entity Linking and How JPMorgan Chase Plans to Use it
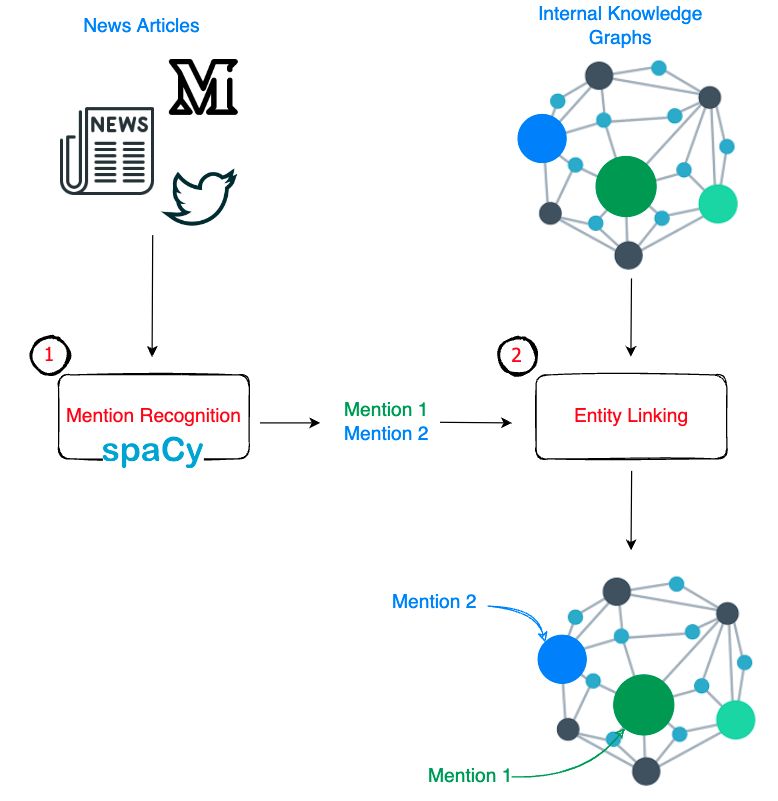 This article summarizes the problem statement, solution, and other key technical components of the paper: End-to-End Neural Entity Linking in JP Morgan Chase
This article summarizes the problem statement, solution, and other key technical components of the paper: End-to-End Neural Entity Linking in JP Morgan Chase
182. How I Extracted Meaningful Information from Inconsistent Data Using ChatGPT
 Data Analyis Project using Spacy and Regular Expressions to extract specific strings from a data set.
Data Analyis Project using Spacy and Regular Expressions to extract specific strings from a data set.
183. The Impact of AI Transformers on the Customer Experience
 I have spent the last few weeks understanding the impact of a great revolution in the world of Artificial Intelligence and NLP on the customer experience. Not from a purely technical point of view, but trying to estimate the competitive advantage that this new approach can generate. We are facing yet another disruptive innovation, and it can bring significant advantages, let's try to find out which ones.
I have spent the last few weeks understanding the impact of a great revolution in the world of Artificial Intelligence and NLP on the customer experience. Not from a purely technical point of view, but trying to estimate the competitive advantage that this new approach can generate. We are facing yet another disruptive innovation, and it can bring significant advantages, let's try to find out which ones.
184. Nir Eyal Discusses Becoming 'Indistractable,' Time Management, Focus and ChatGPT
 The emergence of ChatGPT has stirred major buzz around the world and massive disruptions across multiple industries.
The emergence of ChatGPT has stirred major buzz around the world and massive disruptions across multiple industries.
185. Improving LLM Performance with Self-Consistency and Self-Check
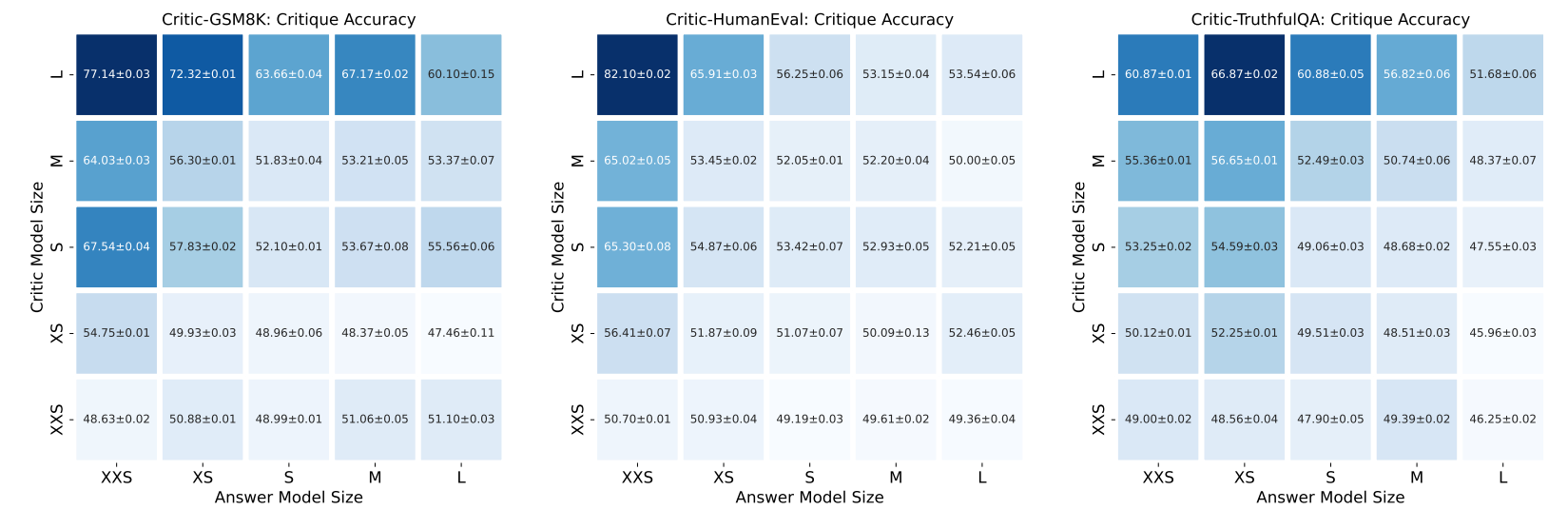 Can AI critique itself? This study shows how self-check improves ChatGPT, GPT-4, and PaLM-2 accuracy on benchmark tasks.
Can AI critique itself? This study shows how self-check improves ChatGPT, GPT-4, and PaLM-2 accuracy on benchmark tasks.
186. Checking If Your Headline A Clickbait: A How-To Guide
 For those who don’t know what that is… It is basically a magical tool that allows anyone to take existing AI models and train them for their own data, however, small the dataset maybe. Sounds good, right?
For those who don’t know what that is… It is basically a magical tool that allows anyone to take existing AI models and train them for their own data, however, small the dataset maybe. Sounds good, right?
187. Limitations of Current Biomedical Text Mining Community Challenges
 Explore the shortcomings of current community challenge evaluation tasks in biomedical text mining, including data representativeness and innovation
Explore the shortcomings of current community challenge evaluation tasks in biomedical text mining, including data representativeness and innovation
188. Answering Whither Artificial Intelligence By Building A Bot
 During one of our call with Yardy, discussing our next venture, we thought about implementing AI to streamline certain functions. Given that I had some experience with Machine Learning, our fund had a project aiming to evaluate ICOs & Coins on specific criteria.
During one of our call with Yardy, discussing our next venture, we thought about implementing AI to streamline certain functions. Given that I had some experience with Machine Learning, our fund had a project aiming to evaluate ICOs & Coins on specific criteria.
189. The Art of Transformers: How AI Intuitively Summarizes Business Papers Using NLP
 “I don’t want a full paper, just give me a concise summary of it”. Who hasn't found themselves in this situation, at least once? Sound familiar?
“I don’t want a full paper, just give me a concise summary of it”. Who hasn't found themselves in this situation, at least once? Sound familiar?
190. ELIZA Reinterpreted: The World’s First Chatbot Was Not Intended as a Chatbot at All
 The world's first chatbot, ELIZA, wasn't built to be a chatbot. Learn what its creator, Weizenbaum, designed it for.
The world's first chatbot, ELIZA, wasn't built to be a chatbot. Learn what its creator, Weizenbaum, designed it for.
191. Evidence That AI Will Soon Pass the Turing Test (or maybe it already has)
 You might be wondering if machines are a threat to the world we live in, or if they’re just another tool in our quest to improve ourselves. If you think that AI is just another tool, you might be surprised to hear that some of the biggest names in technology have a clear concern for it. As Mark Ralston wrote, “The great fear of machine intelligence is that it may take over our jobs, our economies, and our governments”.
You might be wondering if machines are a threat to the world we live in, or if they’re just another tool in our quest to improve ourselves. If you think that AI is just another tool, you might be surprised to hear that some of the biggest names in technology have a clear concern for it. As Mark Ralston wrote, “The great fear of machine intelligence is that it may take over our jobs, our economies, and our governments”.
192. The Accidental AI: How ELIZA's Lisp Adaptation Derailed Its Original Research Intent
 Explore how in an ironic twist ELIZA's Lisp adaptation overshadowed its original intent as a research platform, leading to widespread misinterpretation.
Explore how in an ironic twist ELIZA's Lisp adaptation overshadowed its original intent as a research platform, leading to widespread misinterpretation.
193. The High Cost of Training Data in NLP Projects
 Explore the high cost of training data in NLP projects, comparing supervised vs. rule-based methods and highlighting practicality in industry contexts.
Explore the high cost of training data in NLP projects, comparing supervised vs. rule-based methods and highlighting practicality in industry contexts.
194. Introducing aasaan.ai: No-Code Yelp Sentiment Classification
 Introduction
Introduction
195. AI's Role In Language Learning: Stuart Barrass, Kaizen Languages CEO
 We spoke with Stuart Barrass, CEO and Co-founder of Kaizen Languages, a startup that helps people with language aquisition through AI-Driven conversations.
We spoke with Stuart Barrass, CEO and Co-founder of Kaizen Languages, a startup that helps people with language aquisition through AI-Driven conversations.
196. Semantic Textual Similarity: Here's How It's Changing the Game
 In this case, however, genuine game-changing is occurring, as STS fundamentally improves search engine and recommendation system accuracy and relevance.
In this case, however, genuine game-changing is occurring, as STS fundamentally improves search engine and recommendation system accuracy and relevance.
197. How to Analyze Call Sentiment With Open-Source NLP Libraries
 Unlock call sentiment analysis using open-source NLP. Discover how to analyze customer emotions, improve service, and gain valuable insights from voice data.
Unlock call sentiment analysis using open-source NLP. Discover how to analyze customer emotions, improve service, and gain valuable insights from voice data.
198. Natural Language Processing in Healthcare: A Path to Adoption
 Whether you already have experience with AI or not, implementing natural language processing in healthcare can take some of the load off your employees’ .......
Whether you already have experience with AI or not, implementing natural language processing in healthcare can take some of the load off your employees’ .......
199. The Intelligence Engineers: How Turing and Lovelace Laid the Foundations for AI's Future
 Explore how Turing and Lovelace shaped the early foundations of AI, from the Turing Machine to symbolic computing, setting the stage for innovations like ELIZA.
Explore how Turing and Lovelace shaped the early foundations of AI, from the Turing Machine to symbolic computing, setting the stage for innovations like ELIZA.
