

Let's learn about Data Engineering via these 347 free blog posts. They are ordered by HackerNoon reader engagement data. Visit the Learn Repo or LearnRepo.com to find the most read blog posts about any technology.
The process of designing and building systems for collecting, storing, and analyzing data at scale, foundational for data science and business intelligence initiatives.
1. 9 Best Data Engineering Courses You Should Take in 2023
 In this listicle, you'll find some of the best data engineering courses, and career paths that can help you jumpstart your data engineering journey!
In this listicle, you'll find some of the best data engineering courses, and career paths that can help you jumpstart your data engineering journey!
2. Why Are We Teaching Pandas Instead of SQL?
 How I learned to stop using pandas and love SQL.
How I learned to stop using pandas and love SQL.
3. Crunching Large Datasets Made Fast and Easy: the Polars Library
 Processing large data, e.g. for cleansing, aggregation or filtering is done blazingly fast with the Polars data frame library in python thanks to its design.
Processing large data, e.g. for cleansing, aggregation or filtering is done blazingly fast with the Polars data frame library in python thanks to its design.
4. DataOps: the Future of Data Engineering
![]() Explore the evolution of DataOps in data engineering, its parallels with DevOps, challenges it addresses, and best practices. Transformative future of DataOps.
Explore the evolution of DataOps in data engineering, its parallels with DevOps, challenges it addresses, and best practices. Transformative future of DataOps.
5. An 80% Reduction in Standard Audience Calculation Time
 Standard Audiences: A product that extends the functionality of regular Audiences, one of the most flexible, powerful, and heavily leveraged tools on mParticle.
Standard Audiences: A product that extends the functionality of regular Audiences, one of the most flexible, powerful, and heavily leveraged tools on mParticle.
6. Saving Dataframes into Oracle Database with Python
 Here are two common errors that you'll want to watch out for when using the to_sql method to save a data frame into an Oracle database.
Here are two common errors that you'll want to watch out for when using the to_sql method to save a data frame into an Oracle database.
7. Data Lake Mysteries Revealed: Nessie, Dremio, and MinIO Make Waves
 Let's see how Nessie, Dremio and MinIO work together to enhance data quality and collaboration in your data engineering workflows.
Let's see how Nessie, Dremio and MinIO work together to enhance data quality and collaboration in your data engineering workflows.
8. Python: Setting Data Types When Using 'to_sql'
 The following is a basic code snippet to save a DataFrame to an Oracle database using SQLAlchemy and pandas.
The following is a basic code snippet to save a DataFrame to an Oracle database using SQLAlchemy and pandas.
9. How To Deploy Metabase on Google Cloud Platform (GCP)?
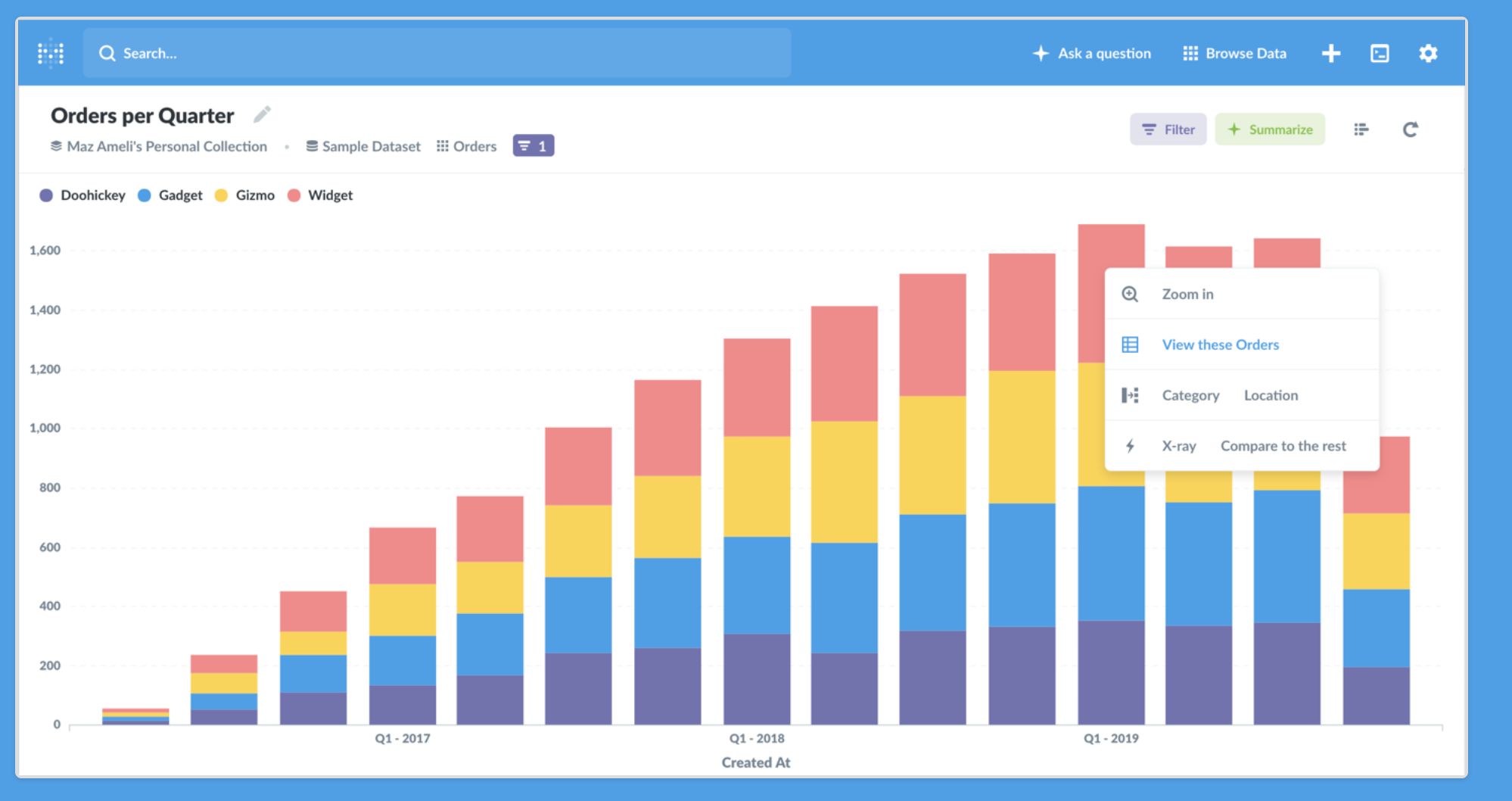 Metabase is a business intelligence tool for your organisation that plugs in various data-sources so you can explore data and build dashboards. I'll aim to provide a series of articles on provisioning and building this out for your organisation. This article is about getting up and running quickly.
Metabase is a business intelligence tool for your organisation that plugs in various data-sources so you can explore data and build dashboards. I'll aim to provide a series of articles on provisioning and building this out for your organisation. This article is about getting up and running quickly.
10. Everything You Need to Know to Deploy MinIO in Virtualized Environments
 When deploying MinIO in virtualized environments, it’s important to make sure that the proper conditions are in place.
When deploying MinIO in virtualized environments, it’s important to make sure that the proper conditions are in place.
11. Aptible Enclave: Elevating Data Security in DevOps Environments
 Aptible Enclave fortifies data security in DevOps with its secure infrastructure for database management.
Aptible Enclave fortifies data security in DevOps with its secure infrastructure for database management.
12. Stop Hacking SQL: How to Build a Scalable Query Automation System
 Result: predictable costs, fewer incidents, reproducible jobs across environments.
Result: predictable costs, fewer incidents, reproducible jobs across environments.
13. Must-Know Base Tips for Feature Engineering With Time Series Data
 Master key time series feature engineering techniques to enhance predictive models in finance, healthcare & more with our comprehensive guide.
Master key time series feature engineering techniques to enhance predictive models in finance, healthcare & more with our comprehensive guide.
14. What The Heck is WarpStream?
 Discover WarpStream, a powerful and user-friendly Kafka API-compatible data streaming platform designed to simplify your data infrastructure.
Discover WarpStream, a powerful and user-friendly Kafka API-compatible data streaming platform designed to simplify your data infrastructure.
15. Data Contracts Won't Save You If Your AI Agent Can't Read Them
 We built data governance for a world where humans read the warning labels. AI agents don't read. They just query. That gap is now a production risk.
We built data governance for a world where humans read the warning labels. AI agents don't read. They just query. That gap is now a production risk.
16. Protecting Software-defined Object Storage With MinIO's Replication Best Practices
 MinIO includes several ways to replicate data so you can choose the best methodology to meet your needs.
MinIO includes several ways to replicate data so you can choose the best methodology to meet your needs.
17. How Machine Learning is Used in Astronomy
 Is Astronomy data science?
Is Astronomy data science?
18. RAG: A Data Problem Disguised as AI
 RAG fails less from the LLM and more from retrieval: bad chunking, weak metadata, embedding drift, and stale indexes. Fix the pipeline first.
RAG fails less from the LLM and more from retrieval: bad chunking, weak metadata, embedding drift, and stale indexes. Fix the pipeline first.
19. Solving Time Series Forecasting Problems: Principles and Techniques
 Explore time series analysis: from cross-validation, decomposition, transformation to advanced modeling with ARIMA, Neural Networks, and more.
Explore time series analysis: from cross-validation, decomposition, transformation to advanced modeling with ARIMA, Neural Networks, and more.
20. Python Script to Read and Judge 1,500 Legal Cases
 What started as a simple script evolved into a full-fledged data engineering and NLP pipeline that can process a decade's worth of legal decisions in minutes.
What started as a simple script evolved into a full-fledged data engineering and NLP pipeline that can process a decade's worth of legal decisions in minutes.
21. Data Engineering: An Interview with Meta Engineer Leonid Chashnikov
 As we sit down for this exclusive interview, Leonid offers a rare glimpse into the intricate process of weaving the digital fabric that shapes our lives.
As we sit down for this exclusive interview, Leonid offers a rare glimpse into the intricate process of weaving the digital fabric that shapes our lives.
22. Streamlining Data Operations: How a Grocery Chain Optimizes Workloads with Apache Doris
 Cross-cluster replication (CCR) in Apache Doris is proven to be fast, stable, and easy to use. It secures a real-time data synchronization latency of 1 second.
Cross-cluster replication (CCR) in Apache Doris is proven to be fast, stable, and easy to use. It secures a real-time data synchronization latency of 1 second.
23. Performance Benchmark: Apache Spark on DataProc Vs. Google BigQuery

When it comes to Big Data infrastructure on Google Cloud Platform , the most popular choices Data architects need to consider today are Google BigQuery – A serverless, highly scalable and cost-effective cloud data warehouse, Apache Beam based Cloud Dataflow and Dataproc – a fully managed cloud service for running Apache Spark and Apache Hadoop clusters in a simpler, more cost-efficient way.
24. Build vs Buy: What We Learned by Implementing a Data Catalog
 Why we chose to finally buy a unified data workspace (Atlan), after spending 1.5 years building our own internal solution with Amundsen and Atlas
Why we chose to finally buy a unified data workspace (Atlan), after spending 1.5 years building our own internal solution with Amundsen and Atlas
25. How To Build An n8n Workflow To Manage Different Databases and Scheduling Workflows
 Learn how to build an n8n workflow that processes text, stores data in two databases, and sends messages to Slack.
Learn how to build an n8n workflow that processes text, stores data in two databases, and sends messages to Slack.
26. Build A Crypto Price Tracker using Node.js and Cassandra
 Since the big bang in the data technology landscape happened a decade and a half ago, giving rise to technologies like Hadoop, which cater to the four ‘V’s. — volume, variety, velocity, and veracity there has been an uptick in the use of databases with specialized capabilities to cater to different types of data and usage patterns. You can now see companies using graph databases, time-series databases, document databases, and others for different customer and internal workloads.
Since the big bang in the data technology landscape happened a decade and a half ago, giving rise to technologies like Hadoop, which cater to the four ‘V’s. — volume, variety, velocity, and veracity there has been an uptick in the use of databases with specialized capabilities to cater to different types of data and usage patterns. You can now see companies using graph databases, time-series databases, document databases, and others for different customer and internal workloads.
27. How to Scrape NLP Datasets From Youtube
 Too lazy to scrape nlp data yourself? In this post, I’ll show you a quick way to scrape NLP datasets using Youtube and Python.
Too lazy to scrape nlp data yourself? In this post, I’ll show you a quick way to scrape NLP datasets using Youtube and Python.
28. 30 BI Engineering Interview Questions That Actually Matter in the AI Era
 The BI interview hasn't caught up with the job. Here are 30 questions that reflect what it actually means to be a BI engineer in 2026.
The BI interview hasn't caught up with the job. Here are 30 questions that reflect what it actually means to be a BI engineer in 2026.
29. What the Heck is OpenMetadata?
 Everything you've ever wanted to learn about OpenMetadata.
Everything you've ever wanted to learn about OpenMetadata.
30. What the Heck Is SDF?
 Is dbt kicking your butt? Take a look at SDF.
Is dbt kicking your butt? Take a look at SDF.
31. How To Create a Python Data Engineering Project with a Pipeline Pattern
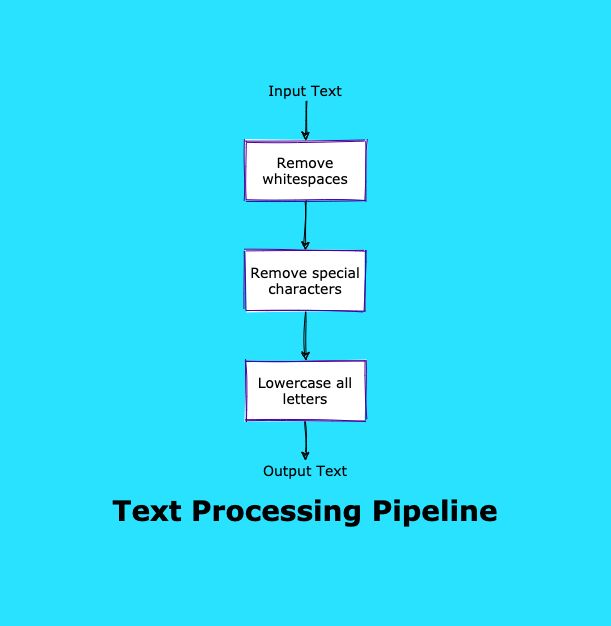 In this article, we cover how to use pipeline patterns in python data engineering projects. Create a functional pipeline, install fastcore, and other steps.
In this article, we cover how to use pipeline patterns in python data engineering projects. Create a functional pipeline, install fastcore, and other steps.
32. What is a Data Reliability Engineer?
 With each day, enterprises increasingly rely on data to make decisions.
With each day, enterprises increasingly rely on data to make decisions.
33. What the heck is Apache SeaTunnel?
 What is Apache SeaTunnel, and can it help you with your data engineering?
What is Apache SeaTunnel, and can it help you with your data engineering?
34. From Satellite Signals to Neural Networks
 See how Andrei Shcherbinin built production-ready ML systems with 12x faster attribution, 95% chatbot automation, and stronger monitoring.
See how Andrei Shcherbinin built production-ready ML systems with 12x faster attribution, 95% chatbot automation, and stronger monitoring.
35. An Architect's Guide to Machine Learning Operations and Required Data Infrastructure
 MLOps is a set of practices and tools aimed at addressing the specific needs of engineers building models and moving them into production.
MLOps is a set of practices and tools aimed at addressing the specific needs of engineers building models and moving them into production.
36. A Guide For Data Quality Monitoring with Amazon Deequ
 Monitor data quality with Amazon Deequ, InfluxDB, and Grafana in a Dockerized environment using Scala/Java and Apache Spark.
Monitor data quality with Amazon Deequ, InfluxDB, and Grafana in a Dockerized environment using Scala/Java and Apache Spark.
37. AI Native Data Pipeline - What Do We Need?
 A new generation of AI-native data pipelines is emerging — built for unstructured data, dynamic schemas, and LLM-powered workloads.
A new generation of AI-native data pipelines is emerging — built for unstructured data, dynamic schemas, and LLM-powered workloads.
38. Is The Modern Data Warehouse Dead?
 Do we need a radical new approach to data warehouse technology? An immutable data warehouse starts with the data consumer SLAs and pipes data in pre-modeled.
Do we need a radical new approach to data warehouse technology? An immutable data warehouse starts with the data consumer SLAs and pipes data in pre-modeled.
39. Python & Data Engineering: Under the Hood of Join Operators
 In this post, I discuss the algorithms of a nested loop, hash join, and merge join in Python.
In this post, I discuss the algorithms of a nested loop, hash join, and merge join in Python.
40. The Future of Gaming: Leveraging Data Engineering to Revolutionize Player Experience
 Explore how data engineering revolutionizes gaming with AI, AR/VR, blockchain, and more, enabling immersive experiences and shaping the industry's future.
Explore how data engineering revolutionizes gaming with AI, AR/VR, blockchain, and more, enabling immersive experiences and shaping the industry's future.
41. What the Heck is dbc?
 An overview of dbc, an online open-source tool to facilitate adbc and apache arrow.
An overview of dbc, an online open-source tool to facilitate adbc and apache arrow.
42. Hot-Cold Data Separation: How It Cuts Your Storage Costs by 70%
 Apparently hot-cold data separation is hot now. Let's figure out why.
Apparently hot-cold data separation is hot now. Let's figure out why.
43. Scale Your Data Pipelines with Airflow and Kubernetes
 It doesn’t matter if you are running background tasks, preprocessing jobs or ML pipelines. Writing tasks is the easy part. The hard part is the orchestration— Managing dependencies among tasks, scheduling workflows and monitor their execution is tedious.
It doesn’t matter if you are running background tasks, preprocessing jobs or ML pipelines. Writing tasks is the easy part. The hard part is the orchestration— Managing dependencies among tasks, scheduling workflows and monitor their execution is tedious.
44. How to Perform Data Augmentation with Augly Library
 Data augmentation is a technique used by practitioners to increase the data by creating modified data from the existing data.
Data augmentation is a technique used by practitioners to increase the data by creating modified data from the existing data.
45. Influenza Vaccines: The Data Science Behind Them

46. R Systems Blogbook—Chapter 1 is Now Open for Submissions🎉
 Round 1 of the R Systems BlogBook: Chapter 1 contest is now live! Showcase your expertise, participate, and win exciting prizes. Submit your entry today!
Round 1 of the R Systems BlogBook: Chapter 1 contest is now live! Showcase your expertise, participate, and win exciting prizes. Submit your entry today!