200. A Brief Introduction to Statistical Parsing
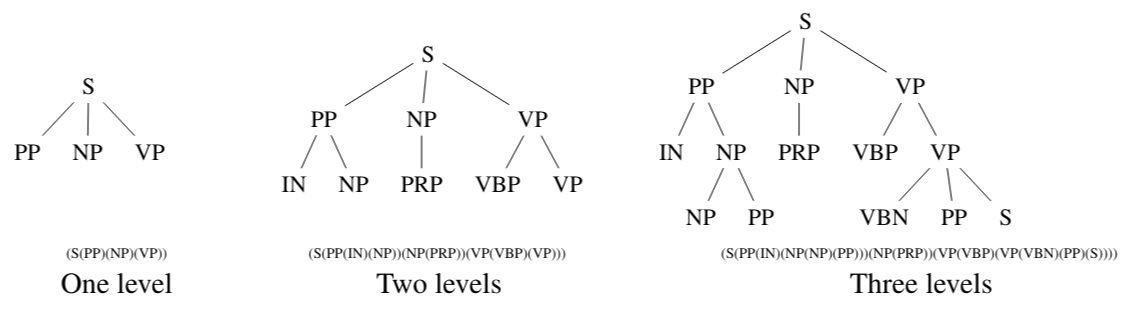 This intro to statistical parsing explains how probabilistic context-free grammard help decipher sentence structures, a key tool in authorship identification
This intro to statistical parsing explains how probabilistic context-free grammard help decipher sentence structures, a key tool in authorship identification
201. Biomedical Text Classification & Similarity: CHIP/CCKS Tasks
 Explore biomedical text classification (CHIP) and similarity (CCKS) for clinical trials, patient data, and medical knowledge matching.
Explore biomedical text classification (CHIP) and similarity (CCKS) for clinical trials, patient data, and medical knowledge matching.
202. Figure Legends and Tables for Our Biomedical Text Mining Research
![]() The distribution of data sources, organizations, and artificial intelligence tasks in Chinese biomedical text mining community challenges.
The distribution of data sources, organizations, and artificial intelligence tasks in Chinese biomedical text mining community challenges.
203. The Potential Advantages Einstein GPT Could Give to Developers
 Salesforce's Einstein GPT can significantly benefit developers by providing a powerful natural language processing (NLP) tool that streamlines various tasks and improves efficiency.
Salesforce's Einstein GPT can significantly benefit developers by providing a powerful natural language processing (NLP) tool that streamlines various tasks and improves efficiency.
204. The Impact of Community Challenges on Biomedical Text Mining Research
 Explore the significant contributions of community challenges to biomedical text mining, from data standards to translational applications and tech advancements
Explore the significant contributions of community challenges to biomedical text mining, from data standards to translational applications and tech advancements
205. Translational Informatics & Biomedical Text Mining: Bridging Research to Practice
 Discover how translational informatics utilizes biomedical text mining and NLP to connect research findings with real-world clinical applications.
Discover how translational informatics utilizes biomedical text mining and NLP to connect research findings with real-world clinical applications.
206. Newell, Shaw, and Simon’s IPL Logic Theorist: The First True AIs
 Discover how the IPL programming language, created by Newell, Shaw, and Simon, laid the foundation for early AI development.
Discover how the IPL programming language, created by Newell, Shaw, and Simon, laid the foundation for early AI development.
207. How Banks are Damaging their Business by Misusing Chatbots
 The US State of Multichannel Customer Service, found two-thirds of customers are frustrated with companies before they speak with agents.
The US State of Multichannel Customer Service, found two-thirds of customers are frustrated with companies before they speak with agents.
208. The Abstraction and Reasoning Corpus (ARC): Why It's Important
 The Abstraction and Reasoning Corpus (ARC) is a challenging benchmark, introduced to foster AI research towards human-level intelligence
The Abstraction and Reasoning Corpus (ARC) is a challenging benchmark, introduced to foster AI research towards human-level intelligence
209. How Developers Struggle with Copilot (And What GitHub Has Fixed)
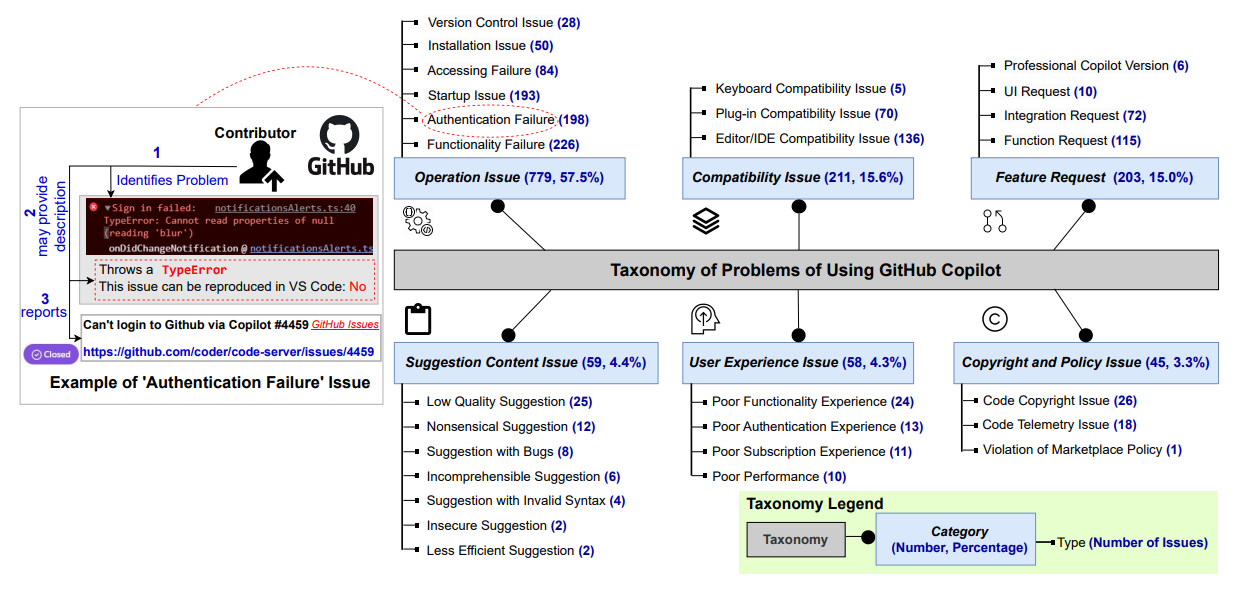 Explore 1,355 GitHub Copilot issues categorized by type, cause, and fix—plus insight into feature requests and what’s been resolved by GitHub.
Explore 1,355 GitHub Copilot issues categorized by type, cause, and fix—plus insight into feature requests and what’s been resolved by GitHub.
210. A Novel Method for Analysing Racial Bias: Appendix: Toxicity Measurement
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
211. Deep Syntax and Dead Founders: How AI Deciphered The Federalist Papers
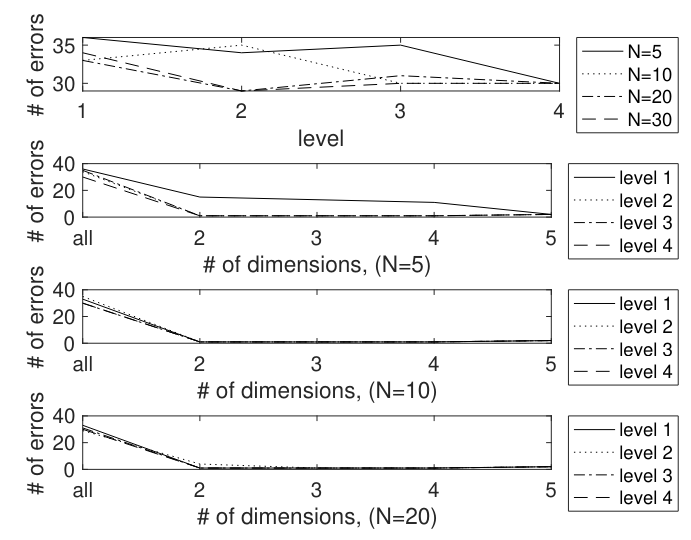 This study applies statistical parsing to The Federalist Papers, leveraging syntactic structures to distinguish authorship with high accuracy.
This study applies statistical parsing to The Federalist Papers, leveraging syntactic structures to distinguish authorship with high accuracy.
212. Creating a Systematic ESG Scoring System: Abstract and Introduction
 This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
213. I Got Close to Winning an NLP Comp — With No Machine Learning Knowledge
 Learn how to leverage software developer tools to beat the best in a Natural Language Processing competition on Kaggle, without using any Machine Learning.
Learn how to leverage software developer tools to beat the best in a Natural Language Processing competition on Kaggle, without using any Machine Learning.
214. What Is Open AI Foundry and How Does It Change Generative AI?
 OpenAI Foundry may just be a rumor, but it took the tech news space by storm. Learn what we can expect, when, and who will benefit from Foundry first.
OpenAI Foundry may just be a rumor, but it took the tech news space by storm. Learn what we can expect, when, and who will benefit from Foundry first.
215. The Importance Of Collaboration Between Healthcare Providers And AI Developers
 Discover the significant impact of AI on healthcare. Partner with AI developers to overcome these obstacles and navigate real-world healthcare problems.
Discover the significant impact of AI on healthcare. Partner with AI developers to overcome these obstacles and navigate real-world healthcare problems.
216. AI Industries Converge: Llama 3 and Electric Atlas Have More In Common Than You Think
 Meta's Llama 3 language model and Boston Dynamics' electric Atlas robot represent breakthroughs in AI. Together, they could lead to more helpful AI.
Meta's Llama 3 language model and Boston Dynamics' electric Atlas robot represent breakthroughs in AI. Together, they could lead to more helpful AI.
217. How Effective Is GitHub Copilot?
 What do developers and studies say about GitHub Copilot? We break down research on code quality, productivity, and security in real-world use.
What do developers and studies say about GitHub Copilot? We break down research on code quality, productivity, and security in real-world use.
218. Augmented Analytics & Data Storytelling: Covid Ups FP&A Demand
 Businesses need agile tools to quickly identify and communicate actionable insights for more informed decision-making.
Businesses need agile tools to quickly identify and communicate actionable insights for more informed decision-making.
219. Affective computing
 Affective computing is the study and development of systems and devices that can recognize, interpret, process, and simulate human affects.
Affective computing is the study and development of systems and devices that can recognize, interpret, process, and simulate human affects.
220. The 16 Main Reasons Why GitHub Copilot Breaks
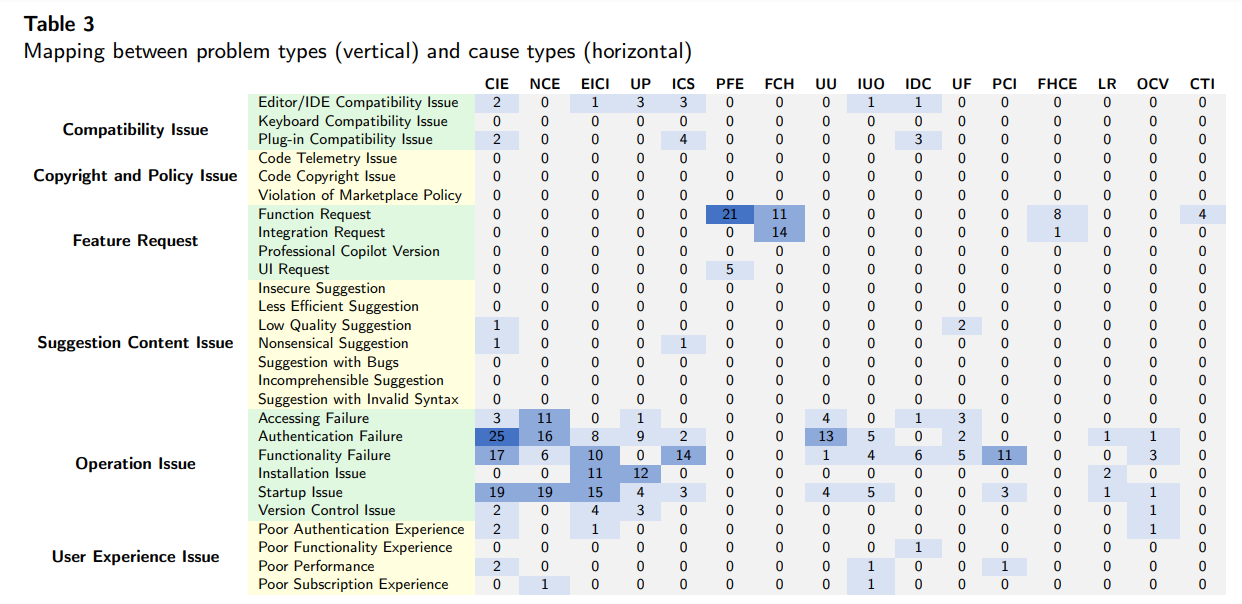 Explore 391 GitHub Copilot issues categorized into 16 root causes, from internal errors to IDE incompatibility and user misconfigurations.
Explore 391 GitHub Copilot issues categorized into 16 root causes, from internal errors to IDE incompatibility and user misconfigurations.
221. An Intro to Transfer Learning & Retraining
 In simple terms, transfer learning is a machine learning approach where a model that is already trained on a specific data set and developed for a specific task
In simple terms, transfer learning is a machine learning approach where a model that is already trained on a specific data set and developed for a specific task
222. Multilingual Isn’t Cross-Lingual: Inside My Benchmark of 11 LLMs on Mid- & Low-Resource Languages
 A data-driven look at why multilingual LLMs fail at true cross-lingual reasoning, and how culturally intact datasets and new metrics reveal the gap.
A data-driven look at why multilingual LLMs fail at true cross-lingual reasoning, and how culturally intact datasets and new metrics reveal the gap.
223. Startup Interview with Changsu Lee, Allganize's Founder and CEO
 This interview with Changsu Lee, founder and CEO of Allganize, Inc. goes into details the main reasons why he started his AI NLU company back in 2017.
This interview with Changsu Lee, founder and CEO of Allganize, Inc. goes into details the main reasons why he started his AI NLU company back in 2017.
224. New Open-Source Platform Is Letting AI Researchers Crack Tough Languages
 Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
225. How Machine Learning Helps Identify Lot Items in Tender Documents
 Learn how machine learning algorithms help extract lot references and item details from tender documents, improving accuracy and efficiency in data processing.
Learn how machine learning algorithms help extract lot references and item details from tender documents, improving accuracy and efficiency in data processing.
226. Creating a Systematic ESG Scoring System: Conclusion and Bibliography
 This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
227. How Natural Language Processing Companies Are Transforming SEO Strategies
 Have you searched something oddly specific when, like a psychic, Google guesses the query? It may seem like they can read minds, but they can't-- it's just NLP!
Have you searched something oddly specific when, like a psychic, Google guesses the query? It may seem like they can read minds, but they can't-- it's just NLP!
228. Creating a Systematic ESG Scoring System: Methods
 This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
229. Can AI Tell Jane Austen’s Writing Apart from a Fake?
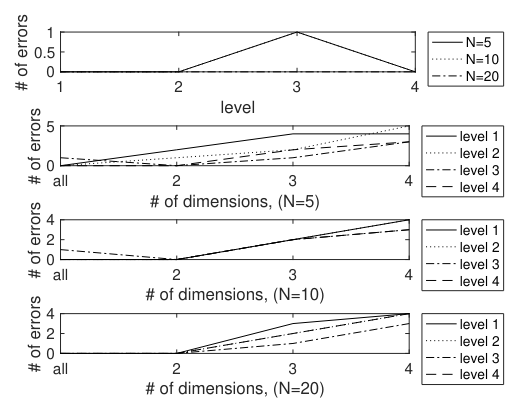 A stylometric analysis of Sanditon reveals subtle linguistic patterns distinguishing Jane Austen’s original writing from a later continuation by “Another Lady.”
A stylometric analysis of Sanditon reveals subtle linguistic patterns distinguishing Jane Austen’s original writing from a later continuation by “Another Lady.”
230. Overcoming Multilingual and Multi-Task Challenges in NLP
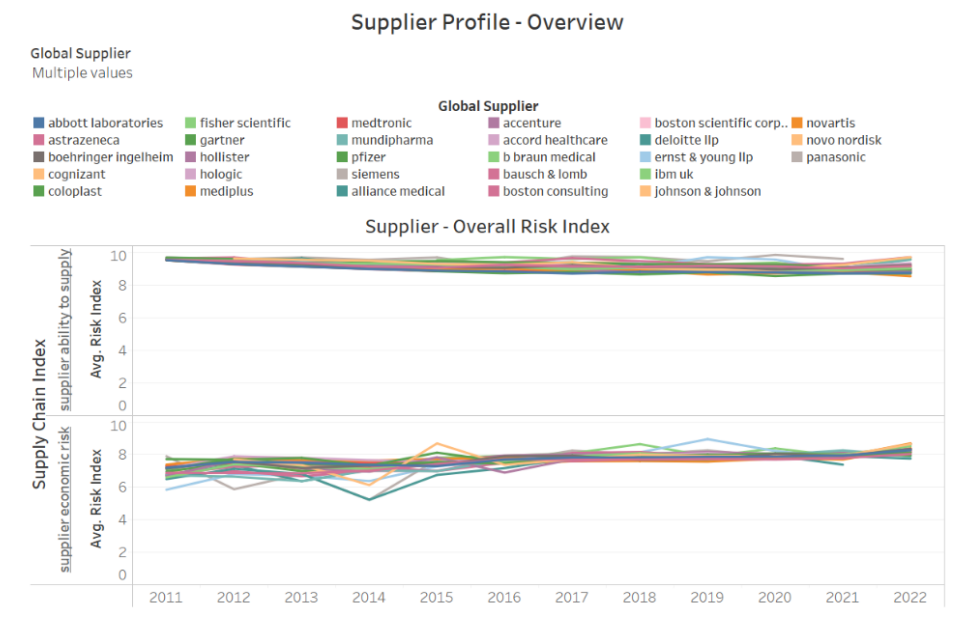 Explore how lightweight, generalized NLP methods and text classification with domain lexicons tackle multilingual, heterogeneous data in complex industry tasks.
Explore how lightweight, generalized NLP methods and text classification with domain lexicons tackle multilingual, heterogeneous data in complex industry tasks.
231. Finally, ELIZA: A Platform, Not a ChatBot!
 Discover ELIZA’s true role as a research platform for studying human-machine interaction, revealing its deeper purpose beyond being a simple chatbot.
Discover ELIZA’s true role as a research platform for studying human-machine interaction, revealing its deeper purpose beyond being a simple chatbot.
232. Why Classic Algorithms Still Matter in Modern Natural Language Processing
 Explore the challenges of choosing NLP methods for industry projects, balancing advanced models like BERT with simpler, more practical solutions.
Explore the challenges of choosing NLP methods for industry projects, balancing advanced models like BERT with simpler, more practical solutions.
233. Natural Language Processing with Python: A Detailed Overview
 A detailed overview of an AI subfield called Natural Language Processing or NLP and how to learn NLP.
A detailed overview of an AI subfield called Natural Language Processing or NLP and how to learn NLP.
234. FreeEval: The Ethical Concerns
 In this paper, we introduce FreeEval, a modular and extensible framework for trustworthy and efficient automatic evaluation of LLMs.
In this paper, we introduce FreeEval, a modular and extensible framework for trustworthy and efficient automatic evaluation of LLMs.
235. SLIP and Lisp: The Trailblazers of AI Programming and Symbolic Computation
 Explore the development of SLIP & Lisp and how these early AI programming languages shaped modern computing.
Explore the development of SLIP & Lisp and how these early AI programming languages shaped modern computing.
236. Demonstrating Supplier Risk Profiles with Real-World Data
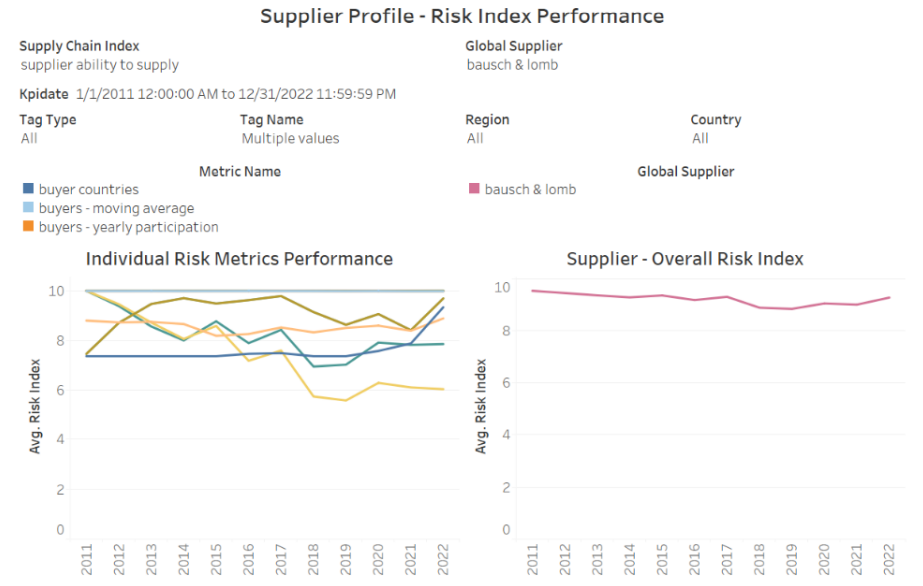 Explore how the supplier risk profiles system calculates metrics like ability to supply and economic risk using 3.3 million healthcare tender notices.
Explore how the supplier risk profiles system calculates metrics like ability to supply and economic risk using 3.3 million healthcare tender notices.
237. Understanding and Generating Dialogue between Characters in Stories: Limitations and References
 Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
238. I Gave 5 Frontier Models the Same Email Thread. Here's What They Missed.
 We fed the same 31-message email thread to GPT-5.4, Claude 4.6, Gemini 3, Grok 4.20, and Mistral Large 3. Every model failed on structural email problems that p
We fed the same 31-message email thread to GPT-5.4, Claude 4.6, Gemini 3, Grok 4.20, and Mistral Large 3. Every model failed on structural email problems that p
239. Who Made ELIZA Possible?
 This paper acknowledges the key contributors in the development of ELIZA, including the significant support from MIT Archivists and research team members.
This paper acknowledges the key contributors in the development of ELIZA, including the significant support from MIT Archivists and research team members.