47. What the Heck Is LanceDB?
 Learn about LanceDB and how it fits into a stack that allows you to more easily create your own LLM models
Learn about LanceDB and how it fits into a stack that allows you to more easily create your own LLM models
48. How to Build a Directed Acyclic Graph (DAG) - Towards Open Options Chains Part IV
 In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.
In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.
49. Optimizing JOIN Operations in Google BigQuery: Strategies to Overcome Performance Challenges
 In this article, we explore these challenges and present a strategic approach to optimize JOINs in BigQuery.
In this article, we explore these challenges and present a strategic approach to optimize JOINs in BigQuery.
50. Turn Your PDF Library into a Searchable Research Database with 100 Lines of Code
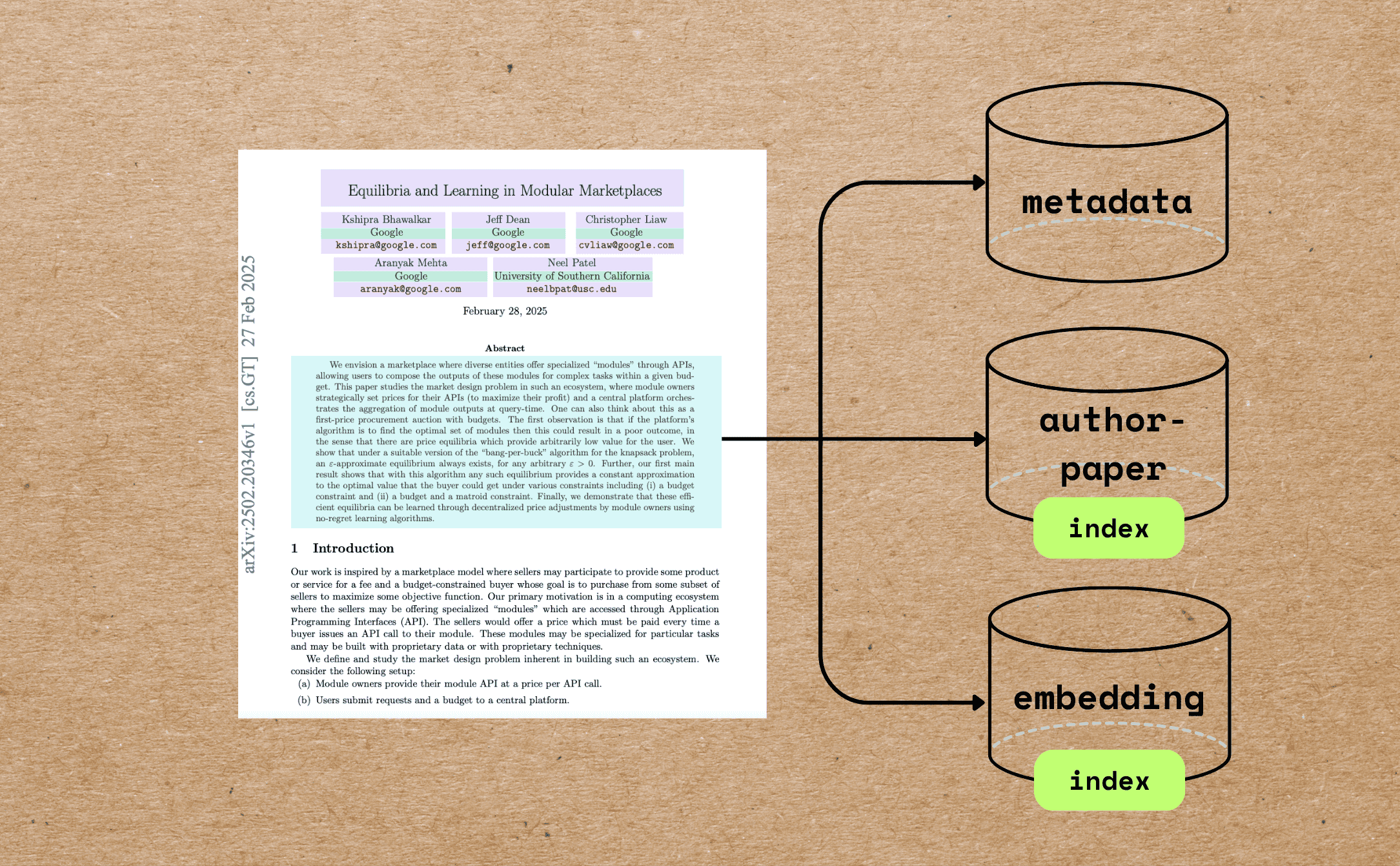 How to index academic research papers by extracting metadata (e.g., title, authors, abstract) for AI agents and AI workflows using LLMs and CocoIndex.
How to index academic research papers by extracting metadata (e.g., title, authors, abstract) for AI agents and AI workflows using LLMs and CocoIndex.
51. One Off to One Data Platform: Designing Data Platforms with Scalable Intent [Part 2]
 Introducing a data platform architecture framework that enables organizations to systematically design and implement scalable data platform.
Introducing a data platform architecture framework that enables organizations to systematically design and implement scalable data platform.
52. What You Already Know About Big Data
 Every micro-interaction is silently recorded, analyzed, and monetized.
Every micro-interaction is silently recorded, analyzed, and monetized.
53. What DevOps for Data Really Means
 DevOps for Data is not about fixing pipelines or deploying models. It’s about designing systems that remain reliable, secure, and predictable.
DevOps for Data is not about fixing pipelines or deploying models. It’s about designing systems that remain reliable, secure, and predictable.
54. Top 6 CI/CD Practices for End-to-End Development Pipelines
 Maximizing efficiency is about knowing how the data science puzzles fit together and then executing them.
Maximizing efficiency is about knowing how the data science puzzles fit together and then executing them.
55. Langchain: Explained and Getting Started
 Langchain is a crucial component for developing LLM models. It helps in orchestration and act as building block
Langchain is a crucial component for developing LLM models. It helps in orchestration and act as building block
56. Meet The Entrepreneur: Alon Lev, CEO, Qwak
 Meet The Entrepreneur: Alon Lev, CEO, Qwak
Meet The Entrepreneur: Alon Lev, CEO, Qwak
57. How to Extract and Embed Text and Images from PDFs for Unified Semantic Search
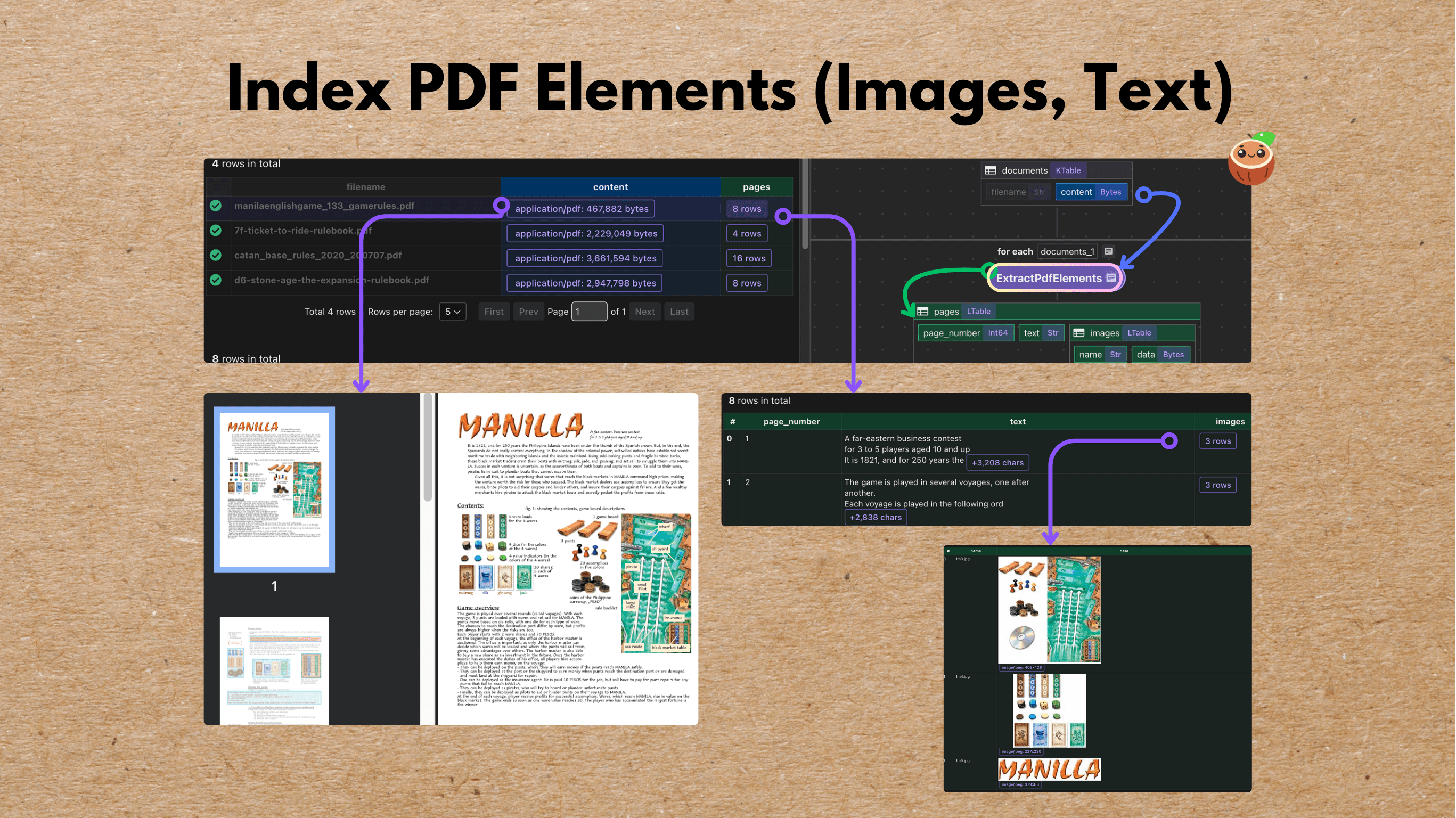 Extracts, embeds, and stores multimodal PDF elements — text with SentenceTransformers and images with CLIP — in vector database for unified semantic search.
Extracts, embeds, and stores multimodal PDF elements — text with SentenceTransformers and images with CLIP — in vector database for unified semantic search.
58. Certify Your Data Assets to Avoid Treating Your Data Engineers Like Catalogs
 Data trust starts and ends with communication. Here’s how best-in-class data teams are certifying tables as approved for use across their organization.
Data trust starts and ends with communication. Here’s how best-in-class data teams are certifying tables as approved for use across their organization.
59. What is the Future of the Data Engineer? - 6 Industry Drivers
 Is the data engineer still the "worst seat at the table?" Maxime Beauchemin, creator of Apache Airflow and Apache Superset, weighs in.
Is the data engineer still the "worst seat at the table?" Maxime Beauchemin, creator of Apache Airflow and Apache Superset, weighs in.
60. LLMs in Data Engineering: Not Just Hype, Here’s What’s Real
 Large Language Models (LLMs) represent artificial intelligence systems which learn human language from massive text databases.
Large Language Models (LLMs) represent artificial intelligence systems which learn human language from massive text databases.
61. Who Will Eventually Control Big Data in Web3?
 Web 3 is loudly making rounds as a decentralized internet. How will this affect data control in general?
Web 3 is loudly making rounds as a decentralized internet. How will this affect data control in general?
62. How to Get Started with Data Version Control (DVC)
 Data Version Control (DVC) is a data-focused version of Git. In fact, it’s almost exactly like Git in terms of features and workflows associated with it.
Data Version Control (DVC) is a data-focused version of Git. In fact, it’s almost exactly like Git in terms of features and workflows associated with it.
63. 10 Key Skills Every Data Engineer Needs
 Bridging the gap between Application Developers and Data Scientists, the demand for Data Engineers rose up to 50% in 2020, especially due to increase in investments in AI-based SaaS products.
Bridging the gap between Application Developers and Data Scientists, the demand for Data Engineers rose up to 50% in 2020, especially due to increase in investments in AI-based SaaS products.
64. PandasAI: Chat with Your Data, Literally
 PandasAI is an open-source tool that makes data analysis feel like a casual chat with a data-savvy friend.
PandasAI is an open-source tool that makes data analysis feel like a casual chat with a data-savvy friend.
65. Building a Large-Scale Interactive SQL Query Engine with Open Source Software
 This is a collaboration between Baolong Mao's team at JD.com and my team at Alluxio. The original article was published on Alluxio's blog. This article describes how JD built an interactive OLAP platform combining two open-source technologies: Presto and Alluxio.
This is a collaboration between Baolong Mao's team at JD.com and my team at Alluxio. The original article was published on Alluxio's blog. This article describes how JD built an interactive OLAP platform combining two open-source technologies: Presto and Alluxio.
66. How To Productionalize ML By Development Of Pipelines Since The Beginning
 Writing ML code as pipelines from the get-go reduces technical debt and increases velocity of getting ML in production.
Writing ML code as pipelines from the get-go reduces technical debt and increases velocity of getting ML in production.
67. Data Engineering Tools for Geospatial Data
 Location-based information makes the field of geospatial analytics so popular today. Collecting useful data requires some unique tools covered in this blog.
Location-based information makes the field of geospatial analytics so popular today. Collecting useful data requires some unique tools covered in this blog.
68. What the Heck is Apache Iggy?
 Apache Kafka has gotten rather long in the tooth, is Apache Iggy the successor?
Apache Kafka has gotten rather long in the tooth, is Apache Iggy the successor?
69. Why Distributed Systems Can’t Have It All
 Modern distributed systems are all about tradeoffs. Performance, reliability, scalability, and consistency don't come for free—you always pay a price somewhere.
Modern distributed systems are all about tradeoffs. Performance, reliability, scalability, and consistency don't come for free—you always pay a price somewhere.
70. The Emerging Data Engineering Trends You Should Check Out In 2024
 Integrating data engineering with AI has led to the popularity of modern data integration and the expertise required.
Integrating data engineering with AI has led to the popularity of modern data integration and the expertise required.
71. Want to Create Data Circuit Breakers with Airflow? Here's How!
 See how to leverage the Airflow ShortCircuitOperator to create data circuit breakers to prevent bad data from reaching your data pipelines.
See how to leverage the Airflow ShortCircuitOperator to create data circuit breakers to prevent bad data from reaching your data pipelines.
72. How to Build Machine Learning Algorithms that Actually Work
 Applying machine learning models at scale in production can be hard. Here's the four biggest challenges data teams face and how to solve them.
Applying machine learning models at scale in production can be hard. Here's the four biggest challenges data teams face and how to solve them.
73. Hands-on with Apache Iceberg on Your Laptop: Deep Dive with Apache Spark, Nessie, Minio and more!
 Get hands-on with Apache Iceberg by building a prototype data lakehouse on your laptop.
Get hands-on with Apache Iceberg by building a prototype data lakehouse on your laptop.
74. What The Heck is DeltaStream?
 A brief run-through of DeltaStream and how it simplifies working with streaming data such as Kinesis and Apache Kafka, taking advantage of Apache Flink.
A brief run-through of DeltaStream and how it simplifies working with streaming data such as Kinesis and Apache Kafka, taking advantage of Apache Flink.
75. An Introduction to Data Connectors: Your First Step to Data Analytics
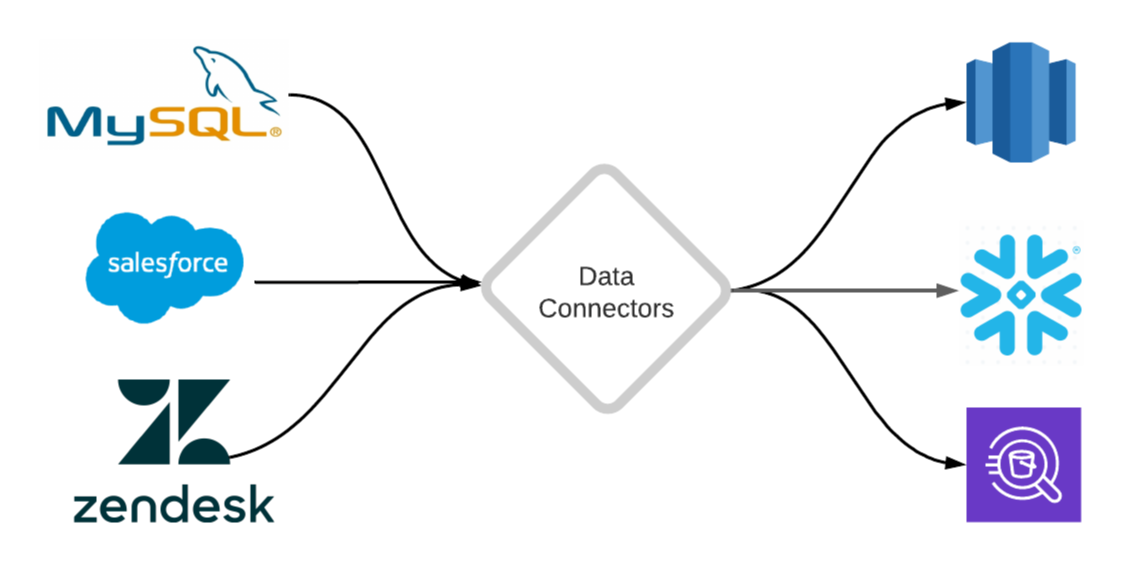 This post explains what a data connector is and provides a framework for building connectors that replicate data from different sources into your data warehouse
This post explains what a data connector is and provides a framework for building connectors that replicate data from different sources into your data warehouse
76. How To Build a Multilingual Text-to-Audio Converter With Python
 Learn how to build a multilingual text-to-audio converter using Python. This guide covers essential libraries, techniques, and best practices
Learn how to build a multilingual text-to-audio converter using Python. This guide covers essential libraries, techniques, and best practices
77. LinkedIn's Skills Graph: Paving the Way for the Skills-First Economy with AI and Ontology
 What is a skills-based economy and how is LinkedIn moving from vision to implementation? There’s AI, taxonomy and ontology involved in building the Skills Graph
What is a skills-based economy and how is LinkedIn moving from vision to implementation? There’s AI, taxonomy and ontology involved in building the Skills Graph
78. Breaking Down Data Silos: How Apache Doris Streamlines Customer Data Integration
 Learn how Apache Doris breaks down data silos for insurance firms, streamlining customer data integration and boosting efficiency.
Learn how Apache Doris breaks down data silos for insurance firms, streamlining customer data integration and boosting efficiency.