240. Natural Language Processing Essentials: A Simple Introduction and Some Key Insights From a Dev
 Discover NLP essentials in a quick, simplified journey. From tech transition to AI insights, explore the world of Natural Language Processing.
Discover NLP essentials in a quick, simplified journey. From tech transition to AI insights, explore the world of Natural Language Processing.
241. How Text Mining Can Simplify the Complexities of Procurement Data
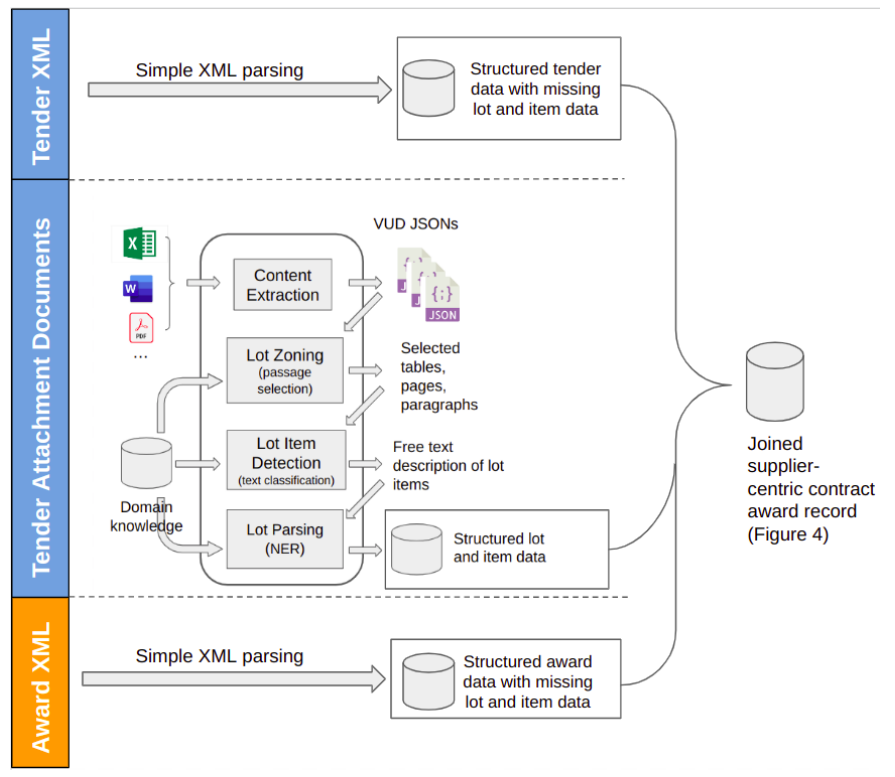 Discover key NLP and text mining methods for extracting and structuring procurement data, with insights into the unique challenges faced in this domain.
Discover key NLP and text mining methods for extracting and structuring procurement data, with insights into the unique challenges faced in this domain.
242. How to Build Supplier Risk Profiles
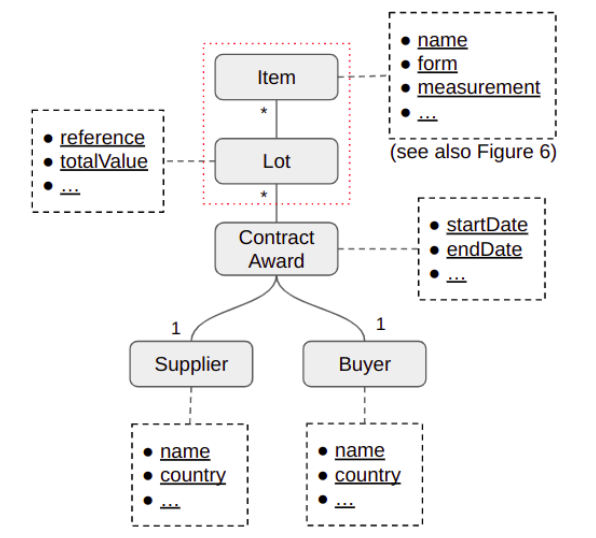 Learn how to extract and structure key supplier, contract, and lot data from XMLs to create dynamic risk profiles and supplier records.
Learn how to extract and structure key supplier, contract, and lot data from XMLs to create dynamic risk profiles and supplier records.
243. Interpretation is the Core of Intelligence
 Explore how interpretation, a key aspect of cognitive science, influences both human and AI understanding.
Explore how interpretation, a key aspect of cognitive science, influences both human and AI understanding.
244. How AI is Making it Easier to Spread Fake News
 Is Bitcoin the revolution against unequal economic systems, or a scam and money laundry mechanism? Will artificial intelligence (AI) improve and boost humankind, or terminate our species? These questions present incompatible scenarios, but you will find supporters for all of them. They cannot be all right, so who’s wrong then?
Is Bitcoin the revolution against unequal economic systems, or a scam and money laundry mechanism? Will artificial intelligence (AI) improve and boost humankind, or terminate our species? These questions present incompatible scenarios, but you will find supporters for all of them. They cannot be all right, so who’s wrong then?
245. The History of LLMs - Part 1: The Era of Mechanical Translation and How It Crashed
 A series about the history of large language models (LLMs). First episode: discover the birth of mechanical translation, one of the first areas of NLP.
A series about the history of large language models (LLMs). First episode: discover the birth of mechanical translation, one of the first areas of NLP.
246. When Words Won’t Talk, Sentence Structures Spill the Truth
 This study explores how statistical parsing of sentence structures enhances authorship attribution, revealing hidden stylistic differences in many cases.
This study explores how statistical parsing of sentence structures enhances authorship attribution, revealing hidden stylistic differences in many cases.
247. How ELIZA’s Success Revealed the Pitfalls of Machine Credibility
 ELIZA, designed to study human interaction with AI, instead became a symbol of AI misinterpretation, highlighting dangers of attributing machine intelligence.
ELIZA, designed to study human interaction with AI, instead became a symbol of AI misinterpretation, highlighting dangers of attributing machine intelligence.
248. How to Convert Different Data Formats into Universal JSON with VUD
 Vamstar converts various file formats like Word, Excel, and PDF into a structured, machine-readable JSON format called VUD, enabling easier data extraction.
Vamstar converts various file formats like Word, Excel, and PDF into a structured, machine-readable JSON format called VUD, enabling easier data extraction.
249. Neuro-Symbolic Reasoning Meets RL: EXPLORER Outperforms in Text-World Games
 EXPLORER combines neural exploration and symbolic reasoning to achieve better generalization, interpretability, and performance in text-based games.
EXPLORER combines neural exploration and symbolic reasoning to achieve better generalization, interpretability, and performance in text-based games.
250. The Evolution of Text-to-Code and Pseudocode Automation
 Explore the journey from user stories to automated pseudocode generation, highlighting key milestones in Agile development and deep learning innovations.
Explore the journey from user stories to automated pseudocode generation, highlighting key milestones in Agile development and deep learning innovations.
251. Creating a Systematic ESG Scoring System: Related Works
 This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
252. Understanding and Generating Dialogue between Characters in Stories: Experiments
 Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
253. Unleashing LLM Speed: Multi-Token Self-Speculative Decoding Redefines Inference
 Witness the power of multi-token prediction! Detailed charts and tables reveal significant relative speedups and impressive throughput gains as inference scales
Witness the power of multi-token prediction! Detailed charts and tables reveal significant relative speedups and impressive throughput gains as inference scales
254. Creating a Systematic ESG Scoring System: Purpose
 This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
255. Native Analytics On Elasticsearch With Knowi
 Table of Contents
Table of Contents
256. Rules, Exceptions, and Exploration: The Secret to EXPLORER’s Success
 EXPLORER outperforms baselines by combining neural exploration and symbolic reasoning, excelling in text-based games with unseen entities.
EXPLORER outperforms baselines by combining neural exploration and symbolic reasoning, excelling in text-based games with unseen entities.
257. Why NLP Projects in Business Aren’t the Same as Research
 Learn how NLP projects in business differ from research, focusing on practical solutions, real-world challenges, and the need for continuous model updates.
Learn how NLP projects in business differ from research, focusing on practical solutions, real-world challenges, and the need for continuous model updates.
258. Comparison of Machine Learning Methods: Conclusions and Future Work, and References
 This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
259. Creating a Systematic ESG Scoring System: Results
 This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
260. The BLEU Benchmark: Ensuring Quality in Automated Code and Pseudocode
 Evaluate the effectiveness of NLP-based code and pseudocode generation with BLEU scores, ensuring high-quality translations for Agile development.
Evaluate the effectiveness of NLP-based code and pseudocode generation with BLEU scores, ensuring high-quality translations for Agile development.
261. Understanding and Generating Dialogue between Characters in Stories: Future Work
 Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
262. What Developers Really Think About GitHub Copilot
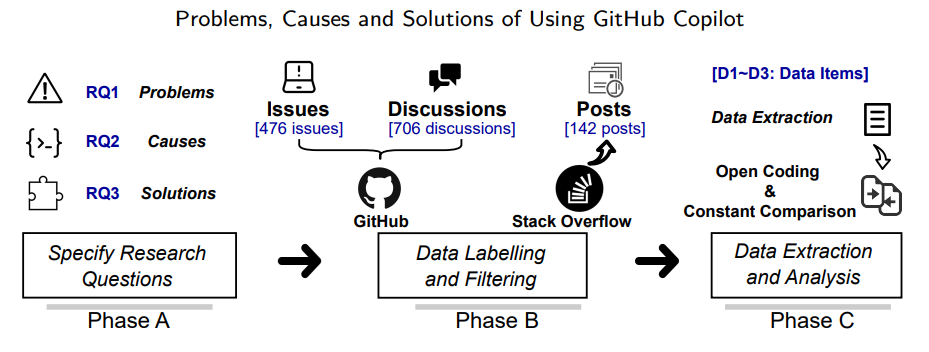 An empirical study of GitHub Copilot reveals common problems, their causes, and solutions—based on 1,300+ developer discussions and issues.
An empirical study of GitHub Copilot reveals common problems, their causes, and solutions—based on 1,300+ developer discussions and issues.
263. Comparison of Machine Learning Methods: Discussion and Qualitative Analysis
 This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
264. Exploring User Needs and Satisfaction with GitHub Copilot
 Research shows Copilot alters coding workflows, increasing code verification time and emphasizing the need for clear code explanations and flexible AI features.
Research shows Copilot alters coding workflows, increasing code verification time and emphasizing the need for clear code explanations and flexible AI features.