79. The Growth Marketing Writing Contest by mParticle and HackerNoon
 mParticle & HackerNoon are excited to host a Growth Marketing Writing Contest. Here’s your chance to win money from a whopping $12,000 prize pool!
mParticle & HackerNoon are excited to host a Growth Marketing Writing Contest. Here’s your chance to win money from a whopping $12,000 prize pool!
80. The Two Types of Data Engineers You Meet at Work
 Discover different archetypes of data engineers and how their collaboration drives data-driven success.
Discover different archetypes of data engineers and how their collaboration drives data-driven success.
81. Docker Dev Workflow for Apache Spark
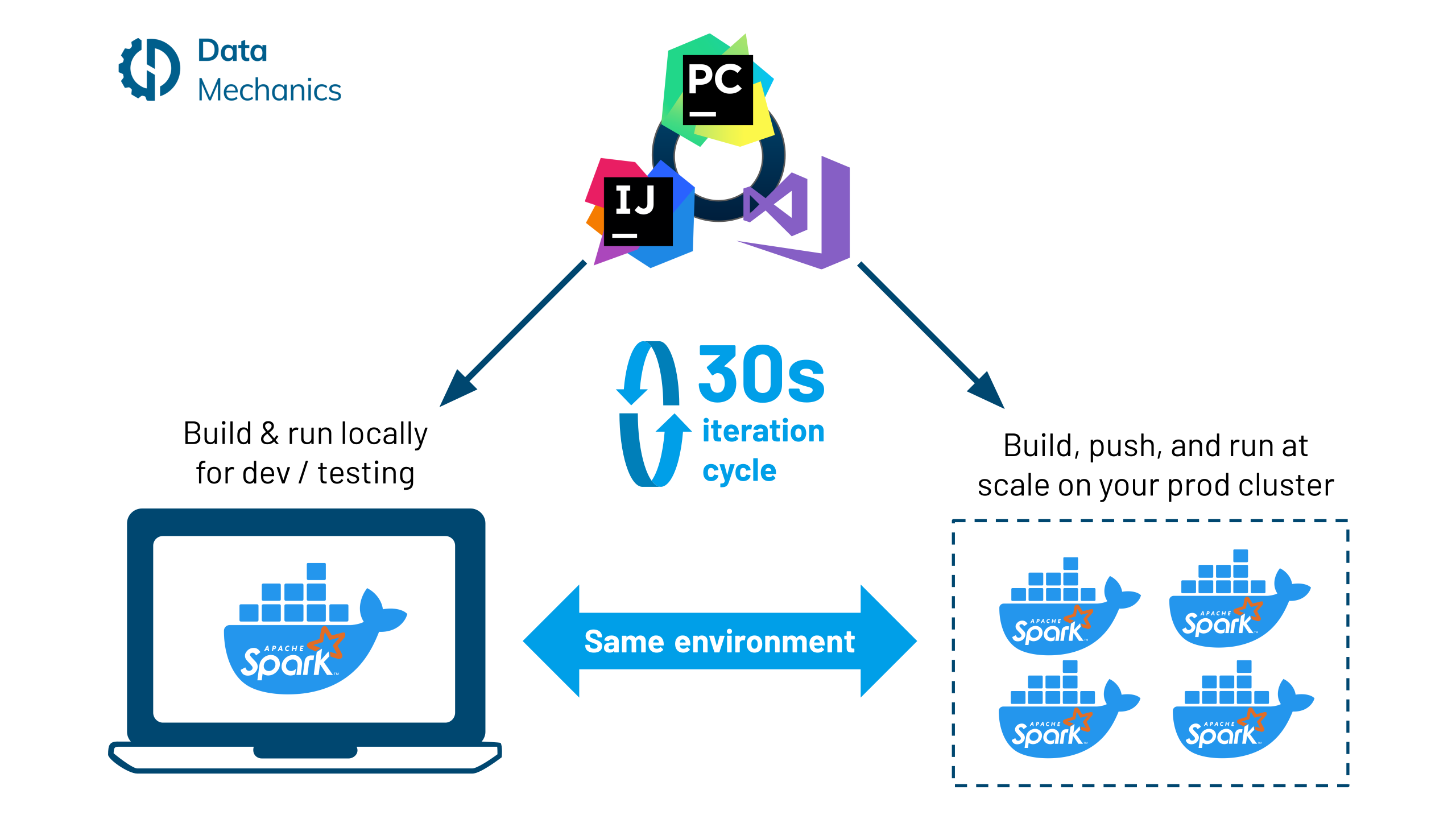 The benefits that come with using Docker containers are well known: they provide consistent and isolated environments so that applications can be deployed anywhere - locally, in dev / testing / prod environments, across all cloud providers, and on-premise - in a repeatable way.
The benefits that come with using Docker containers are well known: they provide consistent and isolated environments so that applications can be deployed anywhere - locally, in dev / testing / prod environments, across all cloud providers, and on-premise - in a repeatable way.
82. Google & Yale Turned Biology Into a Language Here's Why That's a Game-Changer for Devs
 The team built a 27B parameter model that didn't just analyze biological data—it made a novel, wet-lab-validated scientific discovery
The team built a 27B parameter model that didn't just analyze biological data—it made a novel, wet-lab-validated scientific discovery
83. How to Scale AI Infrastructure With Kubernetes and Docker
 Firms increasingly make use of artificial intelligence (AI) infrastructures to host and manage autonomous workloads.
Firms increasingly make use of artificial intelligence (AI) infrastructures to host and manage autonomous workloads.
84. How to Think Like a Data Systems Engineer: The Questions That Save You Later
 Learn how engineers think about reliability, scalability, and maintainability—by asking the right questions early.
Learn how engineers think about reliability, scalability, and maintainability—by asking the right questions early.
85. Introduction to Great Expectations, an Open Source Data Science Tool
 This is the first completed webinar of our “Great Expectations 101” series. The goal of this webinar is to show you what it takes to deploy and run Great Expectations successfully.
This is the first completed webinar of our “Great Expectations 101” series. The goal of this webinar is to show you what it takes to deploy and run Great Expectations successfully.
86. How We Use dbt (Client) In Our Data Team
 Here is not really an article, but more some notes about how we use dbt in our team.
Here is not really an article, but more some notes about how we use dbt in our team.
87. Introducing Handoff: Serverless Data Pipeline Orchestration Framework

88. Advancing Data Quality: Exploring Data Contracts with Lyft
 Keen to delve into data contracts and discover how they can enhance your data quality? Join me as we explore Lyft's Verity data contract approach together!
Keen to delve into data contracts and discover how they can enhance your data quality? Join me as we explore Lyft's Verity data contract approach together!
89. Understand Apache Airflow in 2024: Hints by Data Scientist
 A great guide, on how to learn Apache Airflow from scratch in 2024. This article covers basic concepts of Airflow and useful for Data Scientist, Data Engineers
A great guide, on how to learn Apache Airflow from scratch in 2024. This article covers basic concepts of Airflow and useful for Data Scientist, Data Engineers
90. Your Machine Learning Model Doesn’t Need a Server Anymore
 Discover how serverless AI/ML pipelines streamline data engineering by automating scalable data processing and deployment without infrastructure management.
Discover how serverless AI/ML pipelines streamline data engineering by automating scalable data processing and deployment without infrastructure management.
91. Breaking Down the Worker Task Execution in Apache DolphinScheduler
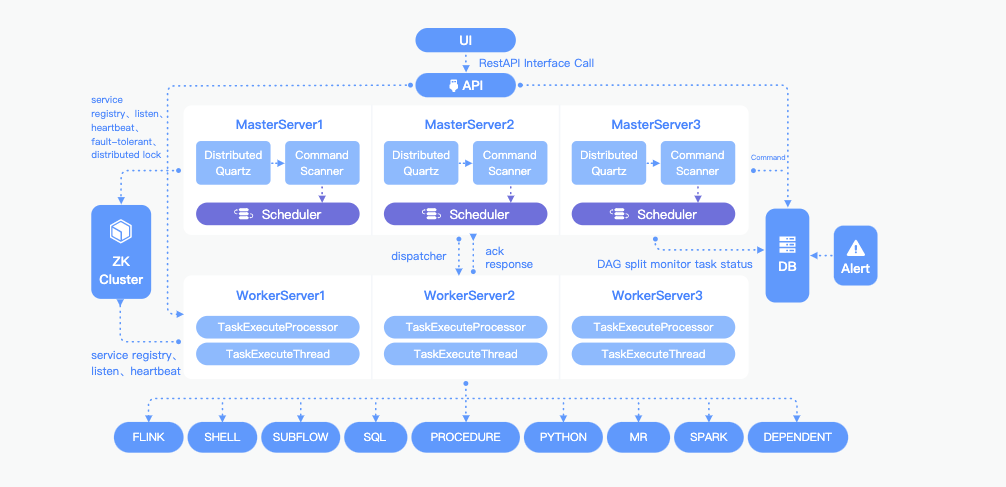 Discover how Apache DolphinScheduler's Worker tasks function within its distributed, open-source workflow scheduling system.
Discover how Apache DolphinScheduler's Worker tasks function within its distributed, open-source workflow scheduling system.
92. How to Design Customizable Data Indexing Pipelines
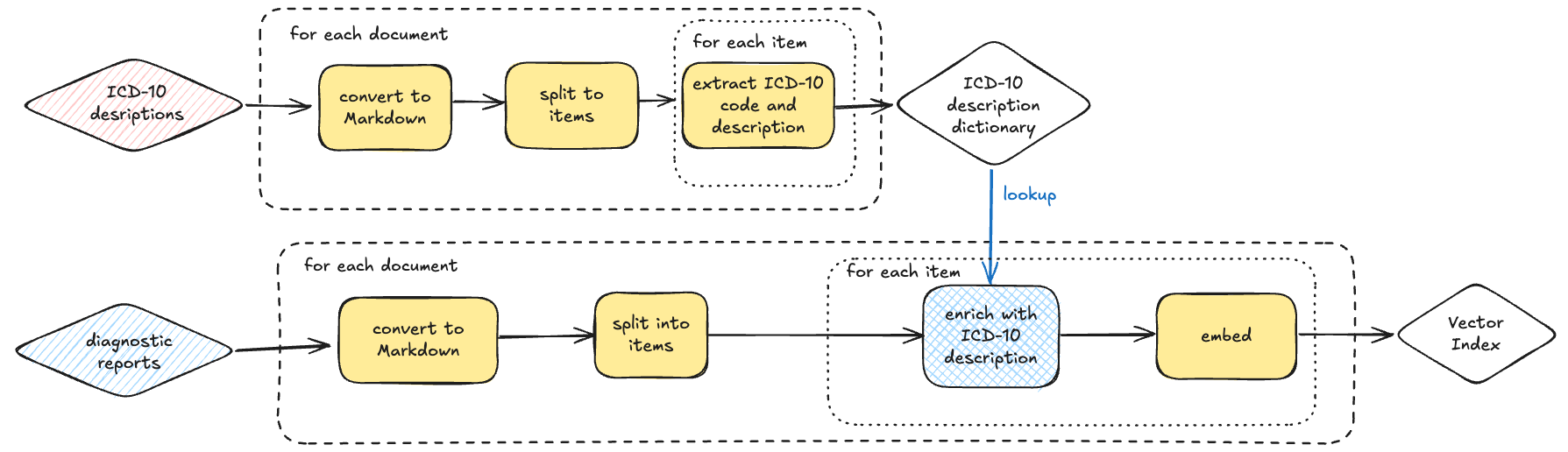 Learn how custom transformation logic enhances data indexing with AI, vector search, TF-IDF, metadata enrichment, and optimized document chunking.
Learn how custom transformation logic enhances data indexing with AI, vector search, TF-IDF, metadata enrichment, and optimized document chunking.
93. Data Teams Need Better KPIs. Here's How.
 Here are six important steps for setting goals for data teams.
Here are six important steps for setting goals for data teams.
94. Coming Soon: R Systems BlogBook – Chapter 1, Powered by HackerNoon
 The R Systems BlogBook contest, powered by HackerNoon, is coming soon! Get ready to share your experiences and win exciting prizes—stay tuned for more details.
The R Systems BlogBook contest, powered by HackerNoon, is coming soon! Get ready to share your experiences and win exciting prizes—stay tuned for more details.
95. Creating Data Pipelines With Apache Airflow and MinIO
 MinIO is the perfect companion for Airflow because of its industry-leading performance and scalability, which puts every data-intensive workload within reach.
MinIO is the perfect companion for Airflow because of its industry-leading performance and scalability, which puts every data-intensive workload within reach.
96. Best Types of Data Visualization
 Learning about best data visualisation tools may be the first step in utilising data analytics to your advantage and the benefit of your company
Learning about best data visualisation tools may be the first step in utilising data analytics to your advantage and the benefit of your company
97. Context Rot Is Breaking Long AI Sessions
 Bigger context windows help, but not enough. Learn how Recursive Language Models improve long-context reasoning with better scaling and stable performance.
Bigger context windows help, but not enough. Learn how Recursive Language Models improve long-context reasoning with better scaling and stable performance.
98. Step-by-Step Guide to SQL Operations in Dremio and Apache Iceberg
 Learn to set up a robust data lakehouse environment with Apache Iceberg, Dremio, and Nessie for scalable SQL operations.
Learn to set up a robust data lakehouse environment with Apache Iceberg, Dremio, and Nessie for scalable SQL operations.
99. Data Drama: Navigating the Spark-Flink Dilemma
 Explore Apache Flink and Spark in real-world business scenarios. Choose the right tool for your big data needs
Explore Apache Flink and Spark in real-world business scenarios. Choose the right tool for your big data needs
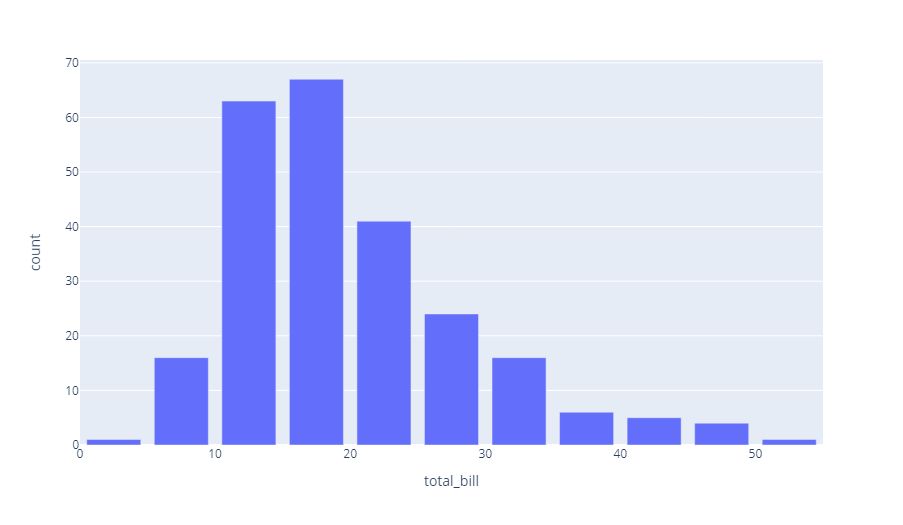
100. How to Build a Data Dashboard Using Airbyte and Streamlit
 In this tutorial, we built a real-time data dashboard using Airbyte and Streamlit, in Python programming language.
In this tutorial, we built a real-time data dashboard using Airbyte and Streamlit, in Python programming language.
101. Trying to Scale Apache Kafka? Consider Using Apache Pulsar
 We compare the differences between Kafka and Pulsar, demonstrating how a logical next step for scalability when using Kafka is switching to Pulsar.
We compare the differences between Kafka and Pulsar, demonstrating how a logical next step for scalability when using Kafka is switching to Pulsar.
102. From Centralized to Federated: Evolving Data Governance Operating Model
 See how a federated data governance model address challenges of centralized systems by enabling flexibility, regulatory compliance, and innovation for business
See how a federated data governance model address challenges of centralized systems by enabling flexibility, regulatory compliance, and innovation for business
103. How to Flatten Nested JSON and XML in Apache Spark
 Flatten nested JSON and XML dynamically in Spark using a recursive PySpark function for analytics-ready data without hardcoding.
Flatten nested JSON and XML dynamically in Spark using a recursive PySpark function for analytics-ready data without hardcoding.
104. How to Setup Your Organisation's Data Team for Success
 Best practices for building a data team at a hypergrowth startup, from hiring your first data engineer to IPO.
Best practices for building a data team at a hypergrowth startup, from hiring your first data engineer to IPO.
105. Why Multimodal AI Broke the Data Pipeline — And How Daft Is Beating Ray and Spark to Fix It
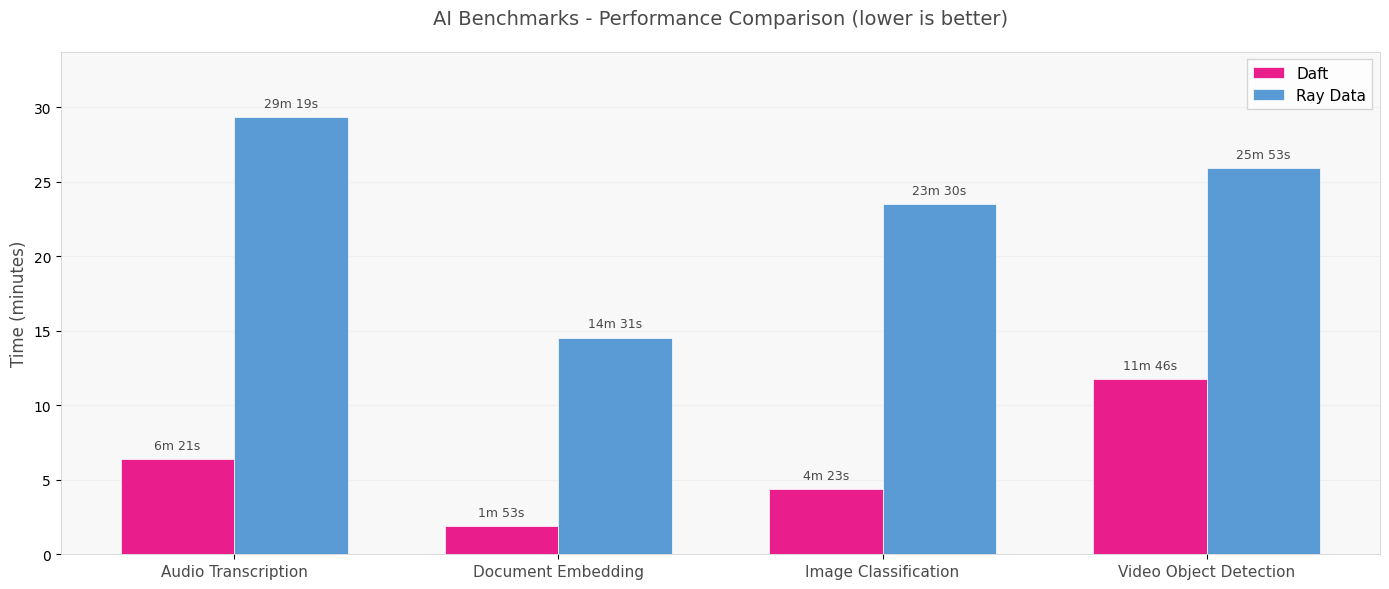 Multimodal AI workloads are breaking Spark and Ray. See how Daft’s streaming model runs 7× faster and more reliably across audio, video, and image pipelines.