265. Efficient Lot Parsing with Vamstar’s Rule-Based System
 Vamstar uses a rule-based system to parse lot references and item information from tender sentences, extracting structured data like item names, forms, and more
Vamstar uses a rule-based system to parse lot references and item information from tender sentences, extracting structured data like item names, forms, and more
266. Transforming Text to Code: An Approach to Efficient Agile Development
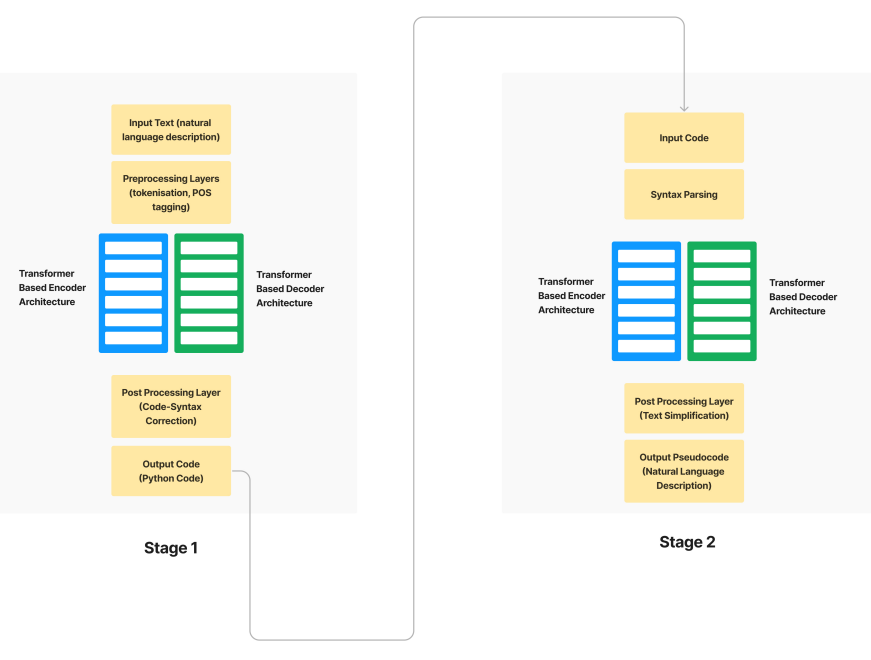 This methodology leverages NLP and transformers to convert English text into code and pseudocode, optimizing the Agile development process.
This methodology leverages NLP and transformers to convert English text into code and pseudocode, optimizing the Agile development process.
267. Understanding and Generating Dialogue between Characters in Stories: Conclusion
 Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
268. Evaluating Sentiment Analysis Performance: LLMs vs Classical ML
 This story compares sentiment analysis performance of large language models (LLMs) to classical ML methods like SVM and decision trees
This story compares sentiment analysis performance of large language models (LLMs) to classical ML methods like SVM and decision trees
269. Transductive Learning for Textual Few-Shot: Limitations, Acknowledgements, & References
 Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
270. Creating a Systematic ESG Scoring System: Discussion
 This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
This project aims to create a data-driven ESG evaluation system that can provide better guidance and more systemized scores by incorporating social sentiment.
271. How Developers Stay in Control While Using Copilot
 Learn how to use GitHub Copilot effectively—maintain control, improve code quality, and avoid platform issues with these research-backed insights.
Learn how to use GitHub Copilot effectively—maintain control, improve code quality, and avoid platform issues with these research-backed insights.
272. Workflow for Extracting Structured Data from Tender Documents to Build Supplier Risk Profiles
 A multi-step methodology extracts structured lot and item data from tender documents, helping build supplier risk profiles using text processing and XML parsing
A multi-step methodology extracts structured lot and item data from tender documents, helping build supplier risk profiles using text processing and XML parsing
273. Building Chatbots from Scratch: Understanding and Harnessing Large Language Models (LLMs)
 Imagine having a super smart friend who has read every book, article, and blog post on the internet.
Imagine having a super smart friend who has read every book, article, and blog post on the internet.
274. Semantic Keywords: What Are They and Why Are They So Useful?
 Semantic keyword considerations are crucial to providing quality search experiences, but wait, there’s more. They’re needed for Google search success.
Semantic keyword considerations are crucial to providing quality search experiences, but wait, there’s more. They’re needed for Google search success.
275. How GitHub and Stack Overflow Data Were Verified for Research Accuracy
 We address threats to construct, external validity, and reliability in our Copilot study using multiple data sources and consensus-based data labeling.
We address threats to construct, external validity, and reliability in our Copilot study using multiple data sources and consensus-based data labeling.
⚡ TLDR
276. Comparison of Machine Learning Methods: Background
 This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
277. The Era of Contextual RAG Is Here to Stay?
 RAG addresses some of the key problems with LLMs. But contextual retrieval goes one step further to improve any RAG pipeline
RAG addresses some of the key problems with LLMs. But contextual retrieval goes one step further to improve any RAG pipeline
278. Teaching AI to Say "I Don't Know": A Four-Step Guide to Contextual Data Imputation
 CLAIM converts tabular data to natural language, then uses an LLM to generate contextual text descriptors for missing values to improve downstream tasks.
CLAIM converts tabular data to natural language, then uses an LLM to generate contextual text descriptors for missing values to improve downstream tasks.
279. Comparison of Machine Learning Methods: Abstract and Introduction
 This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
280. Rural Banking stack-3 Or The Magic of Conversations
 Conversations will replace apps in the next step of developing lending tech. This is my view as we work towards a better lending stack.
Conversations will replace apps in the next step of developing lending tech. This is my view as we work towards a better lending stack.
281. Sequence Labeling for Automated Feedback in Tutor Training
 Explore how sequence labeling, a key NLP technique, is applied to identify praise components in tutor responses, enabling automated
Explore how sequence labeling, a key NLP technique, is applied to identify praise components in tutor responses, enabling automated
282. GPT-3 Trips Over Polish Grammar While Classic Tools Hold Their Ground in AI Comparison
 Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
283. CulturaX: A High-Quality, Multilingual Dataset for LLMs - Abstract and Introduction
 Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
284. AI Business: Enterprise Models for LLMs Profitability
 What can LLMs do for prompt and quality sleep, writing with the non-dominant hand, retention when learning a new language and for new marketplaces for commerce?
What can LLMs do for prompt and quality sleep, writing with the non-dominant hand, retention when learning a new language and for new marketplaces for commerce?
285. Understanding and Generating Dialogue between Characters in Stories: DIALSTORY Dataset
 Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
286. Using AI to Analyze Healthcare Procurement Documents and Assess Supplier Risks
 Explore a real-world text mining project that tackles heterogeneous, multilingual healthcare procurement documents to build a structured supplier risk database.
Explore a real-world text mining project that tackles heterogeneous, multilingual healthcare procurement documents to build a structured supplier risk database.
287. Understanding and Generating Dialogue between Characters in Stories: Discussion
 Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
288. "AI Can’t 'Think” Like Us Independently," - says Machine Learning Engineer Mani Sarkar
 In our new blog series, we’re interviewing data scientists and machine learning engineers about their career paths, areas of interest and thoughts on the future of AI. We kick off this week with a 20-year veteran and jack-of-all-trades when it comes to machine learning and data science: Mani Sarkar. Mani is a strategic machine learning engineer based in London, UK, who believes in getting beyond the theoretical and applying AI to real-world problems.
In our new blog series, we’re interviewing data scientists and machine learning engineers about their career paths, areas of interest and thoughts on the future of AI. We kick off this week with a 20-year veteran and jack-of-all-trades when it comes to machine learning and data science: Mani Sarkar. Mani is a strategic machine learning engineer based in London, UK, who believes in getting beyond the theoretical and applying AI to real-world problems.
289. Weizenbaum’s Gomoku and the Art of Creating an Illusion of Intelligence
 Explore Weizenbaum's 1962 paper on gomoku and how it critiques AI's potential to create an illusion of intelligence.
Explore Weizenbaum's 1962 paper on gomoku and how it critiques AI's potential to create an illusion of intelligence.
290. Naive Sentiment Analysis Using R
 Cleuton Sampaio, October 2019
Cleuton Sampaio, October 2019
291. Comparison of Machine Learning Methods: Approach
 This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
292. What Works (and Doesn’t) When Coding with ChatGPT
 Pair programming with ChatGPT shows both promise and pitfalls—from quick solutions to occasional errors and reasoning flaws. Here's what we learned.
Pair programming with ChatGPT shows both promise and pitfalls—from quick solutions to occasional errors and reasoning flaws. Here's what we learned.
293. Decoding the Magic: How Machines Master Human Language
 LLMs in an easy way explanation, InstructGPT explanation, ML for non professionals, how machine learning models trained
LLMs in an easy way explanation, InstructGPT explanation, ML for non professionals, how machine learning models trained
294. How ChatGPT Helped Code a Copula Model Without Human Input
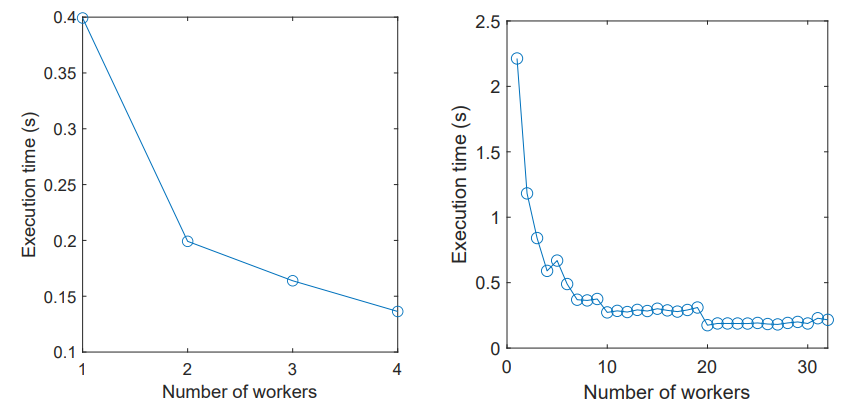 ChatGPT wrote and optimized copula model code, showing how prompt tweaks impact success—with no human code written.
ChatGPT wrote and optimized copula model code, showing how prompt tweaks impact success—with no human code written.
295. Debugging Copulas and Speeding Up Simulations with AI
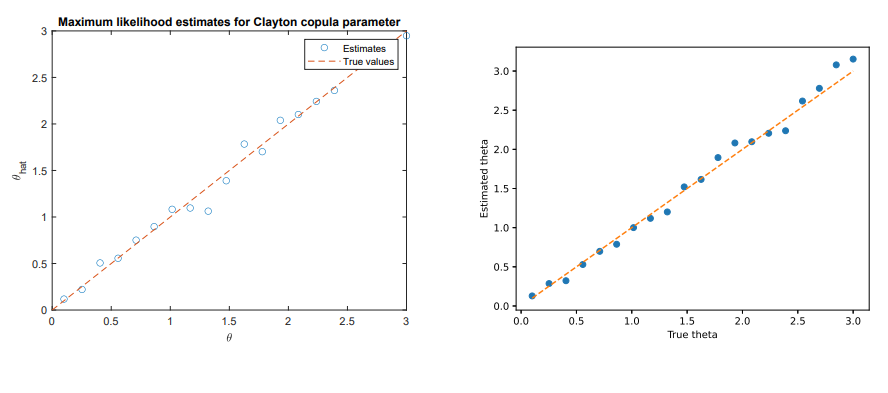 ChatGPT helps debug, optimize, and parallelize statistical code across languages like R, Python, and MATLAB—with insights into prompt engineering.
ChatGPT helps debug, optimize, and parallelize statistical code across languages like R, Python, and MATLAB—with insights into prompt engineering.
296. About Cisco, Alascom and Fanuc's Progress on Building Collaborative Cobots
 By harnessing Natural language to allow for more seamlessly collaborative Robotics projects, Cisco, Alascom and Fanuc are drawing a roadmap for the future.
By harnessing Natural language to allow for more seamlessly collaborative Robotics projects, Cisco, Alascom and Fanuc are drawing a roadmap for the future.
297. No. You Still Cannot Have A Real Conversation With a Chatbot.
 Chatbots do not really understand what you are saying and you cannot have a real conversation with a personal assistant like you can with another person.