Multimodal AI workloads are breaking Spark and Ray. See how Daft’s streaming model runs 7× faster and more reliably across audio, video, and image pipelines.
106. Using Arrow Flight SQL Protocol in Apache Doris 2.1 For Super Fast Data Transfer
 Apache Doris 2.1 just got a major speed boost with Arrow Flight SQL for up to 10x faster data transfers.
Apache Doris 2.1 just got a major speed boost with Arrow Flight SQL for up to 10x faster data transfers.
107. Machine-Learning Neural Spatiotemporal Signal Processing with PyTorch Geometric Temporal
 PyTorch Geometric Temporal is a deep learning library for neural spatiotemporal signal processing.
PyTorch Geometric Temporal is a deep learning library for neural spatiotemporal signal processing.
108. Writing Pandas to Make Your Python Code Scale
 Write efficient and flexible data-pipelines in Python that generalise to changing requirements.
Write efficient and flexible data-pipelines in Python that generalise to changing requirements.
109. Seamlessly Migrate Your On-Premise Data Pipeline to Azure with These Key Steps
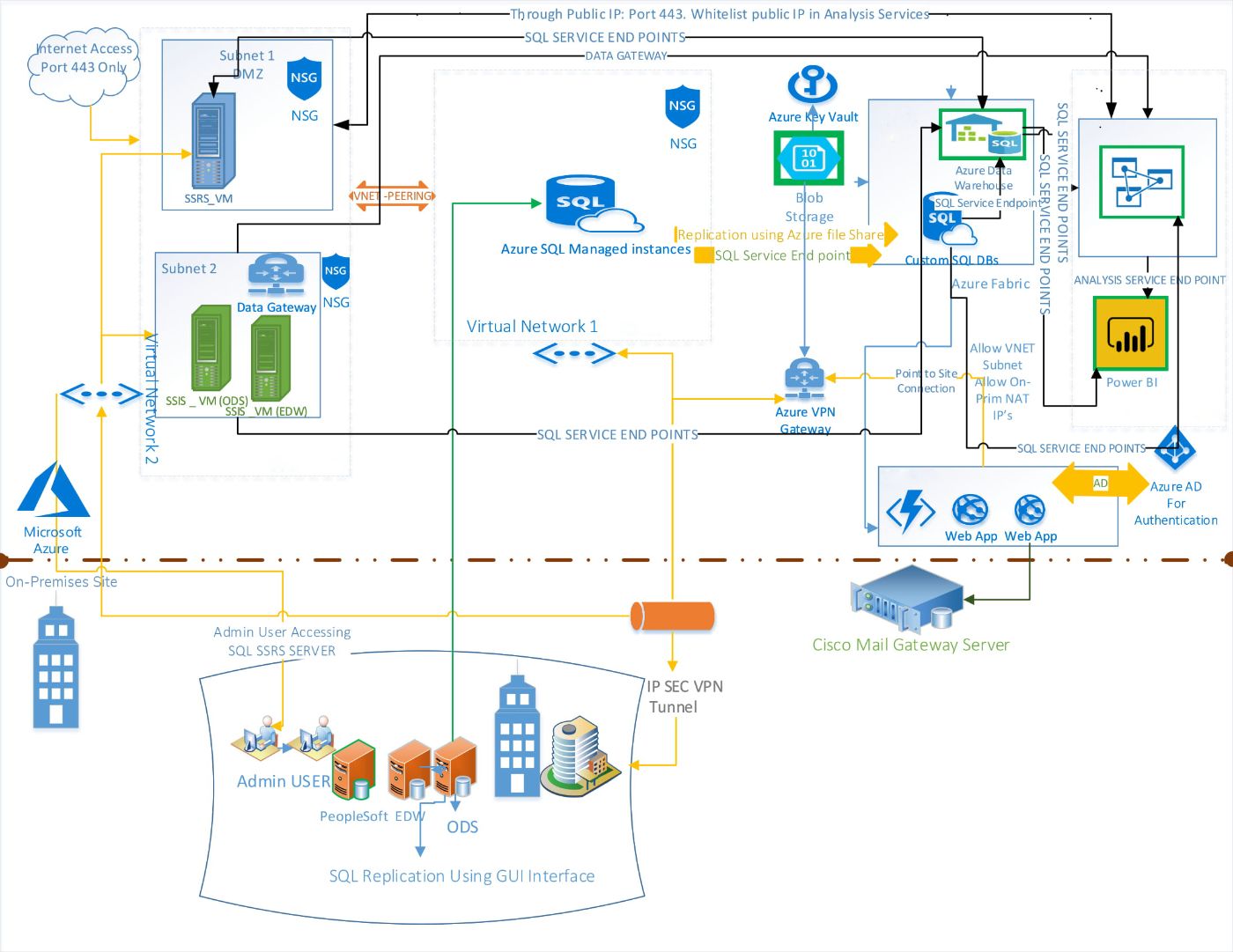 Scaling AI/ML Data Needs: Migrating On-Premise Data Engineering Workloads to Azure Cloud
Scaling AI/ML Data Needs: Migrating On-Premise Data Engineering Workloads to Azure Cloud
110. Inside the Bonkers DIY Project to Corral Every Gadget Rumor on Earth
 My attempt to noodle around.
My attempt to noodle around.
111. Hands-on with Apache Iceberg & Dremio on Your Laptop within 10 Minutes
 From creating and querying Iceberg tables to managing branches and snapshots with Nessie’s Git-like controls, you’ve seen how this stack can simplify complex da
From creating and querying Iceberg tables to managing branches and snapshots with Nessie’s Git-like controls, you’ve seen how this stack can simplify complex da
112. Why Microservices Suck At Machine Learning...and What You Can Do About It

113. Change Data Capture (CDC) When There is no CDC
 How to handle changing data when the source system doesn't help.
How to handle changing data when the source system doesn't help.
114. Data Engineering: What’s the Value of API Security in the Generative AI Era?
 Discover the importance of API security in the age of Generative AI. Learn how robust API protection ensures data integrity.
Discover the importance of API security in the age of Generative AI. Learn how robust API protection ensures data integrity.
115. Beyond Data: The Rising Need for AI Security
 As organizations increasingly deploy AI systems for decision-making, ensuring both data and AI pipeline security becomes critical to safeguard integrity, trust.
As organizations increasingly deploy AI systems for decision-making, ensuring both data and AI pipeline security becomes critical to safeguard integrity, trust.
116. Kafka Schema Evolution: A Guide to the Confluent Schema Registry
 Learn Kafka Schema Evolution: Understand, Manage & Scale Data Streams with Confluent Schema Registry. Essential for Data Engineers & Architects.
Learn Kafka Schema Evolution: Understand, Manage & Scale Data Streams with Confluent Schema Registry. Essential for Data Engineers & Architects.
117. The Role of Ontologies in Data Management
 Ontologies organize data, enhance interoperability, and drive insights across domains with structured frameworks.
Ontologies organize data, enhance interoperability, and drive insights across domains with structured frameworks.
118. How Datadog Revealed Hidden AWS Performance Problems
 Migrating from Convox to Nomad and some AWS performance issues we encountered along the way thanks to Datadog
Migrating from Convox to Nomad and some AWS performance issues we encountered along the way thanks to Datadog
119. I Built a RAG System for Our Analytics Team. It Worked Great Until We Added Real Data.
 Everyone's demo uses 50 documents and a clean knowledge base. We had 14,000 files and a decade of conflicting policies.
Everyone's demo uses 50 documents and a clean knowledge base. We had 14,000 files and a decade of conflicting policies.
120. I Gave 5 Teams the Same Dashboard - Only 1 Made a Decision With It
 Build for the decision, not the data. If you can't name the specific decision a dashboard is supposed to support, you're building a museum exhibit
Build for the decision, not the data. If you can't name the specific decision a dashboard is supposed to support, you're building a museum exhibit
121. Redefining Data Operations With Data Flow Programming in CocoIndex
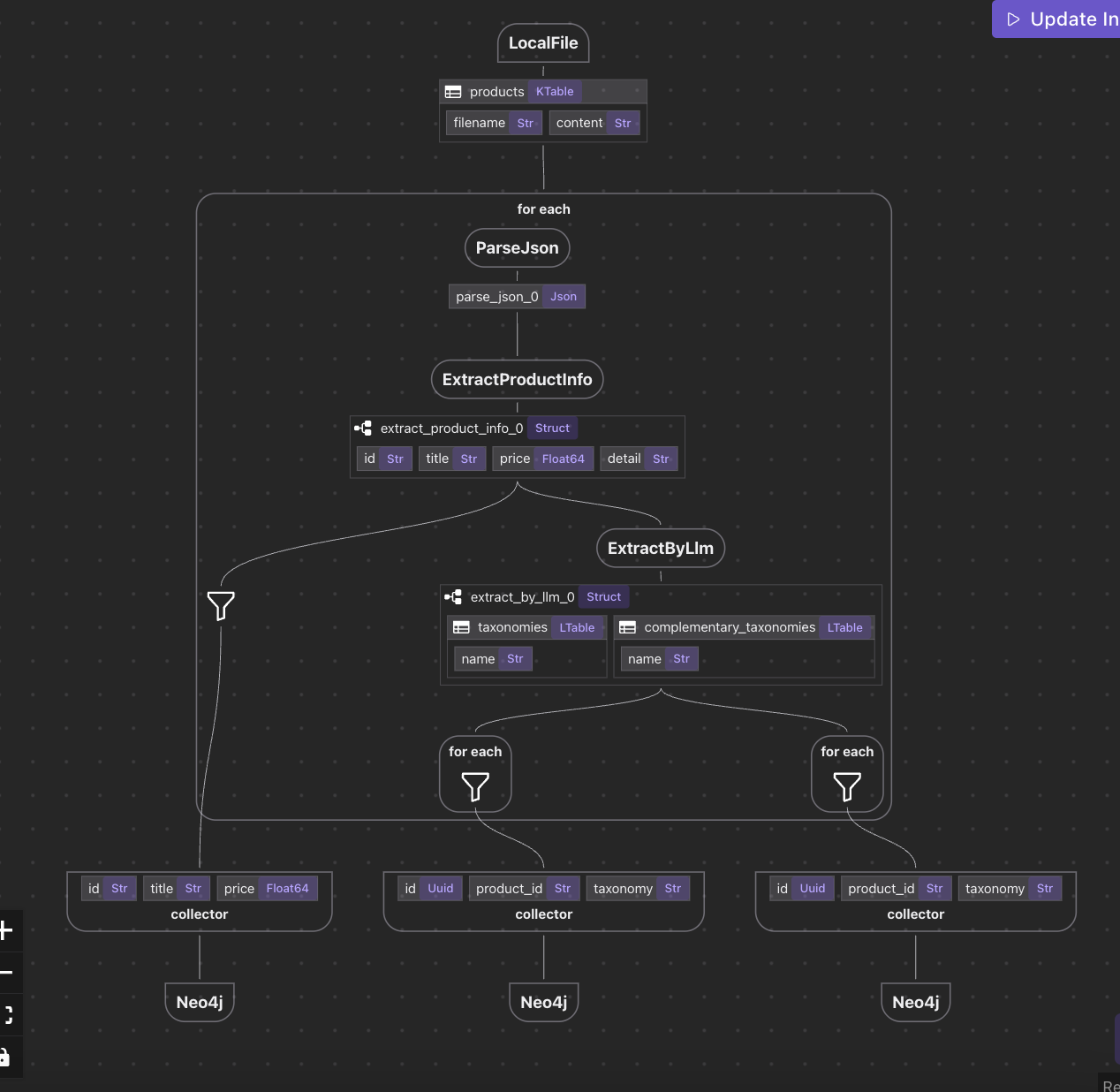 Discover how CocoIndex transforms data orchestration with a pure Data Flow Programming model — ensuring traceable, immutable, and declarative pipelines for know
Discover how CocoIndex transforms data orchestration with a pure Data Flow Programming model — ensuring traceable, immutable, and declarative pipelines for know
122. I Asked 5 LLMs to Write the Same SQL Query. Here's How Wrong They Got It
 I tested 5 LLMs on 10 real SQL queries and graded them against actual data. Here's the scoreboard and the failure mode that should worry you most.
I tested 5 LLMs on 10 real SQL queries and graded them against actual data. Here's the scoreboard and the failure mode that should worry you most.
123. The DeltaLog: Fundamentals of Delta Lake [Part 2]
 Multi-part series that will take you from beginner to expert in Delta Lake
Multi-part series that will take you from beginner to expert in Delta Lake
124. Optimizing Airflow: A Case Study in Cloud Resource Efficiency
 Learn cost-effective Apache Airflow optimization for intermittent tasks. Explore Google Cloud automation, reducing idle time, and minimizing costs
Learn cost-effective Apache Airflow optimization for intermittent tasks. Explore Google Cloud automation, reducing idle time, and minimizing costs
125. What's the Deal With Data Engineers Anyway?
 Learn the basics of data engineering with a practical ETL pipeline project. Explore how weather, flight, city data are extracted, transformed, loaded into a DB.
Learn the basics of data engineering with a practical ETL pipeline project. Explore how weather, flight, city data are extracted, transformed, loaded into a DB.
126. This New Data Type Is 8 Times Faster Than JSON: Improve Your Semi-Structured Data Analysis
 Apache Doris provides a new data type: Variant, for semi-structured data analysis, which enables 8 times faster query performance than JSON with 1/3 storage.
Apache Doris provides a new data type: Variant, for semi-structured data analysis, which enables 8 times faster query performance than JSON with 1/3 storage.
127. Build Your Own Semantic Search Engine in Under 50 Lines—No Joke
 Super performant Rust data stack to prepare realtime data for AI at massive scale - CocoIndex & Qdrant
Super performant Rust data stack to prepare realtime data for AI at massive scale - CocoIndex & Qdrant
128. This Real-Time Graph Framework Now Lets You Switch from Neo4j to Kuzu in One Line
 CocoIndex now supports Kuzu as a native graph database target, enabling real-time LLM-powered knowledge graphs with plug-and-play configuration.
CocoIndex now supports Kuzu as a native graph database target, enabling real-time LLM-powered knowledge graphs with plug-and-play configuration.
129. AWS Regions and Availability Zones: A Useful Guide for Beginners
 High Availability in the cloud: why us-east-1 alone is not a strategy (it's a gamble)
High Availability in the cloud: why us-east-1 alone is not a strategy (it's a gamble)
130. 16 Guides to Get You Started with Apache Iceberg
 These guides are designed to provide you with practical experience in working with Apache Iceberg.
These guides are designed to provide you with practical experience in working with Apache Iceberg.
131. 5 Skills Every Successful ML Engineer Should Have
 Uncover the five essential skills every successful machine learning engineer should have. Boost your ML engineering career with these invaluable insights.
Uncover the five essential skills every successful machine learning engineer should have. Boost your ML engineering career with these invaluable insights.
132. A 5-min Intro to Redpanda
 A 5-minute introduction to Redpanda. An API-compatible, simple, high-performance, and cost-effective drop-in replacement for Apache Kafka.
A 5-minute introduction to Redpanda. An API-compatible, simple, high-performance, and cost-effective drop-in replacement for Apache Kafka.
133. Data Observability that Fits Any Data Team’s Structure
 Data teams come in all different shapes and sizes. How do you build data observability into your pipeline in a way that suits your team structure? Read on.
Data teams come in all different shapes and sizes. How do you build data observability into your pipeline in a way that suits your team structure? Read on.
134. Data Observability: The First Step Towards Being Data-Driven
 In a nutshell, data reliability is a BIG challenge and there is a need for a solution that is easy to use, understand, and deploy, and also not hea
In a nutshell, data reliability is a BIG challenge and there is a need for a solution that is easy to use, understand, and deploy, and also not hea
135. Rust DataFrame Alternatives to Polars: Meet Elusion v4.0.0
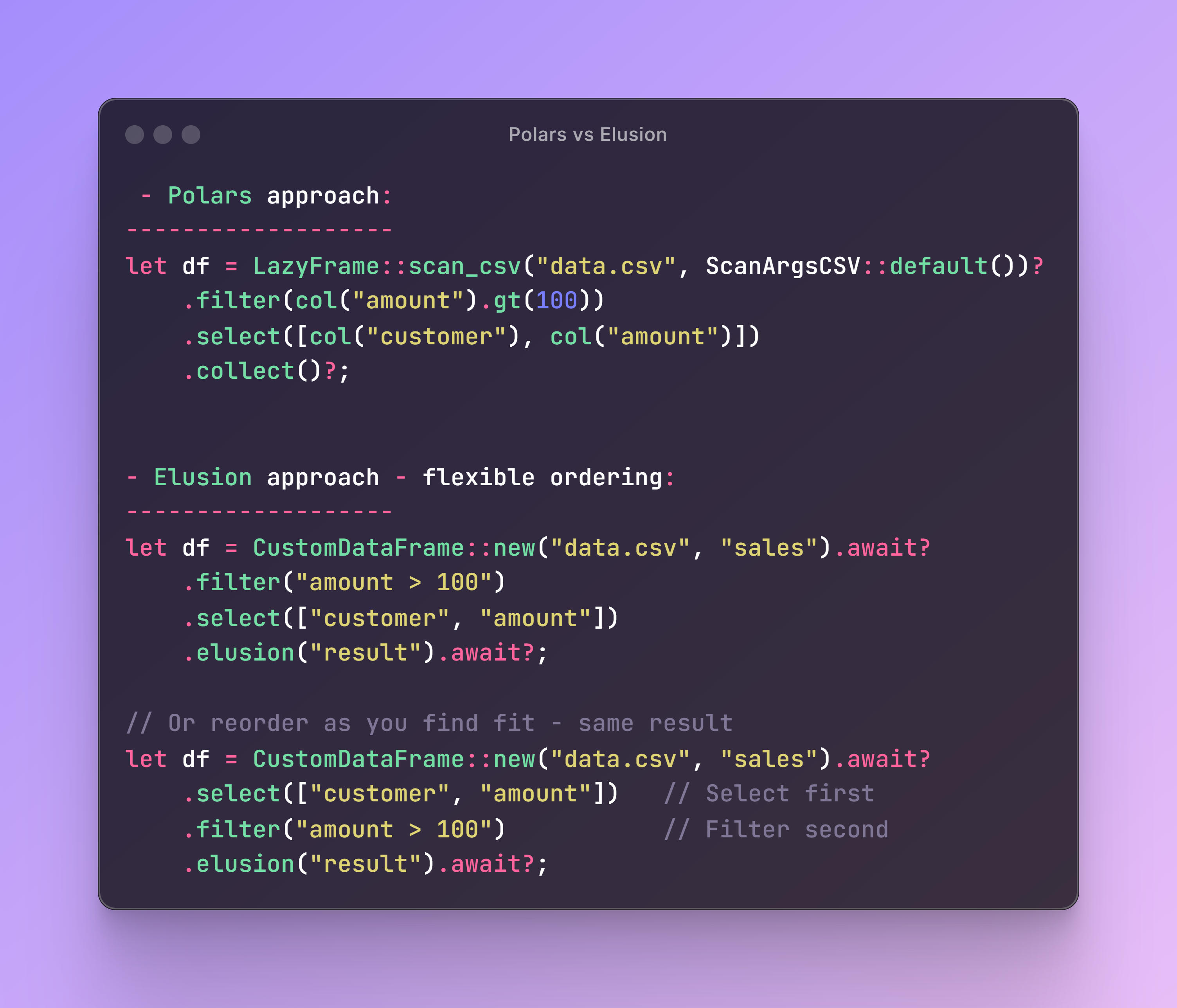 Elusion is a new contender that takes a fundamentally different approach to data engineering and analysis.