Chatbots do not really understand what you are saying and you cannot have a real conversation with a personal assistant like you can with another person.
298. How a Herd of Models Challenges ChatGPT's Dominance: Conclusion, Discussion, and References
 How an intelligent router and a herd of open-source models challenge ChatGPT's dominance in language understanding.
How an intelligent router and a herd of open-source models challenge ChatGPT's dominance in language understanding.
299. Understanding and Generating Dialogue between Characters in Stories: Proposed Tasks
 Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
300. The AI Building Block You’ve Never Heard Of (But Use Every Day)
 Some models that are efficient in learning sentence representations include BERT, specifically Sentence BERT.
Some models that are efficient in learning sentence representations include BERT, specifically Sentence BERT.
301. Researchers Learn to Measure AI’s Language Skills
 Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
302. CulturaX: A High-Quality, Multilingual Dataset for LLMs - Multilingual Dataset Creation
 Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
303. The Prompt Patterns That Decide If an AI Is “Correct” or “Wrong”
 Benchmarking AI isn’t guesswork—CRITICBENCH uses few-shot chain-of-thought prompts to reveal how accurate LLMs really are.
Benchmarking AI isn’t guesswork—CRITICBENCH uses few-shot chain-of-thought prompts to reveal how accurate LLMs really are.
304. Future of Programming: Enhancing Agile Development with Automated Pseudocode
 Explore a two-stage methodology using NLP to convert user stories into pseudocode, optimizing the Agile development process with promising BLEU scores.
Explore a two-stage methodology using NLP to convert user stories into pseudocode, optimizing the Agile development process with promising BLEU scores.
305. How Researchers Used Grounded Theory to Decode Copilot Issues
 A qualitative study of GitHub Copilot issues using data extraction and open coding to reveal root causes, real solutions, and recurring developer problems.
A qualitative study of GitHub Copilot issues using data extraction and open coding to reveal root causes, real solutions, and recurring developer problems.
306. A Mathematical Overview of Dimension Reduction in Text Classification
 Learn how dimension reduction improves text classification by optimizing feature clustering using scatter matrices.
Learn how dimension reduction improves text classification by optimizing feature clustering using scatter matrices.
307. How Healthcare Procurement Data is Being Used to Evaluate Supplier Reliability
 Explore the challenges in healthcare procurement data mining and how NLP and text mining are used to create dynamic supplier risk profiles from complex datasets
Explore the challenges in healthcare procurement data mining and how NLP and text mining are used to create dynamic supplier risk profiles from complex datasets
308. CulturaX: A High-Quality, Multilingual Dataset for LLMs - Conclusion and References
 Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
309. Limited Gains: Multi-Token Training on Natural Language Choice Tasks
 This figure indicates that multi-token prediction with 7B models yields limited or no improvement in accuracy on standard NLP benchmarks
This figure indicates that multi-token prediction with 7B models yields limited or no improvement in accuracy on standard NLP benchmarks
310. How Constant Feedback and Pair Work Forged a Successful Online Classroom
 Relentless feedback led to high student retention, with participants praising the interactive pair work, humor, and instructor support in the TDM course.
Relentless feedback led to high student retention, with participants praising the interactive pair work, humor, and instructor support in the TDM course.
[311. Improving Text Embeddings with
Large Language Models: Training](https://hackernoon.com/improving-text-embeddings-with-large-language-models-training)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
312. Researchers Pit GPT-3.5 Against Classic Language Tools in Polish Text Analysis
 Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
313. We Released Modern Google-level Speech-to-Text Models
 Our models are on par with premium Google models and also really simple to use.
Our models are on par with premium Google models and also really simple to use.
314. Transductive Learning for Textual Few-Shot Classification: Related Work
 Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
315. Unlocking Textual Data: A Beginner's Journey Through Python, NLTK, and spaCy
 This 3-session TDM course for non-coders uses Python, NLTK, and spaCy to teach tokenization, visualization, and NER with real-world examples.
This 3-session TDM course for non-coders uses Python, NLTK, and spaCy to teach tokenization, visualization, and NER with real-world examples.
316. The End of the Guessing Game? Why Describing Data Beats Estimating It
 CLAIM surpasses statistical and ML methods by using LLMs for contextual imputation, though future work must address scalability and domain specificity.
CLAIM surpasses statistical and ML methods by using LLMs for contextual imputation, though future work must address scalability and domain specificity.
317. FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
 FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies
FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies
318. Using Machine Learning for Lot and Item Identification in Tenders
 Vamstar uses machine learning to identify lot references and items in tender documents, classifying sentences and tables for lot item detection.
Vamstar uses machine learning to identify lot references and items in tender documents, classifying sentences and tables for lot item detection.
319. Understanding and Generating Dialogue between Characters in Stories: Related Works
 Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
320. 6 Chatbot Mistakes that Scare Your Customers Away
 Six unforgivable mistakes that scare off your customers and prospects? The Smart Tribune team answers you.
Six unforgivable mistakes that scare off your customers and prospects? The Smart Tribune team answers you.
321. What Developers Wish GitHub Copilot Did Better
 A large-scale study uncovers key problems developers face using GitHub Copilot, along with their causes and potential solutions.
A large-scale study uncovers key problems developers face using GitHub Copilot, along with their causes and potential solutions.
322. A Meta-Evaluation of LLMs
 Meta-evaluation refers to the process of evaluating the fairness, reliability, and validity of evaluation protocols themselves.
Meta-evaluation refers to the process of evaluating the fairness, reliability, and validity of evaluation protocols themselves.
323. ChatGPT, Symbolic Math, and the Struggle for Accuracy
 We test ChatGPT’s ability to code the Clayton copula density and perform ML estimation. Results vary—great at general tasks, weak at symbolic math reasoning.
We test ChatGPT’s ability to code the Clayton copula density and perform ML estimation. Results vary—great at general tasks, weak at symbolic math reasoning.
324. New Study Shows How Text Mining and NLP Transform Legal, E-commerce, and Construction Industries
 New study explores the impact of text mining and NLP in legal, e-commerce, and construction, revealing key industry applications and challenges.
New study explores the impact of text mining and NLP in legal, e-commerce, and construction, revealing key industry applications and challenges.
[325. Improving Text Embeddings with
Large Language Models: Conclusion and References](https://hackernoon.com/improving-text-embeddings-with-large-language-models-conclusion-and-references)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
326. New Framework Promises to Train AI to Better Understand Hard-to-Grasp Languages Like Polish
 Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
[327. Improving Text Embeddings with
Large Language Models: Abstract and Introduction](https://hackernoon.com/improving-text-embeddings-with-large-language-models-abstract-and-introduction)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
328. CLAIM: A Contextual Language Model for Accurate Imputation of Missing Tabular Data
 CLAIM uses LLMs to fill missing tabular data with contextual text, outperforming traditional methods and improving downstream task accuracy.
CLAIM uses LLMs to fill missing tabular data with contextual text, outperforming traditional methods and improving downstream task accuracy.
329. Experiments
 Pruned early-bird subnetworks in Transformers reduce memory by up to 49% and maintain performance, validating a faster training strategy across ViT, and GPT-2.
Pruned early-bird subnetworks in Transformers reduce memory by up to 49% and maintain performance, validating a faster training strategy across ViT, and GPT-2.
330. The HackerNoon Newsletter: GPS Is Broken, And Its Holding Tech Back (12/30/2024)
 12/30/2024: Top 5 stories on the HackerNoon homepage!
12/30/2024: Top 5 stories on the HackerNoon homepage!
331. How a Herd of Models Challenges ChatGPT's Dominance: Abstract and Introduction
 How an intelligent router and a herd of open-source models challenge ChatGPT's dominance in language understanding.
How an intelligent router and a herd of open-source models challenge ChatGPT's dominance in language understanding.
332. FreeEval: Efficient Inference Backends
 FreeEval’s high-performance inference backends are designed to efficiently handle the computational demands of large-scale LLM evaluations.
FreeEval’s high-performance inference backends are designed to efficiently handle the computational demands of large-scale LLM evaluations.
333. Understanding and Generating Dialogue between Characters in Stories: Methodology
 Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
Exploring machine understanding of story dialogue via new tasks and dataset, improving coherence and speaker recognition in storytelling AI.
334. How We Found Early-Bird Subnetworks in Transformers Without Retraining Everything
 We identify early-bird subnetworks in Transformers using masked distance pruning, optimizing training for ViTs and LMs like GPT-2 and RoBERTa.
We identify early-bird subnetworks in Transformers using masked distance pruning, optimizing training for ViTs and LMs like GPT-2 and RoBERTa.
335. Code Book for Annotation of Diverse Cross-Document Coreference: Conclusion and Future Work
 This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations.
336. A Case Study of Two TDM Pilots Using Virtual Programming Environments and Gamification
 Two online pilots of a TDM course used pair programming and relentless feedback. The second improved it with pre-recorded lectures and digital badges.
Two online pilots of a TDM course used pair programming and relentless feedback. The second improved it with pre-recorded lectures and digital badges.
337. Researchers Build Public Leaderboard for Language Processing Tools
 Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
338. Why We Should Thank Karen Spärck Jones for Search Engines
 Search engines exist today because of the pioneering work of Yorkshire-born computer scientist Karen Spärck Jones.
Search engines exist today because of the pioneering work of Yorkshire-born computer scientist Karen Spärck Jones.
339. How Vamstar Identifies Relevant Content for Lots in Tender Documents
 Vamstar uses machine learning to filter relevant pages and tables from tender documents, identifying lot references and items for further processing.. TLDR:
Vamstar uses machine learning to filter relevant pages and tables from tender documents, identifying lot references and items for further processing.. TLDR:
340. What Is KBQA and What Are Its Benchmarks?
 The KBQA task aims to make large knowledge bases accessible by natural language.
The KBQA task aims to make large knowledge bases accessible by natural language.
341. Porting a Cross-Disciplinary Text Mining Course Online Using Innovative Engagement Techniques
 An online TDM course for humanities students succeeded via pair programming and relentless feedback, building community and bridging skill gaps.
An online TDM course for humanities students succeeded via pair programming and relentless feedback, building community and bridging skill gaps.
342. Report Shows How NLP Helps Extract Value from Procurement Contracts
 Explore how text mining and NLP help analyze procurement documents, from sustainability trends to risk and contract analysis, in simple terms.
Explore how text mining and NLP help analyze procurement documents, from sustainability trends to risk and contract analysis, in simple terms.
[343. Improving Text Embeddings with
Large Language Models: Prompts for Synthetic Data Generation](https://hackernoon.com/improving-text-embeddings-with-large-language-models-prompts-for-synthetic-data-generation)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
344. My Journey Into Predicting States Using Emoji Observations With Viterbi Algorithm
 See the implementation of the Viterbi algorithm in Python
See the implementation of the Viterbi algorithm in Python
345. A Novel Method for Analysing Racial Bias: Collection of Person Level References: Method
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
346. Transductive Learning for Textual Few-Shot Classification: Abstract & Intro
 Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
[347. Improving Text Embeddings with
Large Language Models: Statistics of the Synthetic Data](https://hackernoon.com/improving-text-embeddings-with-large-language-models-statistics-of-the-synthetic-data)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
348. How Copilot Can Better Serve Developers
 Users want more Copilot customization, better code quality, simpler setup, broader IDE support, and attention to IP and privacy concerns.
Users want more Copilot customization, better code quality, simpler setup, broader IDE support, and attention to IP and privacy concerns.
349. Qualitative Emergence: The Paradox of Statistical AI in Language Comprehension - What to Know
 Explore how AI language models create coherent content through statistical processes, contrasting AI's approach with human cognition and examining its potential
Explore how AI language models create coherent content through statistical processes, contrasting AI's approach with human cognition and examining its potential
350. We Learned, They Learned: The Unwritten Rules of a Successful Online Classroom
 Teaching online is hard and technology fails, but pair programming and relentless feedback can build a rewarding community, proving virtual learning's value.
Teaching online is hard and technology fails, but pair programming and relentless feedback can build a rewarding community, proving virtual learning's value.
351. Learning Logic in Games: How EXPLORER Combines NLP and RL for
 EXPLORER combines neural exploration and symbolic reasoning using Answer Set Programming to enhance decision-making and generalization in text-based games.
EXPLORER combines neural exploration and symbolic reasoning using Answer Set Programming to enhance decision-making and generalization in text-based games.
352. Why Supervised Methods in NLP Struggle in Real-World Applications
 Despite progress, text mining and NLP research struggles in practical applications, especially in healthcare. Our work addresses critical gaps in the field.
Despite progress, text mining and NLP research struggles in practical applications, especially in healthcare. Our work addresses critical gaps in the field.
[353. Improving Text Embeddings with
Large Language Models: Instructions for Training and Evaluation](https://hackernoon.com/improving-text-embeddings-with-large-language-models-instructions-for-training-and-evaluation)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
354. The Noonification: A Synthetic Biography for a Geek (7/8/2024)
 7/8/2024: Top 5 stories on the HackerNoon homepage!
7/8/2024: Top 5 stories on the HackerNoon homepage!
355. Transductive Learning for Textual Few-Shot Classification: API-based Few-shot Learning
 Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
356. Background and Automatic Evaluation Methods for LLMs
 In this section, we provide an overview of the current landscape of LLM evaluation methods and the challenges posed by data contamination
In this section, we provide an overview of the current landscape of LLM evaluation methods and the challenges posed by data contamination
357. Creating Supplier-Centric Contract Records with XML Parsing and Data Joining
 Vamstar integrates XML parsing, tender data, and award information to create supplier-centric contract records
Vamstar integrates XML parsing, tender data, and award information to create supplier-centric contract records
358. Exploring AI Memory, Limitations, and Workarounds in Practice
 Simulating a real-world workflow, we test how ChatGPT solves technical tasks step-by-step without expert programming knowledge.
Simulating a real-world workflow, we test how ChatGPT solves technical tasks step-by-step without expert programming knowledge.
359. Chinese Biomedical Text Mining Challenges: Information Extraction Tasks Overview
 An overview of Information Extraction tasks in Chinese biomedical text mining challenges (2017-2023), covering NER and entity normalization
An overview of Information Extraction tasks in Chinese biomedical text mining challenges (2017-2023), covering NER and entity normalization
[360. Improving Text Embeddings with
Large Language Models: Multilingual Retrieval](https://hackernoon.com/improving-text-embeddings-with-large-language-models-multilingual-retrieval)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
361. New Web App Lets Researchers Test and Rank Language AI Tools in Real Time
 Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
362. How Vamstar Makes Sense of Complex Tender Data
 Vamstar develops methods to extract domain knowledge from TED tender XMLs, building multilingual lexicons and classifiers for analysis.
Vamstar develops methods to extract domain knowledge from TED tender XMLs, building multilingual lexicons and classifiers for analysis.
[363. Improving Text Embeddings with
Large Language Models: Is Contrastive Pre-training Necessary?](https://hackernoon.com/improving-text-embeddings-with-large-language-models-is-contrastive-pre-training-necessary)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
364. CulturaX: A High-Quality, Multilingual Dataset for LLMs - Data Analysis and Experiments
 Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
365. Why “Almost Right” Answers Are the Hardest Test for AI
 Discover how CRITICBENCH tests AI by sampling “convincing wrong answers” to reveal subtle flaws in model reasoning and accuracy.
Discover how CRITICBENCH tests AI by sampling “convincing wrong answers” to reveal subtle flaws in model reasoning and accuracy.
366. CulturaX: A High-Quality, Multilingual Dataset for LLMs - Related Work
 Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
367. CHIP, CCIR, CSMI, CCL, DCIC: Further Chinese Biomedical Text Mining Challenge
 Explore additional Chinese community challenges in biomedical text mining beyond CCKS, including tasks from CHIP, CCIR, CSMI, CCL, and DCIC.
Explore additional Chinese community challenges in biomedical text mining beyond CCKS, including tasks from CHIP, CCIR, CSMI, CCL, and DCIC.
368. Transductive Learning for Textual Few-Shot Classification: Experiments
 Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
369. FreeEval Architecture Overview and Extensible Modular Design
 FreeEval’s architecture features a modular design that could be separated into Evaluation Methods, Meta-Evaluation, and LLM Inference Backends.
FreeEval’s architecture features a modular design that could be separated into Evaluation Methods, Meta-Evaluation, and LLM Inference Backends.
370. The Design and Implementation of FreeEval
 In this section, we present the design and implementation of FreeEval, we discuss the framework’s architecture and its key components
In this section, we present the design and implementation of FreeEval, we discuss the framework’s architecture and its key components
371. Researchers Create Plug-and-Play System to Test Language AI Across the Globe
 Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
[372. Improving Text Embeddings with
Large Language Models: Test Set Contamination Analysis](https://hackernoon.com/improving-text-embeddings-with-large-language-models-test-set-contamination-analysis)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
373. How FreeEval Incorporates A Range of Metaevaluation Modules
 FreeEval prioritizes trustworthiness and fairness in evaluations by incorporating a range of metaevaluation modules that validates the evaluation results
FreeEval prioritizes trustworthiness and fairness in evaluations by incorporating a range of metaevaluation modules that validates the evaluation results
374. Transductive Learning for Textual Few-Shot Classification: Additional Experimental Results
 Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
375. Balancing Privacy and Personalization With ML-Powered Advertising Solutions
 Contextual advertising is on the rise, offering a more effective and less costly solution for personalization. Learn more about how ML can drive it further.
Contextual advertising is on the rise, offering a more effective and less costly solution for personalization. Learn more about how ML can drive it further.
376. AI That Learns and Unlearns: The Exceptionally Smart EXPLORER
 EXPLORER uses Inductive Logic Programming and exception learning to iteratively refine symbolic policies for better adaptability in text-based games.
EXPLORER uses Inductive Logic Programming and exception learning to iteratively refine symbolic policies for better adaptability in text-based games.
377. A Novel Method for Analysing Racial Bias: Collection of Person Level References: Related Works
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
378. My Experiments With AI Poetry And Some Random Thoughts

[379. Improving Text Embeddings with
Large Language Models: Implementation Details](https://hackernoon.com/improving-text-embeddings-with-large-language-models-implementation-details)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
[380. Improving Text Embeddings with
Large Language Models: Analysis of Training Hyperparameters](https://hackernoon.com/improving-text-embeddings-with-large-language-models-analysis-of-training-hyperparameters)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
381. A Novel Method for Analysing Racial Bias: Ethics Statement and References
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
[382. Improving Text Embeddings with
Large Language Models: Main Results](https://hackernoon.com/improving-text-embeddings-with-large-language-models-main-results)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
383. The Threads Come Together: Interpretation, Language, Lists, Graphs, and Recursion
 Explore how recursion, lists, and graph theory relate to interpretation in AI.
Explore how recursion, lists, and graph theory relate to interpretation in AI.
384. Transductive Learning for Textual Few-Shot Classification: An Enhanced Experimental Setting
 Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
385. Transductive Learning for Textual Few-Shot Classification: Proof of Proposition
 Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
386. Testing ChatGPT as a Pair Programming Partner
 We test ChatGPT as a pair programming partner, evaluating its code accuracy, response consistency, and understanding of complex statistical models.
We test ChatGPT as a pair programming partner, evaluating its code accuracy, response consistency, and understanding of complex statistical models.
387. A Novel Method for Analysing Racial Bias: Collection of Person Level References: Conclusion
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
388. A Novel Method for Analysing Racial Bias: Collection of Person Level References: Abstract and Intro
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
389. Why CriticBench Refuses GPT & LLaMA for Data Generation
 Inside CriticBench: How Google’s PaLM-2 models generate benchmark data for GSM8K, HumanEval, and TruthfulQA with open, transparent methods.
Inside CriticBench: How Google’s PaLM-2 models generate benchmark data for GSM8K, HumanEval, and TruthfulQA with open, transparent methods.
[390. Improving Text Embeddings with
Large Language Models: Synthetic Data Generation](https://hackernoon.com/improving-text-embeddings-with-large-language-models-synthetic-data-generation)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
391. Comparison of Machine Learning Methods: Experiments and Results
 This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
392. Multi-Token Prediction for Abstractive Text Summarization: ROUGE Metrics
 Discover how multi-token prediction significantly improves ROUGE-N and ROUGE-L scores for 7B parameter LLMs on various abstractive text summarization benchmarks
Discover how multi-token prediction significantly improves ROUGE-N and ROUGE-L scores for 7B parameter LLMs on various abstractive text summarization benchmarks
393. Researchers Challenge AI to Tackle the Toughest Parts of Language Processing
 Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
Researchers in Poland have developed an open-source tool that improves the evaluation and comparison of AI used in natural language preprocessing.
394. A Novel Method for Analysing Racial Bias: Collection of Person Level References: Limitations
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
395. It's Not Just What's Missing, It's How You Say It: CLAIM's Winning Formula
 Experiments show CLAIM outperforms baselines like k-NN and MICE across all missingness patterns, with context-specific descriptors proving most effective.
Experiments show CLAIM outperforms baselines like k-NN and MICE across all missingness patterns, with context-specific descriptors proving most effective.
396. Transformer Training Optimization via Early-Bird Ticket Analysis
 Investigating early-bird tickets in Transformers to reduce training costs while maintaining performance in vision and language models.
Investigating early-bird tickets in Transformers to reduce training costs while maintaining performance in vision and language models.
397. A Novel Method for Analysing Racial Bias: Collection of Person Level References: Data
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
398. When AI Gets It Wrong—and Then Gets It Right
 ChatGPT stumbles on copula sampling but learns to correct errors, showing potential in coding and understanding complex statistical concepts.
ChatGPT stumbles on copula sampling but learns to correct errors, showing potential in coding and understanding complex statistical concepts.
399. A Novel Method for Analysing Racial Bias: Appendix: Correlation Over Time
 In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
In this study, researchers propose a novel method to analyze representations of African Americans and White Americans in books between 1850 to 2000.
400. NLP and CRF Models for Mining Traditional Chinese Medicine
 AI and NLP reveal key terms and relationships in ancient TCM texts, paving the way for knowledge graphs and new insights into medical traditions.
AI and NLP reveal key terms and relationships in ancient TCM texts, paving the way for knowledge graphs and new insights into medical traditions.
401. Transductive Learning for Textual Few-Shot Classification: Conclusions
 Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
Few-shot classification involves training a model to perform a new classification task with a handful of labeled data.