Elusion is a new contender that takes a fundamentally different approach to data engineering and analysis.
136. Streaming Wars: Why Apache Flink Could Outshine Spark
 Comparing Apache Flink & Apache Spark in stream data processing. Exploring architectural nuances, applications, and key distinctions between the platforms.
Comparing Apache Flink & Apache Spark in stream data processing. Exploring architectural nuances, applications, and key distinctions between the platforms.
137. How to Improve Query Speed to Make the Most out of Your Data
 In this article, I will talk about how I improved overall data processing efficiency by optimizing the choice and usage of data warehouses.
In this article, I will talk about how I improved overall data processing efficiency by optimizing the choice and usage of data warehouses.
138. Idempotency: The Secret to Production-Grade Data Pipelines
 Stop duplicate records. Learn to build idempotent data pipelines in Databricks and Snowflake using partitioning, hashing, and atomic transactions.
Stop duplicate records. Learn to build idempotent data pipelines in Databricks and Snowflake using partitioning, hashing, and atomic transactions.
139. Shift-Left Data Platforms in Early-Stage Startups: Strategies for Data-Driven Success
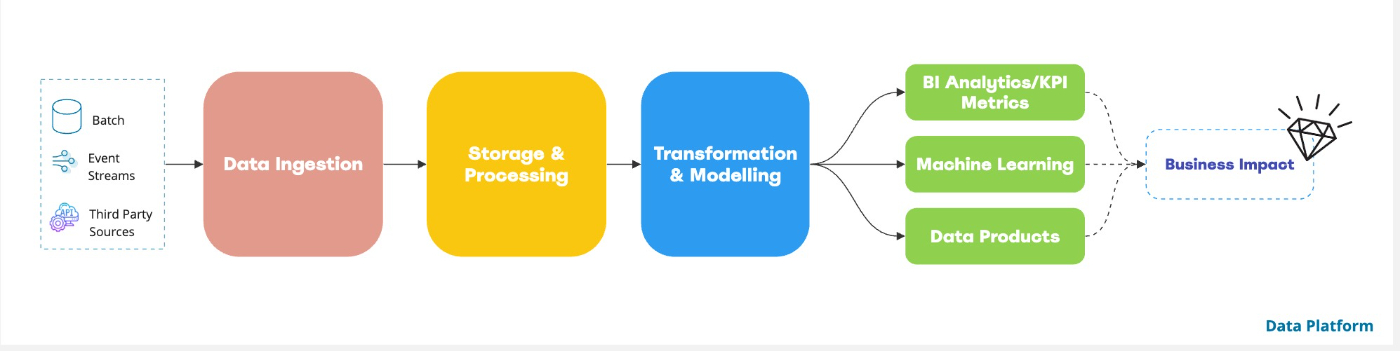 Left-Shift Data Platform: How to overcome early stage startup challenges to be Data-Driven
Left-Shift Data Platform: How to overcome early stage startup challenges to be Data-Driven
140. Why Data Quality is Key to Successful ML Ops
 In this first post in our 2-part ML Ops series, we are going to look at ML Ops and highlight how and why data quality is key to ML Ops workflows.
In this first post in our 2-part ML Ops series, we are going to look at ML Ops and highlight how and why data quality is key to ML Ops workflows.
141. Web3 Data Engineering Crash Course
 How advances in cryptography and decentralization are reshaping conventional data architectures.
How advances in cryptography and decentralization are reshaping conventional data architectures.
142. Efficient Model Training in the Cloud with Kubernetes, TensorFlow, and Alluxio Open Source
 This article presents the collaboration of Alibaba, Alluxio, and Nanjing University in tackling the problem of Deep Learning model training in the cloud. Various performance bottlenecks are analyzed with detailed optimizations of each component in the architecture. This content was previously published on Alluxio's Engineering Blog, featuring Alibaba Cloud Container Service Team's case study (White Paper here). Our goal was to reduce the cost and complexity of data access for Deep Learning training in a hybrid environment, which resulted in over 40% reduction in training time and cost.
This article presents the collaboration of Alibaba, Alluxio, and Nanjing University in tackling the problem of Deep Learning model training in the cloud. Various performance bottlenecks are analyzed with detailed optimizations of each component in the architecture. This content was previously published on Alluxio's Engineering Blog, featuring Alibaba Cloud Container Service Team's case study (White Paper here). Our goal was to reduce the cost and complexity of data access for Deep Learning training in a hybrid environment, which resulted in over 40% reduction in training time and cost.
143. The AI Agent Reality Check: What Actually Works in Production (And What Doesn't)
 Your model works in Jupyter but fails at 3 AM. Why data quality and observability are the silent killers of 85% of AI projects.
Your model works in Jupyter but fails at 3 AM. Why data quality and observability are the silent killers of 85% of AI projects.
144. Event-Driven Change Data Capture: Introduction, Use Cases, and Tools
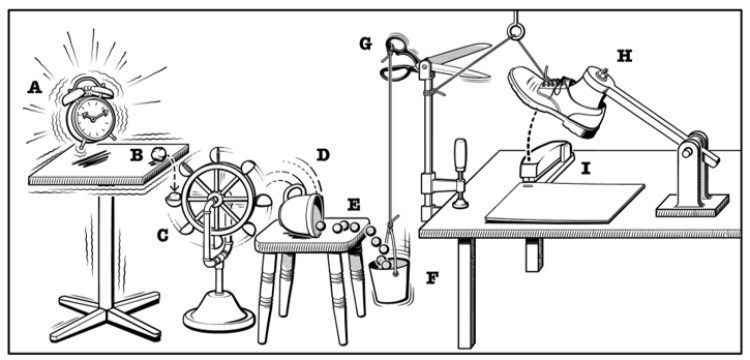 How to detect, capture, and propagate changes in source databases to target systems in a real-time, event-driven manner with Change Data Capture (CDC).
How to detect, capture, and propagate changes in source databases to target systems in a real-time, event-driven manner with Change Data Capture (CDC).
145. Compression in Big Data: Types and Techniques
 This article will discuss compression in the Big Data context, covering the types and methods of compression
This article will discuss compression in the Big Data context, covering the types and methods of compression
146. Navigating Apache Iceberg: A Deep Dive into Catalogs & Their Role in Data Lakehouse Architectures
 Dive into Apache Iceberg catalogs for organizing data lakes like a pro, tackling challenges, and picking the right fit!
Dive into Apache Iceberg catalogs for organizing data lakes like a pro, tackling challenges, and picking the right fit!
147. The Black Friday Query That Invented Data Engineering
 Learn how one badly‑timed analytics query can crash your production database, cost millions on Black Friday, and why data engineering exists to prevent it.
Learn how one badly‑timed analytics query can crash your production database, cost millions on Black Friday, and why data engineering exists to prevent it.
148. I Interviewed 6 People Who Use Our Data Platform. They All Described a Different System.
 We built one data platform. Six users described six completely different systems. Here's what that gap costs, and why documentation won't fix it.
We built one data platform. Six users described six completely different systems. Here's what that gap costs, and why documentation won't fix it.
149. How to Connect to Oracle, MySql and PostgreSQL Databases Using Python
 To connect to a database and query data, you need to begin by installing Pandas and Sqlalchemy.
To connect to a database and query data, you need to begin by installing Pandas and Sqlalchemy.
150. The Ultimate Directory of Apache Iceberg Resources
 This article is a comprehensive directory of Apache Iceberg resources, including educational materials, tutorials, and hands-on exercises.
This article is a comprehensive directory of Apache Iceberg resources, including educational materials, tutorials, and hands-on exercises.
151. Strategy for Incorporating Data Engineering for Computer Vision in Autonomous Driving
 Learn how data engineering supports autonomous driving perception through annotation workflows, dataset augmentation, synthetic data generation, and versioning.
Learn how data engineering supports autonomous driving perception through annotation workflows, dataset augmentation, synthetic data generation, and versioning.
[152. Towards Open Options Chains:
A Data Pipeline Solution - Part I](https://hackernoon.com/towards-open-options-chains-a-data-pipeline-solution-for-options-data-part-i)
 In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.
In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.
153. HarperDB is More Than Just a Database: Here's Why
 HarperDB is more than just a database, and for certain users or projects, HarperDB is not serving as a database at all. How can this be possible?
HarperDB is more than just a database, and for certain users or projects, HarperDB is not serving as a database at all. How can this be possible?
154. AI Just Took Over Ad Targeting—And It’s Smarter, Faster, and Less Creepy Than Ever
 Next-gen AI ad platforms use vector databases, indexing, and privacy-aware AI for real-time optimization, boosting ad spend efficiency while staying compliant.
Next-gen AI ad platforms use vector databases, indexing, and privacy-aware AI for real-time optimization, boosting ad spend efficiency while staying compliant.
155. Modern Data Engineering with Apache Spark: A Hands-On Guide to Slowly Changing Dimensions (SCD)
 Learn how Apache Spark and Databricks implement Slowly Changing Dimensions (Types 0–6) to preserve history, scale analytics, and ensure accurate data modeling.
Learn how Apache Spark and Databricks implement Slowly Changing Dimensions (Types 0–6) to preserve history, scale analytics, and ensure accurate data modeling.
156. Bigger Models Won’t Fix Terminal Agents

<h2>The gap between talking and doing</h2> <p>Large language models excel at discussing programming concepts, explaining terminal commands, and reasoning about file systems. Yet when asked to actually accomplish a task in a terminal, they fail spectacularly. They suggest nonsensical commands, misinterpret output, and give up at the first error. This gap between linguistic capability and practical competence has persisted despite rapid advances in model scale and architecture.</p> <p>The industry's response has been predictable: build bigger models. Deploy models with more parameters, more training tokens, more compute. Yet recent work shows that even substantial models like Qwen3-32B achieve only 3.4% on Terminal-Bench 2.0, a standard benchmark for terminal task completion. This suggests the bottleneck isn't model capacity. It's something more fundamental: the training data itself.</p> <p>A new paper approaches terminal agent capabilities through a different lens. Rather than chasing model scale or architectural innovations, the authors conducted a systematic study of data engineering practices for terminal agents. The conclusion challenges conventional wisdom: a carefully constructed dataset combined with strategic filtering and curriculum learning can teach an 8B parameter model to match the performance of models four to ten times larger trained on standard data.</p> <h2>The unsexy truth about capability</h2> <p>The conventional story about AI progress emphasizes algorithmic breakthroughs and computational scale. What actually happens in practice is less glamorous. For embodied tasks, where models need to execute sequences of actions rather than simply generate text, <strong>what you train on matters far more than how much compute you throw at the problem</strong>.</p> <p>This paper introduces three key contributions that make this shift possible. First, Terminal-Task-Gen, a lightweight synthetic task generation pipeline that supports both seed-based and skill-based task construction. Second, a comprehensive analysis of filtering strategies, curriculum learning approaches, and scaling behavior. Third, Terminal-Corpus, a large-scale open-source dataset of terminal interactions that demonstrates these principles work in practice.</p> <p>The results vindicate this approach. Nemotron-Terminal models, trained on Terminal-Corpus and initialized from Qwen base models, achieve substantial performance jumps: the 8B version improves from 2.5% to 13.0%, the 14B version from 4.0% to 20.2%, and the 32B version from 3.4% to 27.4%. These aren't incremental improvements. They represent fundamental shifts in efficiency.</p> <h2>Where does high-quality training data come from</h2> <p>Manually creating thousands of high-quality terminal interactions would be prohibitively expensive. A human expert writing terminal task trajectories might produce a few per day. Building a dataset with enough diversity to teach genuine capability would require months of expert time and substantial cost. So the paper takes a different approach: systematize the process of generating diverse, realistic terminal tasks.</p> <p>Terminal-Task-Gen operates in two phases. The first phase, Dataset Adaptation, takes existing benchmarks and task descriptions from sources like Terminal-Bench, then reformulates them as interactive terminal interactions. This provides a foundation but is limited in coverage. Few benchmarks exist for terminal tasks, and even those that do capture only a fraction of possible terminal operations.</p> <p>The second phase, Synthetic Task Generation, is where the real leverage appears. The pipeline defines a Skill Taxonomy, a structured breakdown of terminal operations and concepts. These skills range from basic navigation (moving between directories, listing files) to more complex operations (understanding command output, iterating based on errors, chaining operations together). By combining skills from this taxonomy in different ways, the system generates novel terminal tasks that teach these skills systematically.</p> <p><a href="https://arxiv.org/html/2602.21193/figs/data_pipeline.png"><img src="https://arxiv.org/html/2602.21193/figs/data_pipeline.png" alt="Overview of Terminal-Task-Gen combining Dataset Adaptation and Synthetic Task Generation. The pipeline takes benchmark data and a skill taxonomy, producing diverse terminal interaction trajectories." /></a><br/><em>Overview of Terminal-Task-Gen combining Dataset Adaptation and Synthetic Task Generation. The pipeline takes benchmark data and a skill taxonomy, producing diverse terminal interaction trajectories.</em></p> <p>The output is Terminal-Corpus, a dataset containing thousands of terminal interaction sequences. Unlike static benchmarks, these trajectories capture the dynamic nature of terminal interaction: the user issues a command, observes output, interprets that output, and adjusts their approach accordingly. This mimics how humans actually use terminals, which is critical because models trained on static problem-solution pairs often fail to handle unexpected outputs or errors.</p> <h2>Curating signal from noise</h2> <p>Not all synthetic data improves model performance. Some generated tasks might be trivially easy, offering no learning signal. Others might be internally inconsistent, teaching the model to hallucinate plausible-sounding but incorrect commands. Still others might be so convoluted that they confuse rather than clarify patterns.</p> <p>The paper systematically studies filtering strategies to distinguish high-signal examples from low-signal ones. The analysis reveals which filtering criteria actually correlate with downstream performance on Terminal-Bench 2.0. This matters because naive scaling, where you simply generate enormous amounts of data and train on all of it, typically underperforms careful curation.</p> <p>Some trajectories might be rejected because they contain errors in their reasoning or incorrect command sequences. Others might be excluded because they're too similar to existing examples, offering little diversity. The filtering process is not arbitrary; it's grounded in empirical analysis of what data actually improves model performance.</p> <p>This represents a fundamental insight about data engineering: curation is as important as generation. A smaller dataset of high-quality examples outperforms a larger dataset with noise. The specific filtering strategies used here would be context-dependent, but the principle is universal.</p> <h2>Structuring the learning process</h2> <p>Once you have filtered, high-quality data, the question of how to present it during training becomes crucial. Not all orderings are equally effective.</p> <p>Curriculum learning applies a simple principle: harder material is easier to learn when preceded by foundational material. A model learning terminal tasks benefits from first encountering simple interactions, then gradually progressing to more complex ones. This scaffolding makes learning more efficient than random sampling.</p> <p>For terminal tasks, natural curriculum structures emerge. Basic navigation (changing directories, listing files) can serve as a foundation. File operations (copying, moving, deleting) build on that foundation. Multi-step reasoning tasks that require chaining commands together come later. Understanding command output and error recovery grow more sophisticated across the curriculum.</p> <p>The paper studies how these curriculum principles apply to terminal agent training. Strategic ordering of examples during training improves both convergence speed and final performance compared to random shuffling. This is particularly important because terminal tasks have inherent sequential dependencies. You can't reasonably ask a model to debug a complex pipeline if it hasn't yet learned basic piping syntax.</p> <h2>Understanding scaling behavior</h2> <p>Data engineers face a practical reality: training compute is limited. Generating more data costs compute to train on. At some point, marginal improvements from additional data diminish, and that compute would be better spent elsewhere.</p> <p>The paper includes scaling experiments that reveal how performance improves as training data volume increases. These curves answer a crucial question: have we hit a plateau, or would additional data continue helping?</p> <p><a href="https://arxiv.org/html/2602.21193/figs/scaling_results.png"><img src="https://arxiv.org/html/2602.21193/figs/scaling_results.png" alt="Impact of training data scale on model performance. Terminal-Bench 2.0 performance increases consistently with training data volume for both Qwen3-8B and Qwen3-14B." /></a><br/><em>Impact of training data scale on model performance. Terminal-Bench 2.0 performance increases consistently with training data volume for both Qwen3-8B and Qwen3-14B.</em></p> <p>The results show clear improvement patterns for both model sizes. Performance grows consistently with more data, though the growth rate eventually slows. The curves suggest that the models tested haven't yet hit a hard ceiling, but marginal returns are diminishing.</p> <p>Understanding the composition of these trajectories helps explain the scaling behavior. The token distribution shows what length trajectories look like, while the turn distribution reveals how many interaction steps typical tasks involve.</p> <p><a href="https://arxiv.org/html/2602.21193/figs/token_stats.png"><img src="https://arxiv.org/html/2602.21193/figs/token_stats.png" alt="Distribution of tokens in generated trajectories. This shows the length characteristics of synthetic terminal tasks. Distribution of turns in generated trajectories. This reveals how many interaction steps are typical." /></a><br/><em>Distribution of tokens in generated trajectories. This shows the length characteristics of synthetic terminal tasks.</em></a></li> <li><a href="https://arxiv.org/html/2602.21193/figs/turn_stats.png"><em>Distribution of turns in generated trajectories. This reveals how many interaction steps are typical.</em></p> <p>These statistics matter because they determine training requirements. If typical trajectories require thousands of tokens, then a dataset of several million trajectories becomes gigabytes of data. Understanding these distributions helps practitioners plan data generation, training infrastructure, and budget allocation.</p> <h2>The proof of concept</h2> <p>All of this methodology yields concrete results. An 8B model trained on Terminal-Corpus reaches 13.0% accuracy on Terminal-Bench 2.0, jumping from a baseline of 2.5%. The 14B model reaches 20.2% (from 4.0%), and the 32B model reaches 27.4% (from 3.4%). Scaling the baseline models without better data produces marginal improvements. Scaling the data engineering produces orders of magnitude improvement.</p> <p>Most strikingly, the 8B model trained on Terminal-Corpus now matches or exceeds the performance of much larger models trained on standard data. This comparison shifts the entire conversation around terminal agents. You don't need a 70B parameter model to build a capable agent. You need thoughtful data engineering.</p> <h2>Data engineering as a fundamental lever</h2> <p>This work reveals something important about AI capabilities that the industry often overlooks. Sometimes the bottleneck isn't compute, it isn't model architecture, and it isn't algorithmic innovation. It's training data engineering.</p> <p>For tasks where models need to execute, perceive feedback, and adapt, the quality and structure of training data becomes paramount. A model trained on synthetic trajectories that systematically cover the skill space, filtered for signal, and presented in a curriculum that respects task dependencies outperforms larger models trained haphazardly.</p> <p>This has practical implications. Unlike model architecture research or compute scaling, data engineering is accessible. It doesn't require the largest clusters or the most specialized hardware. It requires systematic thinking about what signals teach capability, how to generate diverse examples, what examples to exclude, and how to present examples during training.</p> <p>The open-sourcing of Nemotron-Terminal models and Terminal-Corpus accelerates this direction. Future work can build on this foundation, improving the pipeline further. The bottleneck moves from "how do we build capable terminal agents" to "how do we engineer training data even more effectively."</p> <p>The broader lesson applies beyond terminal agents. Any task where models must execute actions, perceive outcomes, and adjust strategy benefits from this kind of data engineering thinking. As AI systems move from pure language understanding toward embodied AI, systematic approaches to training data quality become not an optimization, but a fundamental requirement.</p>
<hr/><p><strong>Original post:</strong> <a href="https://www.aimodels.fyi/papers/arxiv/data-engineering-scaling-llm-terminal-capabilities?utm_source=hackernoon&utm_medium=referral">Read on AIModels.fyi</a></p>
157. I Built the Same Data Pipeline 4 Ways. Here's What I'd Never Do Again.
 I built one pipeline four times. The winner wasn’t the fastest tool; it was the one that failed loudly, stayed debuggable, and didn’t punish ops.
I built one pipeline four times. The winner wasn’t the fastest tool; it was the one that failed loudly, stayed debuggable, and didn’t punish ops.
158. Intro to Data Vault Modeling: Agility, Scalability, and Practical Applications Explained
 The practical use of Data Vault models, as illustrated through querying customer orders and analyzing product sales, demonstrates the methodology's flexibility,
The practical use of Data Vault models, as illustrated through querying customer orders and analyzing product sales, demonstrates the methodology's flexibility,
159. The Importance of Data in Machine Learning: Fueling the AI Revolution
 In this blog, we’ll delve into the crucial role that data plays in machine learning and why it’s often said that in the world of AI, “data is king.”
In this blog, we’ll delve into the crucial role that data plays in machine learning and why it’s often said that in the world of AI, “data is king.”
160. The Observability Debt Hypothesis: Why Perfect Dashboards Still Mask Failing Systems
 Perfect dashboards don’t mean perfect systems. Explore how observability debt hides behind metrics, distorts truth, and weakens engineering judgment in 2025.
Perfect dashboards don’t mean perfect systems. Explore how observability debt hides behind metrics, distorts truth, and weakens engineering judgment in 2025.
161. What is Data Profiling? Concepts and Examples
 Learn the concepts of data profiling and how it can speed up the debugging the quality related incidents across the data stack.
Learn the concepts of data profiling and how it can speed up the debugging the quality related incidents across the data stack.
162. The Ghost in the Warehouse: How to Solve Schema Drift in Analytical AI Agents
 Solve schema drift in analytical AI agents using sqldrift. Real-world validation on 255 BIRD queries achieves 94.1% success with automated LLM correction.
Solve schema drift in analytical AI agents using sqldrift. Real-world validation on 255 BIRD queries achieves 94.1% success with automated LLM correction.
163. 5 Ways to Become a Leader That Data Engineers Will Love
 How to become a better data leader that the data engineers love?
How to become a better data leader that the data engineers love?
164. Modernization Is Not Migration: Here's Why
 How operational engineering—not infrastructure—determines whether cloud modernization delivers reliability in regulated financial data platforms.
How operational engineering—not infrastructure—determines whether cloud modernization delivers reliability in regulated financial data platforms.
165. Understanding Data Lineage: Key Strategies for Ensuring Data Quality and Compliance
 Data lineage refers to the process of tracking data from its origin to its destination, including all transformations and movements in between. It is crucial fo
Data lineage refers to the process of tracking data from its origin to its destination, including all transformations and movements in between. It is crucial fo
166. A Brief Introduction to 5 Predictive Models in Data Science
 Predictive Modeling in Data Science is more like the answer to the question “What is going to happen in the future, based on known past behaviors?”
Predictive Modeling in Data Science is more like the answer to the question “What is going to happen in the future, based on known past behaviors?”
167. Efficient Enterprise Data Solutions With Stream Processing
 Enterprise data solutions—handling myriad data sources and massive data volume—are expensive. Stream processing reduces costs and brings real-time scalability.
Enterprise data solutions—handling myriad data sources and massive data volume—are expensive. Stream processing reduces costs and brings real-time scalability.
168. Are NoSQL databases relevant for data engineering?
 In this article, we’ll investigate use cases for which data engineers may need to interact with NoSQL database, as well as the pros and cons.
In this article, we’ll investigate use cases for which data engineers may need to interact with NoSQL database, as well as the pros and cons.
169. The Silent Killer of Data Lakes: Solving the Small File Problem
 Stop the "Small File Syndrome" in your Data Lake. Learn how to implement Compaction, Z-Ordering, and automated maintenance in Databricks and Snowflake.
Stop the "Small File Syndrome" in your Data Lake. Learn how to implement Compaction, Z-Ordering, and automated maintenance in Databricks and Snowflake.
170. Architecting for Speed: Advanced SQL Performance Tuning in the Lakehouse
 Stop slow queries and high cloud costs. Learn advanced SQL tuning for Snowflake and Databricks, including Pruning, Join Salting, and Search Optimization.
Stop slow queries and high cloud costs. Learn advanced SQL tuning for Snowflake and Databricks, including Pruning, Join Salting, and Search Optimization.
171. PBIX Is Not Going Away - But PowerBI Will Never Work the Same Again
 PowerBI is shifting from "PBIX" to "PBIR". This article explains what actually changes, who benefits and how teams should prepare for the future without panic.
PowerBI is shifting from "PBIX" to "PBIR". This article explains what actually changes, who benefits and how teams should prepare for the future without panic.
172. Unlocking the Power of Advanced Data Types in Big Data
 Features of the specialized data types near integers and strings, which we use in every-day life, will allow us to store and operate complex data structures.
Features of the specialized data types near integers and strings, which we use in every-day life, will allow us to store and operate complex data structures.
173. Data Transformation and Discretization: A Comprehensive Guide
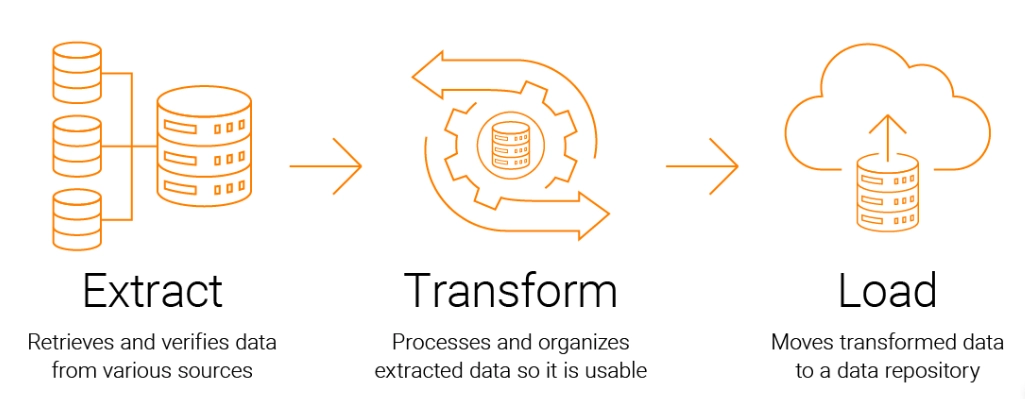 Learn about data transformation and discretization in data preprocessing. Explore normalization techniques, binning, and histograms.
Learn about data transformation and discretization in data preprocessing. Explore normalization techniques, binning, and histograms.
174. If Data Is the New Oil, We Already Built a Planet-Sized Spill
 This isn’t about saving bits—it’s about shaping history into a governed, trustworthy, searchable corpus for humans and AI.
This isn’t about saving bits—it’s about shaping history into a governed, trustworthy, searchable corpus for humans and AI.
175. Synchronizing Data from MySQL to PostgreSQL Using Apache SeaTunnel
 A step-by-step walkthrough of building a real-time data pipeline to merge and synchronize MySQL data sources using Apache SeaTunnel.
A step-by-step walkthrough of building a real-time data pipeline to merge and synchronize MySQL data sources using Apache SeaTunnel.
176. What Is A Data Mesh — And Is It Right For Me?
 Ask anyone in the data industry what’s hot and chances are “data mesh” will rise to the top of the list. But what is a data mesh and is it right for you?
Ask anyone in the data industry what’s hot and chances are “data mesh” will rise to the top of the list. But what is a data mesh and is it right for you?
177. Data Pipeline Testing: The 3 Levels Most Teams Miss
 Dashboards don’t represent actual state, models degrade unnoticed, and incidents show up as “weird numbers” instead of errors.
Dashboards don’t represent actual state, models degrade unnoticed, and incidents show up as “weird numbers” instead of errors.
178. Apache Beam on GCP: How Distributed Data Pipelines Actually Work (for REST API Engineers)
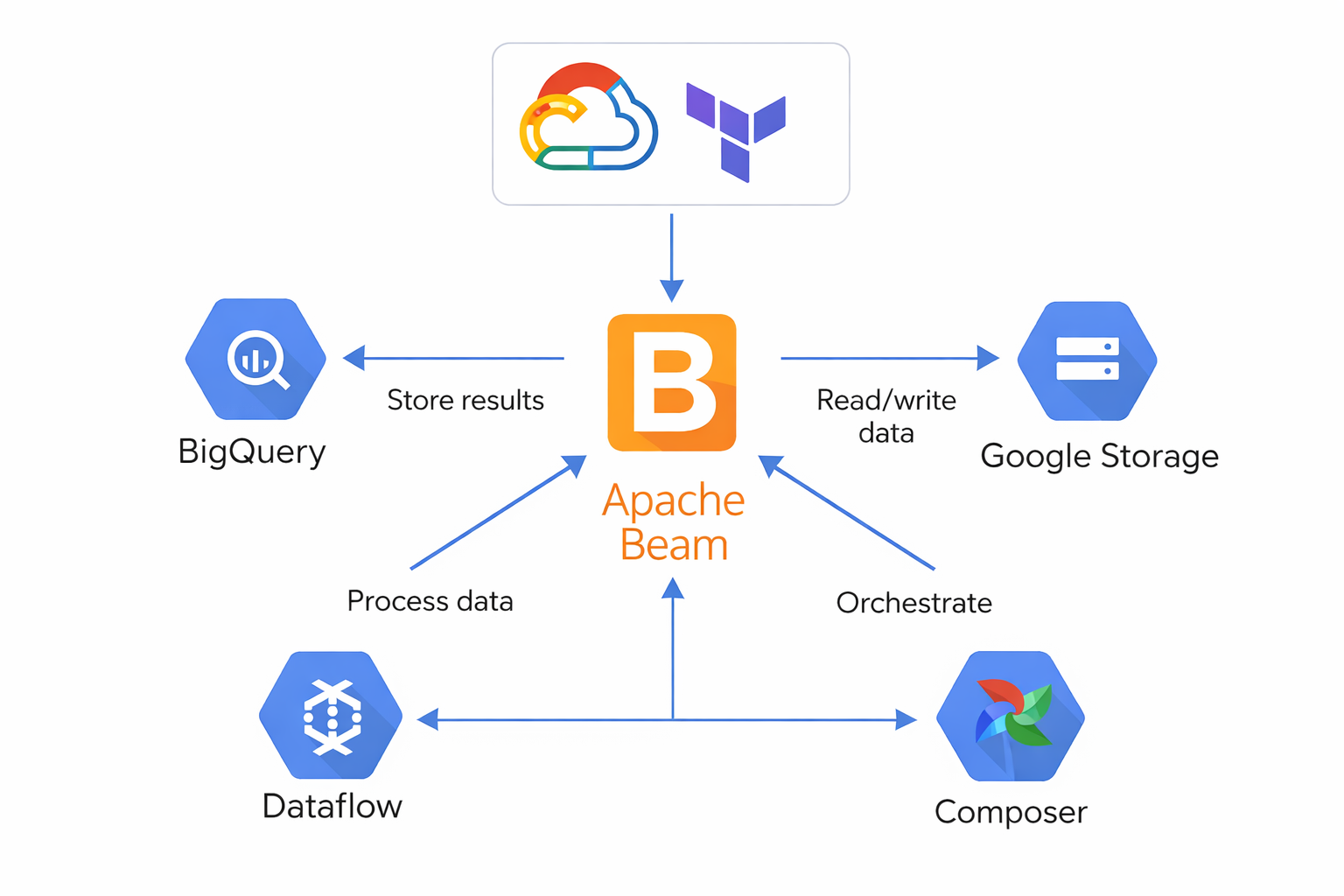 Apache Beam is a declarative programming model for large-scale data processing, not a service or framework like a REST API.
Apache Beam is a declarative programming model for large-scale data processing, not a service or framework like a REST API.
179. Database Tips: 7 Reasons Why Data Lakes Could Solve Your Problems
 Data lakes are an essential component in building any future-proof data platform. In this article, we round up 7 reasons why you need a data lake.
Data lakes are an essential component in building any future-proof data platform. In this article, we round up 7 reasons why you need a data lake.
180. From "Decentralized" to "Unified": SUPCON Uses SeaTunnel to Build an Efficient Data Collection Frame
 SUPCON dumped siloed data tools for Apache SeaTunnel—now core sync tasks run 0-failure!
SUPCON dumped siloed data tools for Apache SeaTunnel—now core sync tasks run 0-failure!
181. AI Is About to Break Your BI Architecture (If You Don't Redesign It First)
 AI is about to expose weak BI architecture. "DirectQuery" collapses under machine curiosity. Decision-aligned design is the only way forward.
AI is about to expose weak BI architecture. "DirectQuery" collapses under machine curiosity. Decision-aligned design is the only way forward.
182. Is Your Apache Ni-Fi Ready for Production?
 Apache NiFi cluster can process up to 50 GB of data per day. Apache NiFi can provide a balance between performance and cost-effectiveness.
Apache NiFi cluster can process up to 50 GB of data per day. Apache NiFi can provide a balance between performance and cost-effectiveness.
183. The Hidden Tax of Cloud BI: Zombie Data Movement Between Platforms
 Hidden cloud BI cost: data egress between platforms. Learn how “zombie data movement” quietly inflates analytics bills in modern BI architectures.
Hidden cloud BI cost: data egress between platforms. Learn how “zombie data movement” quietly inflates analytics bills in modern BI architectures.
184. Make Your Data Pipelines 5X Faster with Adaptive Batching
 Ultra charge AI native data pipelines with X times of performance boost by batching
Ultra charge AI native data pipelines with X times of performance boost by batching
185. The Data Security Duo: Data Encryption and Vulnerability Scans
 How application and product engineering teams can implement data encryption to effectively address data vulnerability issues.
How application and product engineering teams can implement data encryption to effectively address data vulnerability issues.
186. Lessons From The Night I Met Dbt on Databricks
 The Medallion Architecture is a framework that turns messy e-commerce data into business-ready insights.
The Medallion Architecture is a framework that turns messy e-commerce data into business-ready insights.
187. A Developer’s Guide to DolphinScheduler 3.1.9 Worker Startup Process
 Dive into the detailed features and architecture of Apache DolphinScheduler 3.1.9!
Dive into the detailed features and architecture of Apache DolphinScheduler 3.1.9!
188. Minimum Incident Lineage (MIL): A Run-Level Evidence Standard for Reproducible Data Incidents
 Traditional data lineage shows dependencies—not proof. Learn how Minimum Incident Lineage helps teams reproduce, audit, and resolve data incidents faster.
Traditional data lineage shows dependencies—not proof. Learn how Minimum Incident Lineage helps teams reproduce, audit, and resolve data incidents faster.
189. 96 Stories To Learn About Data Engineering
 Learn everything you need to know about Data Engineering via these 96 free HackerNoon stories.
Learn everything you need to know about Data Engineering via these 96 free HackerNoon stories.
190. Solving Noom's Data Analyst Interview Questions
 Noom helps you lose weight. We help you get a job at Noom. In today’s article, we’ll show you one of Noom’s hard SQL interview questions.
Noom helps you lose weight. We help you get a job at Noom. In today’s article, we’ll show you one of Noom’s hard SQL interview questions.
191. Generative AI : Hype, Hype, Hype, What's Next?
 The generative AI hype continues,are we aware of the potential risks we face daily as users? we should shift now from the hype to more trust in AI.
The generative AI hype continues,are we aware of the potential risks we face daily as users? we should shift now from the hype to more trust in AI.
192. A Hands-On Guide to Inverted Indexes: Accelerate Text Searches by 40
 This post is a deep dive into the inverted index and NGram BloomFilter index, providing a hands-on guide to applying them for various queries.