402. Comparison of Machine Learning Methods: Related Work
 This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
This study proposes a set of carefully curated linguistic features for shallow machine learning methods and compares their performance with deep language models
[403. Improving Text Embeddings with
Large Language Models: Model Fine-tuning and Evaluation](https://hackernoon.com/improving-text-embeddings-with-large-language-models-model-fine-tuning-and-evaluation)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
404. Letting AI Do the Reading: Discovering Hidden Gems in Ancient TCM Books
 AI deciphers ancient TCM texts, extracting key entities and relationships to build knowledge graphs and spark new medical discoveries.
AI deciphers ancient TCM texts, extracting key entities and relationships to build knowledge graphs and spark new medical discoveries.
405. Beyond Seen Worlds: EXPLORER’s Journey into Generalized Reasoning
 EXPLORER dynamically generalizes symbolic rules using WordNet hypernyms to improve performance on unseen entities in text-based games.
EXPLORER dynamically generalizes symbolic rules using WordNet hypernyms to improve performance on unseen entities in text-based games.
406. What Patients Are Asking Our COVID-19 Virtual Assistant
 According to a recent Pew Research Center poll, in just one week (March 16–24), the number of Americans who view the coronavirus as a major threat to public health spiked by nearly 20%, from 47% to 66% — a figure that is growing exponentially.
According to a recent Pew Research Center poll, in just one week (March 16–24), the number of Americans who view the coronavirus as a major threat to public health spiked by nearly 20%, from 47% to 66% — a figure that is growing exponentially.
407. Fueling Next-Gen LLMs: Data-Driven Hyperparameter Setups Revealed
 This section unveils the data-driven hyperparameter configurations essential for training powerful LLMs, covering specific setups for model scaling, byte-level
This section unveils the data-driven hyperparameter configurations essential for training powerful LLMs, covering specific setups for model scaling, byte-level
408. Chinese Biomedical Text Mining Challenges: A 2017-2023 Overview
 Explore the landscape of Chinese biomedical text mining community challenges from 2017 to 2023, including CCKS, CHIP, and other key conferences and tasks.
Explore the landscape of Chinese biomedical text mining community challenges from 2017 to 2023, including CCKS, CHIP, and other key conferences and tasks.
409. Constructing CRITICBENCH: Scalable, Generalizable, and High-Quality LLM Evaluation
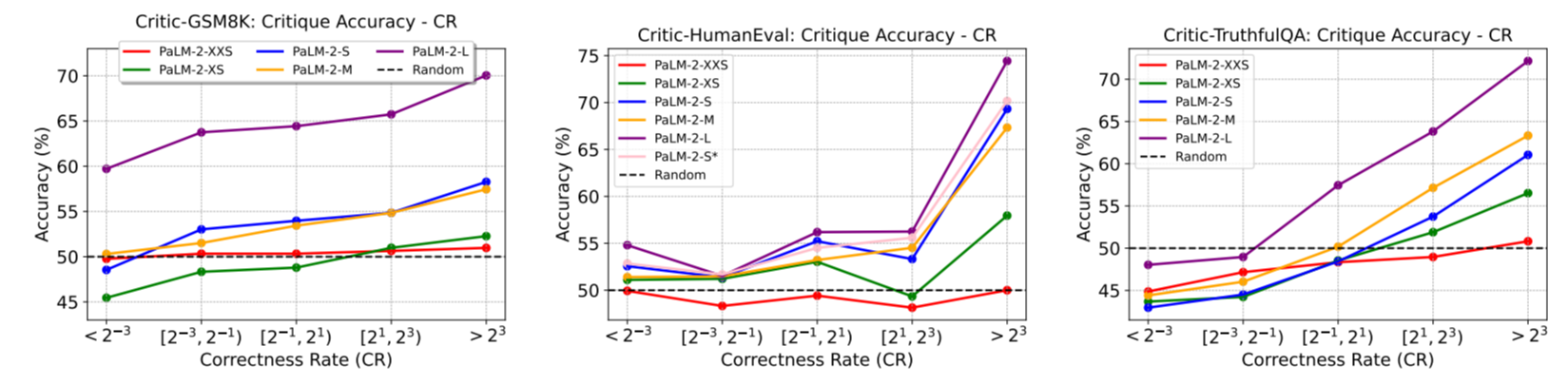 CRITICBENCH sets a new standard for evaluating LLM critiques—scalable, generalizable, and focused on quality across diverse tasks.
CRITICBENCH sets a new standard for evaluating LLM critiques—scalable, generalizable, and focused on quality across diverse tasks.
[410. Improving Text Embeddings with
Large Language Models: Related Work](https://hackernoon.com/improving-text-embeddings-with-large-language-models-related-work)
 This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
This paper introduces a novel method for generating high-quality text embeddings using synthetic data, achieving state-of-the-art results with minimal training
411. Can AI Tell Who Wrote Something Just by Analyzing Grammar?
 This study leverages statistical parsing and syntactic structures from the Penn Treebank to refine authorship detection using the Stanford Parser.
This study leverages statistical parsing and syntactic structures from the Penn Treebank to refine authorship detection using the Stanford Parser.
412. When the Words Change but the Meaning Shouldn’t: Paraphrases as Stress Loads
 How small shifts in phrasing reveal whether an agent understands intent or only echoes words.
How small shifts in phrasing reveal whether an agent understands intent or only echoes words.
413. Automated Entity and Relationship Extraction in Classical TCM Literature
 AI and NLP unravel ancient TCM texts, extracting key terms and relationships to power smarter knowledge graphs and advance medical research.
AI and NLP unravel ancient TCM texts, extracting key terms and relationships to power smarter knowledge graphs and advance medical research.
414. How LLMs Learn to Recognize Different Writing Styles
 This study explores dimension reduction techniques, optimizing feature vectors to improve authorship classification accuracy in high-dimensional data.
This study explores dimension reduction techniques, optimizing feature vectors to improve authorship classification accuracy in high-dimensional data.
415. CRITICBENCH: A Benchmark for Evaluating the Critique Abilities of LLMs
 CRITICBENCH reveals why large language models struggle with critique and self-criticism, highlighting new methods for AI self-improvement.
CRITICBENCH reveals why large language models struggle with critique and self-criticism, highlighting new methods for AI self-improvement.
416. Can Grammar Patterns Unmask a Writer’s Identity?
 This study explores different parse tree features—subtrees, rooted structures, and POS patterns—to enhance authorship classification accuracy.
This study explores different parse tree features—subtrees, rooted structures, and POS patterns—to enhance authorship classification accuracy.
417. Why Even the Best AI Struggles at Critiquing Code
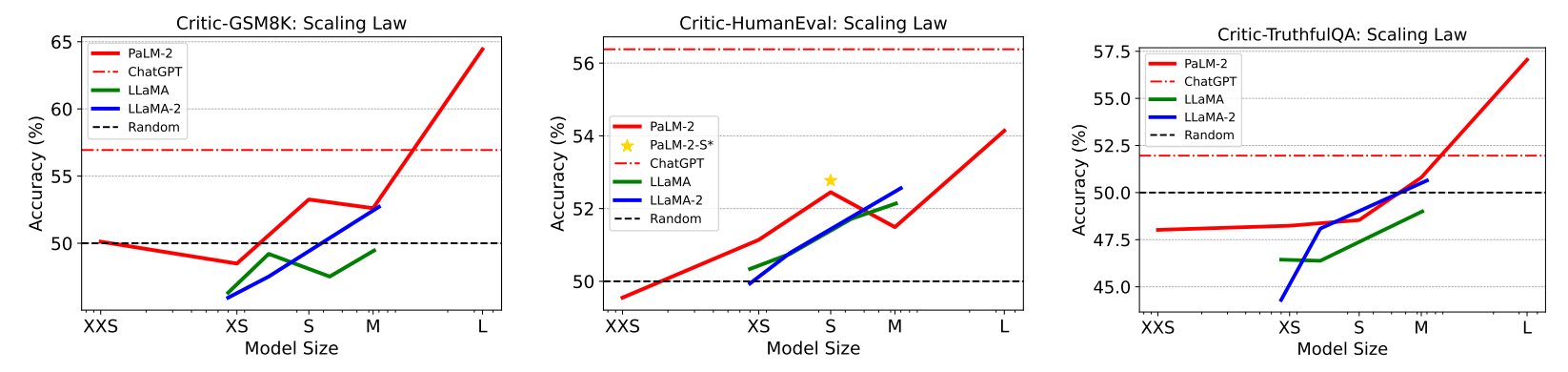 CRITICBENCH reveals how critique ability scales in LLMs, from self-critique to code evaluation, highlighting when AI becomes a true critic.
CRITICBENCH reveals how critique ability scales in LLMs, from self-critique to code evaluation, highlighting when AI becomes a true critic.
418. Critique Ability of Large Language Models: Self-Critique Ability
 How well can AI critique its own answers? Explore PaLM-2 results on self-critique, certainty metrics, and why some tasks remain out of reach.
How well can AI critique its own answers? Explore PaLM-2 results on self-critique, certainty metrics, and why some tasks remain out of reach.
419. Are Your AI Benchmarks Fooling You?
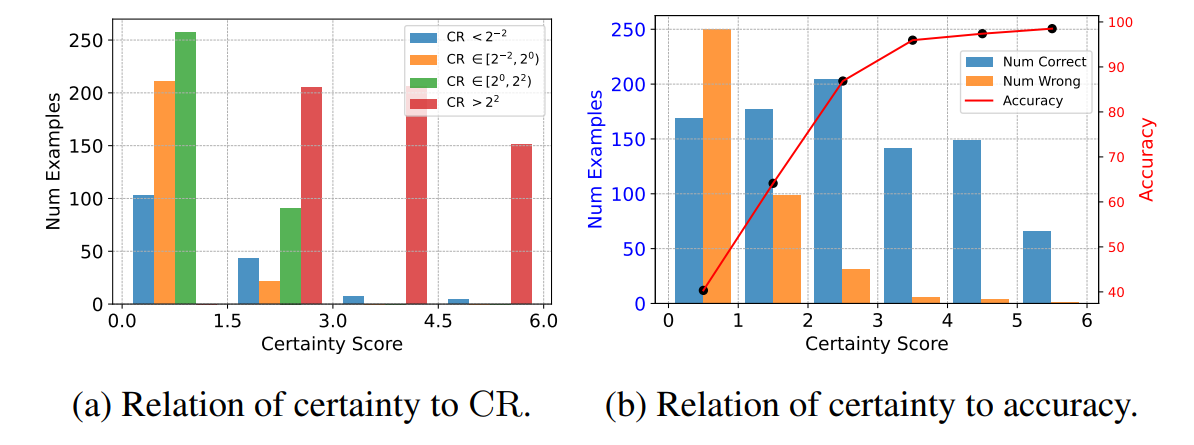 CRITICBENCH refines AI benchmarking with high-quality, certainty-based data selection to build fairer, more differentiable LLM evaluations.
CRITICBENCH refines AI benchmarking with high-quality, certainty-based data selection to build fairer, more differentiable LLM evaluations.
420. Why Smaller LLMs Fail at Critical Thinking
 Discover CRITICBENCH, the open benchmark comparing GPT-4, PaLM-2, and LLaMA on reasoning, coding, and truth-based critique tasks.
Discover CRITICBENCH, the open benchmark comparing GPT-4, PaLM-2, and LLaMA on reasoning, coding, and truth-based critique tasks.
Thank you for checking out the 420 most read blog posts about Natural Language Processing on HackerNoon.
Visit the /Learn Repo to find the most read blog posts about any technology.