This post is a deep dive into the inverted index and NGram BloomFilter index, providing a hands-on guide to applying them for various queries.
193. Declarative Engineering: Using Terraform to Code Your Data Pipelines
 A small modern data stack that ETLs data from a PostgreSQL database into a ClickHouse database.
A small modern data stack that ETLs data from a PostgreSQL database into a ClickHouse database.
194. Conversational Analytics: the Next Generation of Data Analysis and Business Intelligence
 The article talks about how data analytics is evolving at workplaces from traditional querying , excel and dashboards to natural language conversations
The article talks about how data analytics is evolving at workplaces from traditional querying , excel and dashboards to natural language conversations
195. Apache Airflow: Is It a Good Tool for Data Quality Checks?
 Learn the impact of airflow on the data quality checks and why you should look for an alternative solution tool
Learn the impact of airflow on the data quality checks and why you should look for an alternative solution tool
196. Conversational Data Analytics with SQL Embeddings
 Dashboards show what happened. SQL embeddings remember how you figured it out—and let AI start there next time instead of guessing from scratch.
Dashboards show what happened. SQL embeddings remember how you figured it out—and let AI start there next time instead of guessing from scratch.
197. Deep Learning at Alibaba Cloud with Alluxio: How To Run PyTorch on HDFS
 This tutorial shows how Alibaba Cloud Container team runs PyTorch on HDFS using Alluxio under Kubernetes environment. The original Chinese article was published on Alibaba Cloud's engineering blog, then translated and published on Alluxio's Engineering Blog
This tutorial shows how Alibaba Cloud Container team runs PyTorch on HDFS using Alluxio under Kubernetes environment. The original Chinese article was published on Alibaba Cloud's engineering blog, then translated and published on Alluxio's Engineering Blog
198. Data Security Strategy Beyond Access Control: Data Encryption
 Data encryption can enhance your security strategy, simplify system architecture, and provide lasting protection against breaches.
Data encryption can enhance your security strategy, simplify system architecture, and provide lasting protection against breaches.
199. Proper Governance in the AI Age Starts With Data Contracts
 Data contracts define ownership, quality, SLAs, and context—preventing silent failures in pipelines, analytics, and AI systems.
Data contracts define ownership, quality, SLAs, and context—preventing silent failures in pipelines, analytics, and AI systems.
200. Database Management: Creating and Granting User Access in Oracle
 Learn how to efficiently manage user access in Oracle databases for seamless data sharing and collaboration among departments.
Learn how to efficiently manage user access in Oracle databases for seamless data sharing and collaboration among departments.
201. Financial Anti-Fraud Solutions Available on the Apache Doris Data Warehouse
 This post will get into details about how a retail bank builds their fraud risk management platform based on Apache Doris and how it performs.
This post will get into details about how a retail bank builds their fraud risk management platform based on Apache Doris and how it performs.
202. Hugging Face's FineVision: Messy Data is Better Than You Think

203. Python vs. Spark: When Does It Make Sense to Scale Up?
 Wondering when to switch from Python to Spark? This practical guide breaks down the real differences, warning signs, and best use cases—so you know exactly when
Wondering when to switch from Python to Spark? This practical guide breaks down the real differences, warning signs, and best use cases—so you know exactly when
204. Apache Arrow: Optimizing PySpark Applications
 Apache Arrow eliminates PySpark serialization bottlenecks. Learn how columnar, zero copy memory boosts Pandas, Spark, and UDF performance at scale.
Apache Arrow eliminates PySpark serialization bottlenecks. Learn how columnar, zero copy memory boosts Pandas, Spark, and UDF performance at scale.
205. Getting Started with Data Analytics in Python Using PyArrow
 In this guide, we will explore data analytics using PyArrow, a powerful library designed for efficient in-memory data processing with columnar storage.
In this guide, we will explore data analytics using PyArrow, a powerful library designed for efficient in-memory data processing with columnar storage.
206. Introduction to Delight: Spark UI and Spark History Server
 Delight is an open-source an cross-platform monitoring dashboard for Apache Spark with memory & CPU metrics complementing the Spark UI and Spark History Server.
Delight is an open-source an cross-platform monitoring dashboard for Apache Spark with memory & CPU metrics complementing the Spark UI and Spark History Server.
207. Understanding the Differences between Data Science and Data Engineering
 A brief description of the difference between Data Science and Data Engineering.
A brief description of the difference between Data Science and Data Engineering.
208. Control Processing Concurrency for Large Scale RAG Pipelines in Production
 CocoIndex's layered concurrency control help you optimize data processing performance, prevent system overload, and ensure stable, efficient pipelines at scale
CocoIndex's layered concurrency control help you optimize data processing performance, prevent system overload, and ensure stable, efficient pipelines at scale
209. A Deep Dive Into GitHub Actions From Software Development to Data Engineering
 GitHub Actions is widely recognized as a powerful tool for automating tasks in software development.
GitHub Actions is widely recognized as a powerful tool for automating tasks in software development.
210. 5 Ways Spark 4.1 Moves Data Engineering From Manual Pipelines to Intent-Driven Design
 Apache Spark 4.1 introduces significant architectural efficiencies designed to simplify Change Data Capture (CDC) and lifecycle management.
Apache Spark 4.1 introduces significant architectural efficiencies designed to simplify Change Data Capture (CDC) and lifecycle management.
211. For Entry-Level Data Engineers: How to Build a Simple but Solid Data Architecture
 This article aims to provide a reference for non-tech companies who are seeking to empower their business with data analytics.
This article aims to provide a reference for non-tech companies who are seeking to empower their business with data analytics.
212. From Pipelines to AI Platforms: How Agentic AI Is Redefining the Role of Data Engineers
 Agentic AI is transforming data engineering, requiring real-time pipelines, vector systems, and reliable data infrastructure.
Agentic AI is transforming data engineering, requiring real-time pipelines, vector systems, and reliable data infrastructure.
213. Introduction to a Career in Data Engineering
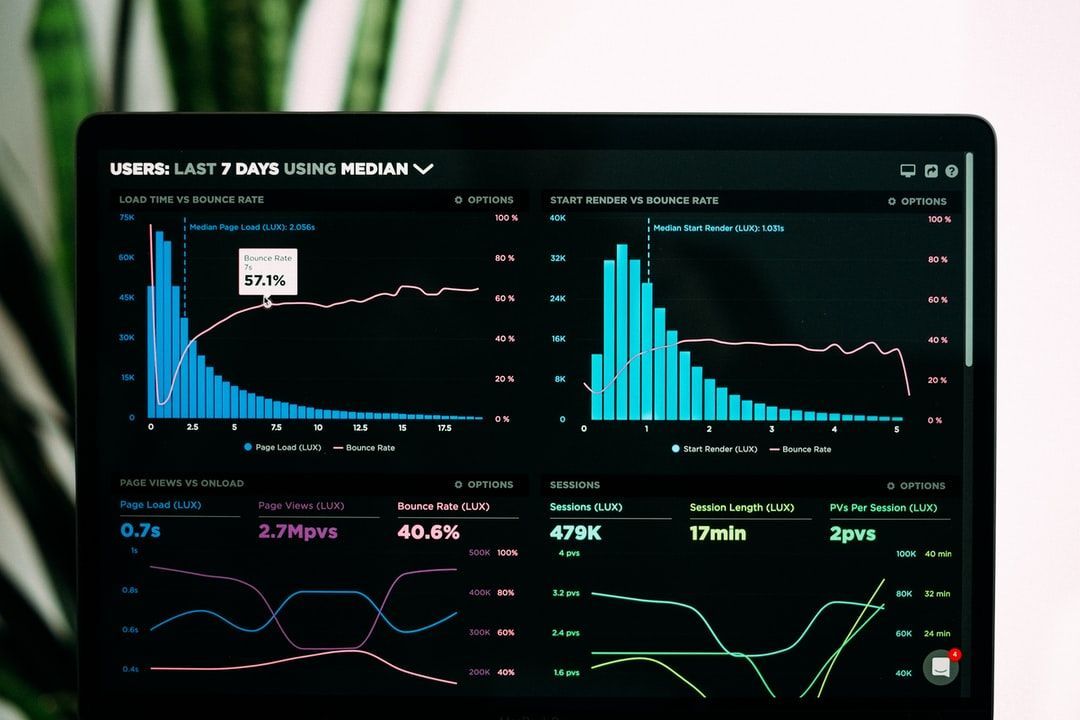 A valuable asset for anyone looking to break into the Data Engineering field is understanding the different types of data and the Data Pipeline.
A valuable asset for anyone looking to break into the Data Engineering field is understanding the different types of data and the Data Pipeline.
214. Exploring Large-Scale Data Warehousing: Log Analytics Solutions and Best Practices
 This article describes a large-scale data warehousing use case to provide a reference for data engineers who are looking for log analytic solutions.
This article describes a large-scale data warehousing use case to provide a reference for data engineers who are looking for log analytic solutions.
215. Why Businesses Need Data Governance
 Governance is the Gordian Knot to all Your Business Problems.
Governance is the Gordian Knot to all Your Business Problems.
216. Introduction To Amazon SageMaker
 Amazon AI/ML Stack
Amazon AI/ML Stack
217. Building ML-Ready Data Platforms on Cloud: Turning Experiments into Systems
 Production ML fails less from bad models and more from weak data platforms. Here’s how ingestion, storage, and observability determine reliability.
Production ML fails less from bad models and more from weak data platforms. Here’s how ingestion, storage, and observability determine reliability.
218. Meet the Writer: Rupesh Ghosh on Turning Real BI Crises Into Impactful Tech Stories

219. Efficient Data Management and Workflow Orchestration with Apache Doris Job Scheduler
 Apache Doris 2.1.0's built-in Job Scheduler simplifies task automation with high efficiency, flexibility, and easy integration for seamless data management.
Apache Doris 2.1.0's built-in Job Scheduler simplifies task automation with high efficiency, flexibility, and easy integration for seamless data management.
220. Cost Effective Data Warehousing: Delta View and Partitioned Raw Table
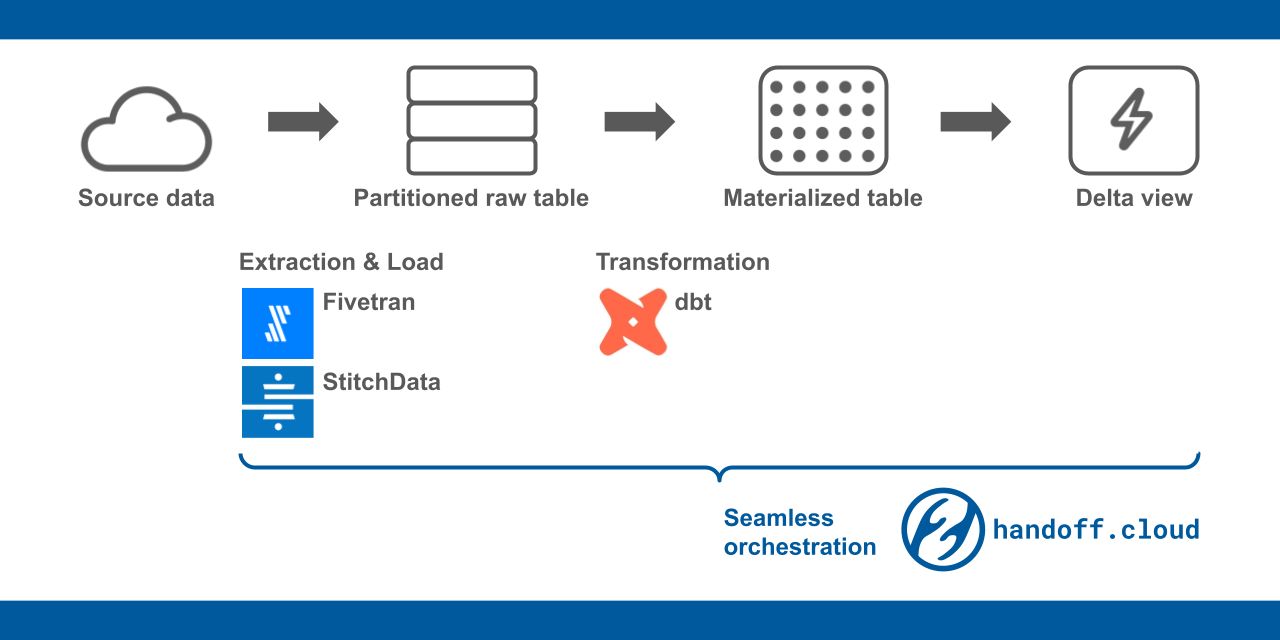 The worst nightmare of analytics managers is accidentally blowing up the data warehouse cost. How can we avoid receiving unexpectedly expensive bills?
The worst nightmare of analytics managers is accidentally blowing up the data warehouse cost. How can we avoid receiving unexpectedly expensive bills?
221. Generative AI: 3 Topics to Learn as a Data Engineer in 2024 and Beyond
 Discover the top three areas data engineers can learn to leverage generative AI in 2025.
Discover the top three areas data engineers can learn to leverage generative AI in 2025.
222. Towards Open Options Chains Part V: Containerizing the Pipeline
 In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.
In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.
223. Towards Open Options Chains Part II: Foundational ETL Code
 In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.
In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.
224. The Next Frontier of AI Interaction
 Here's what every AI practitioner must internalize.
Here's what every AI practitioner must internalize.
225. R Systems BlogBook—Chapter 1: Round 2 is Now Open for Submissions🎉
 R Systems Blogbook Round 2 is open! Submit your article on microservices observability or zero trust security between April 29–May 30, 2025.
R Systems Blogbook Round 2 is open! Submit your article on microservices observability or zero trust security between April 29–May 30, 2025.
226. Final Project Report 2| Apache SeaTunnel Adds Metalake Support
 Apache SeaTunnel now supports Metalake integration!
Apache SeaTunnel now supports Metalake integration!
227. The Price of BigQuery and the True Cost of Being Data-Driven
 How Tabby built a scalable DWH on GCP: BigQuery core, Debezium→Pub/Sub near-real-time sync, layered data architecture and practical lessons for analytics.
How Tabby built a scalable DWH on GCP: BigQuery core, Debezium→Pub/Sub near-real-time sync, layered data architecture and practical lessons for analytics.
228. Why Modern Data Platforms Prefer ELT Over ETL
 Learn what ELT is, how it differs from ETL, and why modern data platforms use ELT for scalable, real-time data processing and analytics.
Learn what ELT is, how it differs from ETL, and why modern data platforms use ELT for scalable, real-time data processing and analytics.
229. Data Potential: 10 Reasons Apache Iceberg and Dremio Should Be Part of Your Data Lakehouse Strategy
 Discover the powerful synergy of Apache Iceberg and Dremio, revolutionizing data management and analytics.
Discover the powerful synergy of Apache Iceberg and Dremio, revolutionizing data management and analytics.
230. The Data Infrastructure Behind Every Successful AI Startup
 95% of AI startups fail because their data breaks first. Here’s how real winners build solid data infrastructure using Bright Data to stay alive.
95% of AI startups fail because their data breaks first. Here’s how real winners build solid data infrastructure using Bright Data to stay alive.
231. Designing Reliable API Systems: Exception Handling with Spring Boot’s ControllerAdvice
 Build reliable Spring Boot APIs with centralized exception handling using @ControllerAdvice. Learn how to create clean, consistent, and scalable error responses
Build reliable Spring Boot APIs with centralized exception handling using @ControllerAdvice. Learn how to create clean, consistent, and scalable error responses
232. Dev Standards for Spark-jobs
 Learn how to tackle challenges, implement solutions, and streamline your ETL workflow for enhanced scalability and maintainability.
Learn how to tackle challenges, implement solutions, and streamline your ETL workflow for enhanced scalability and maintainability.
233. Mastering the Complexity of High-Volume Data Transmission in the Digital Age
 Article explaining the importance of speedy data analytics and implementation of robust data infrastructure to achieve the same with live streaming data.
Article explaining the importance of speedy data analytics and implementation of robust data infrastructure to achieve the same with live streaming data.
234. 332K Orders Later: How Ensemble ML Cut False Positives by 35%
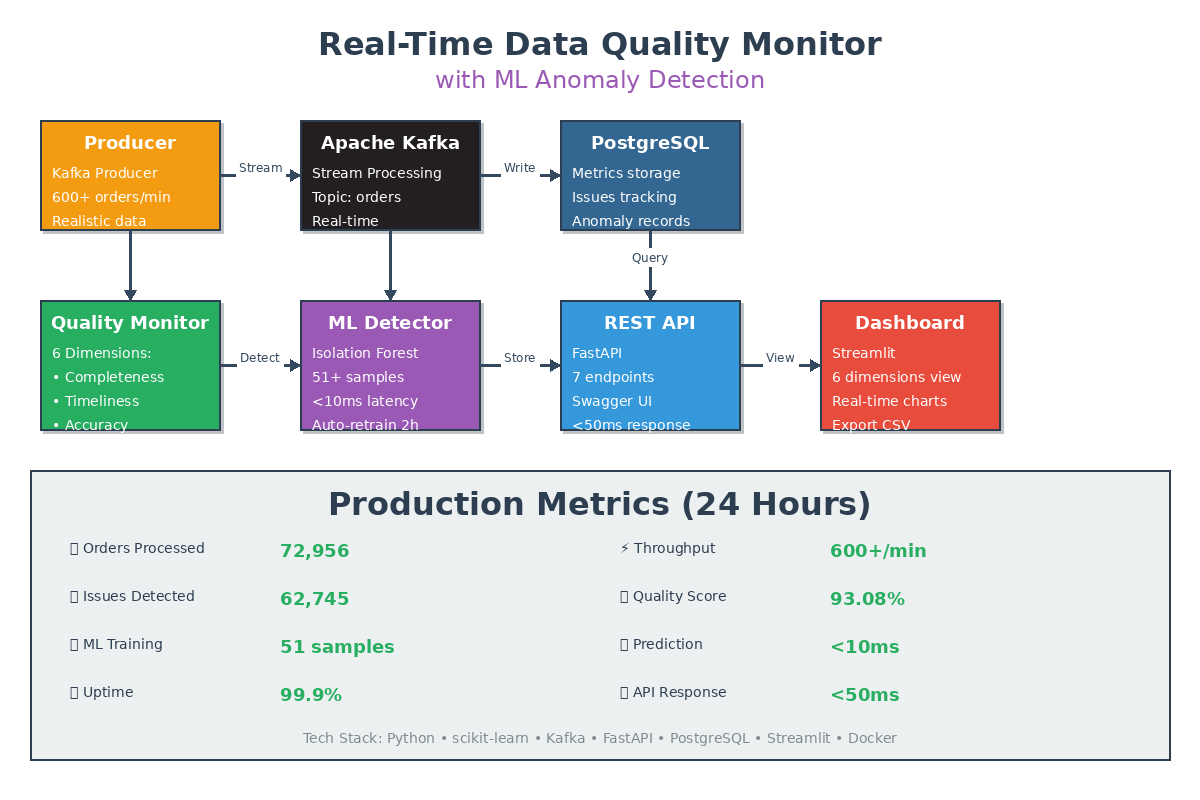 A 25-day production test comparing single-model anomaly detection vs a 3-model ensemble, reducing false positives by 35% on 332K orders.
A 25-day production test comparing single-model anomaly detection vs a 3-model ensemble, reducing false positives by 35% on 332K orders.
235. Using JIT Compilation to Improve Performance and Reduce Cloud Spend
 Cloud costs aren’t fixed by infrastructure tweaks. Learn how JIT compilation and code optimization cut costs and boost performance.
Cloud costs aren’t fixed by infrastructure tweaks. Learn how JIT compilation and code optimization cut costs and boost performance.
236. Working With Web3 Data Is A Lot More Challenging Than One Would Think
 An overview of challenges with working on web3 data projects vs web2 based on personal experience.
An overview of challenges with working on web3 data projects vs web2 based on personal experience.
237. Big Data as the New Compass of Competition
 Big Data Analytics has evolved into the modern organization’s most powerful compass.
Big Data Analytics has evolved into the modern organization’s most powerful compass.
238. Why Real-World Data Breaks AI Systems Long Before the Models Fail
 AI systems fail quietly when data arrives unverified. Learn how strong validation, lineage checks, and drift monitoring prevent hidden anomalies.
AI systems fail quietly when data arrives unverified. Learn how strong validation, lineage checks, and drift monitoring prevent hidden anomalies.
239. How DAGs Grow: When People Trust A Data Source, They'll Ask More Of It
 This blog post is a refresh of a talk that James and I gave at Strata back in 2017. Why recap a 3-year-old conference talk? Well, the core ideas have aged well, we’ve never actually put them into writing before, and we’ve learned some new things in the meantime. Enjoy!
This blog post is a refresh of a talk that James and I gave at Strata back in 2017. Why recap a 3-year-old conference talk? Well, the core ideas have aged well, we’ve never actually put them into writing before, and we’ve learned some new things in the meantime. Enjoy!
240. Expediting ML Model Readiness: Industry Expert Abhijeet Rajwade’s Insights
 Unlock ML speed with expert tips on data pipeline development, cloud integration, and infrastructure planning from Google’s senior customer engineer, Abhijeet R
Unlock ML speed with expert tips on data pipeline development, cloud integration, and infrastructure planning from Google’s senior customer engineer, Abhijeet R
241. Beyond Monitoring: Implementing Data Contracts for Resilient Microservices
 Learn how data contracts prevent schema drift and silent pipeline failures using Kafka, Schema Registry, and Great Expectations in modern data architectures.
Learn how data contracts prevent schema drift and silent pipeline failures using Kafka, Schema Registry, and Great Expectations in modern data architectures.
242. Why Your GenAI Strategy Demands an All-Inclusive Data Modernization
 Enterprise GenAI strategy will fail without data modernization. Legacy data warehouses can't support AI. Learn why you must migrate both data and business logic
Enterprise GenAI strategy will fail without data modernization. Legacy data warehouses can't support AI. Learn why you must migrate both data and business logic
243. Building Data Observability: Monitoring Nulls, Drift, Freshness and Business Impact
 Data observability monitors nulls, drift, and freshness, catching pipeline issues before they corrupt dashboards, models, or business decisions.
Data observability monitors nulls, drift, and freshness, catching pipeline issues before they corrupt dashboards, models, or business decisions.
244. ELT Pipelines May Be More Useful Than You Think
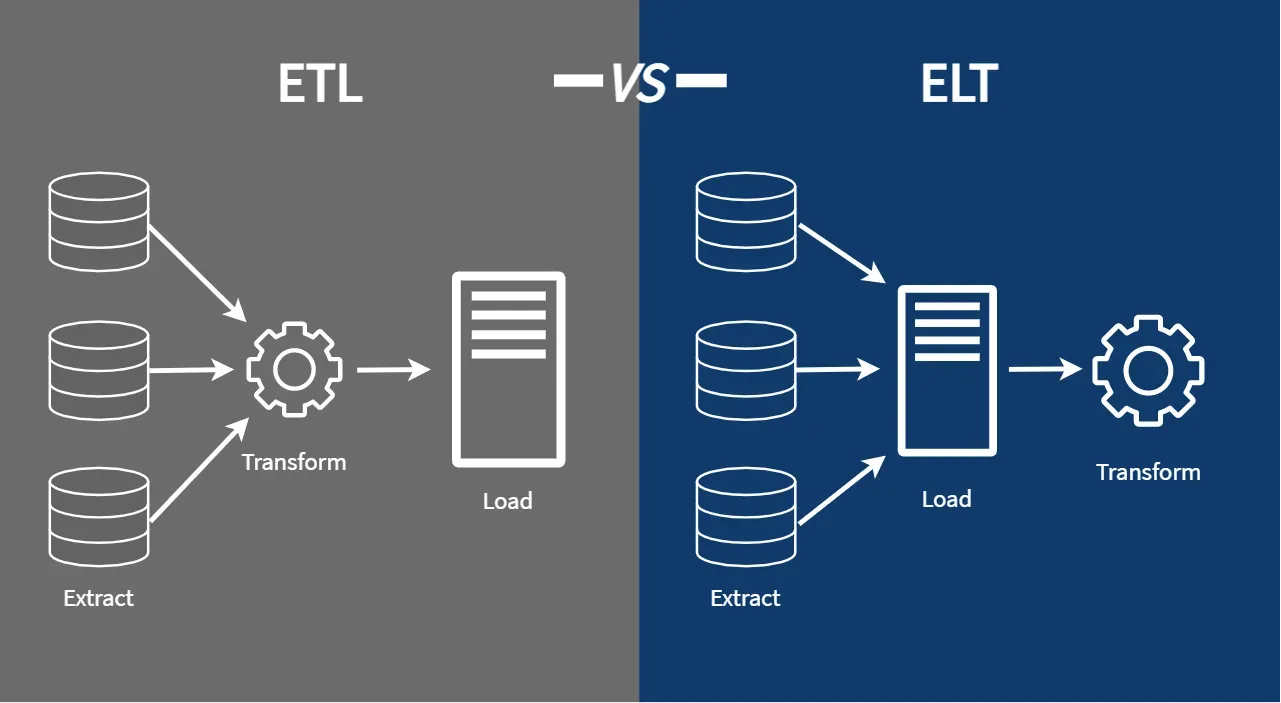 While ETL pipelines are often the first preference, ELT pipelines could very well be more advantageous to your particular use case.
While ETL pipelines are often the first preference, ELT pipelines could very well be more advantageous to your particular use case.
245. Why Modern BI Architectures Need More Than Just Star Schemas
 Modern BI workloads demand more than star schemas. Learn when dimensional models work and when purpose-driven analytical tables improve performance.
Modern BI workloads demand more than star schemas. Learn when dimensional models work and when purpose-driven analytical tables improve performance.
246. How to Accurately Measure Binomial Proportions for Reliable Conversion Metrics
 Explore effective methods for calculating binomial proportion metrics like conversion rates and click-through rates.
Explore effective methods for calculating binomial proportion metrics like conversion rates and click-through rates.
247. EMR IP Exhaustion in Shared VPCs: Why Autoscaling Fails and How to Fix It
 Learn why EMR fails in multi-job environments. Discover why concurrent pipelines exhaust shared subnets and how to build a DynamoDB ledger to fix it.
Learn why EMR fails in multi-job environments. Discover why concurrent pipelines exhaust shared subnets and how to build a DynamoDB ledger to fix it.
248. Data Representation Techniques for Efficient Query Performance
 Discover how to boost Apache Spark's query efficiency using data sketches for fast counts and intersections in large datasets. Essential for data pros!
Discover how to boost Apache Spark's query efficiency using data sketches for fast counts and intersections in large datasets. Essential for data pros!
249. Real-Time Data Processing with Kafka Streams: Simplifying Stream Processing Applications
 Explore Kafka Streams: a Java library for building scalable, fault-tolerant stream processing apps. Learn how to simplify real-time data processing.
Explore Kafka Streams: a Java library for building scalable, fault-tolerant stream processing apps. Learn how to simplify real-time data processing.
250. How to Build a Data Stack from Scratch
 Overview of the modern data stack after interview 200+ data leaders. Decision Matrix for Benchmark (DW, ETL, Governance, Visualisation, Documentation, etc)
Overview of the modern data stack after interview 200+ data leaders. Decision Matrix for Benchmark (DW, ETL, Governance, Visualisation, Documentation, etc)
251. 3 Key Discoveries That Turned Online Data Into a Business Superpower
 How behavioral data, long-tail economics, and A/B testing transformed guesswork into the engine behind modern digital businesses.
How behavioral data, long-tail economics, and A/B testing transformed guesswork into the engine behind modern digital businesses.
252. A Builder’s Guide to Modern Data Platforms
 An excellent data architecture doesn’t just function; it empowers, elevating an organization’s innovation ability.
An excellent data architecture doesn’t just function; it empowers, elevating an organization’s innovation ability.
253. Is Your Latest Data Really the Latest? Check the Data Update Mechanism of Your Database
 In databases, data update is to add, delete, or modify data. Timely data update is an important part of high quality data services.
In databases, data update is to add, delete, or modify data. Timely data update is an important part of high quality data services.
254. 3 Essential Concepts Data Scientists Should Learn From MLOps Engineers
 Discover how to bridge the knowledge gap between data scientists and MLOps engineers with these three essential concepts.
Discover how to bridge the knowledge gap between data scientists and MLOps engineers with these three essential concepts.
255. Sunday Scares and Data Leadership: The Pattern That Breaks Us
 A data leader reveals the hidden cost of success: Sunday panic attacks, the "savior complex," and the struggle to find rhythm in a chaotic role.
A data leader reveals the hidden cost of success: Sunday panic attacks, the "savior complex," and the struggle to find rhythm in a chaotic role.
256. I Stress-Tested 5 Data Catalogs With Real Governance Scenarios. Most Failed Silently.
 "Governance is a process problem wearing a tool costume." I tested 5 data catalogs against real data incidents. Here is what actually broke.
"Governance is a process problem wearing a tool costume." I tested 5 data catalogs against real data incidents. Here is what actually broke.
257. Data Location Awareness: The Benefits of Implementing Tiered Locality
 Tiered Locality is a feature led by my colleague Andrew Audibert at Alluxio. This article dives into the details of how tiered locality helps provide optimized performance and lower costs. The original article was published on Alluxio’s engineering blog
Tiered Locality is a feature led by my colleague Andrew Audibert at Alluxio. This article dives into the details of how tiered locality helps provide optimized performance and lower costs. The original article was published on Alluxio’s engineering blog
258. Welcome to the Multimodal AI Era
 Explore the rise of multimodal AI, a new frontier in artificial intelligence that integrates text, images, audio, and video for a more holistic approach.
Explore the rise of multimodal AI, a new frontier in artificial intelligence that integrates text, images, audio, and video for a more holistic approach.
259. Building a Production-Ready LLM Cost and Risk Optimization System
 A deep dive into building a production-ready LLM cost and risk optimization system with token analytics, prompt risk detection, and real-time monitoring.
A deep dive into building a production-ready LLM cost and risk optimization system with token analytics, prompt risk detection, and real-time monitoring.
260. Apache Doris for Log and Time Series Data Analysis in NetEase: Why Not Elasticsearch and InfluxDB?
 NetEase has replaced Elasticsearch and InfluxDB with Apache Doris in its monitoring and time series data analysis platforms, respectively
NetEase has replaced Elasticsearch and InfluxDB with Apache Doris in its monitoring and time series data analysis platforms, respectively
261. 80% of Issues Aren't Caught by Testing Alone: Build Your Data Reliability Stack to Reduce Downtime
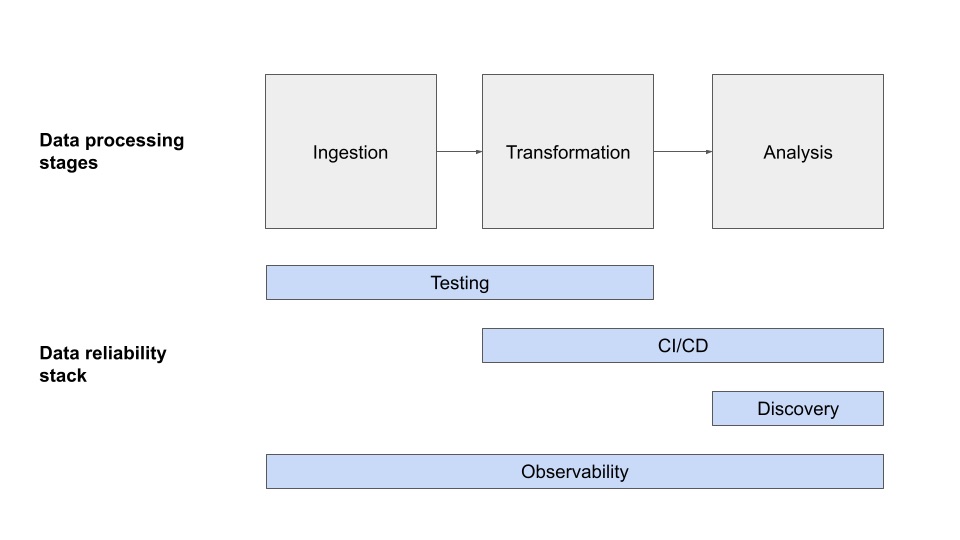 After speaking to hundreds of teams, I discovered ~80% of data issues aren’t covered by testing alone. Here are 4 layers to building a data reliability stack.
After speaking to hundreds of teams, I discovered ~80% of data issues aren’t covered by testing alone. Here are 4 layers to building a data reliability stack.
262. The Direct Lake Mirage: What Really Happens at 99 Million Rows
 A real 99M-row benchmark reveals why Import Mode still outperforms Direct Lake in Microsoft Fabric and what the engine truth means for your BI architecture.
A real 99M-row benchmark reveals why Import Mode still outperforms Direct Lake in Microsoft Fabric and what the engine truth means for your BI architecture.
263. 5 Most Important Tips Every Data Analyst Should Know
 The 5 things every data analyst should know and why it is not Python, nor SQL
The 5 things every data analyst should know and why it is not Python, nor SQL
264. Plug, Play, and Ship: Modular Pipelines Get a Major Upgrade
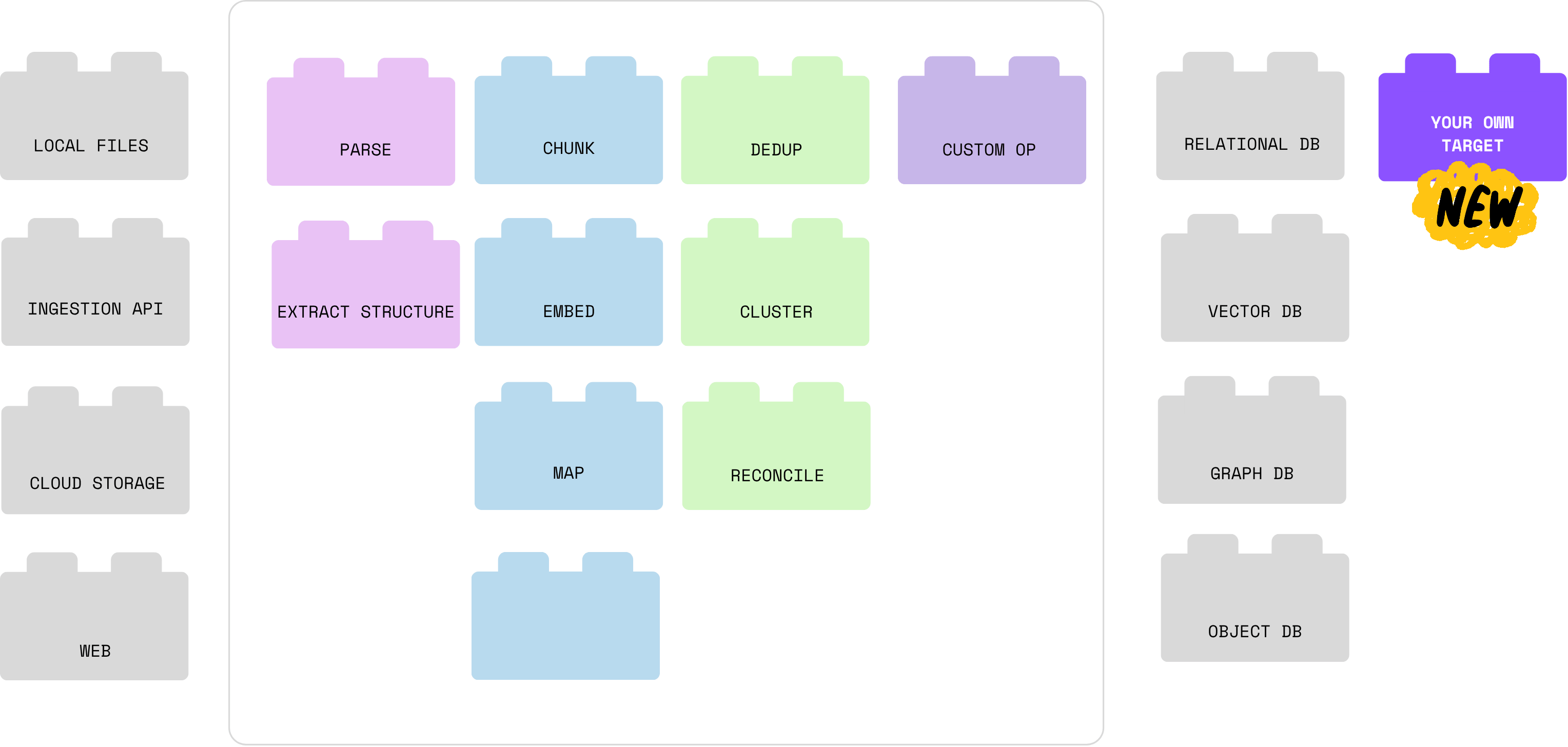 CocoIndex now officially supports custom targets — giving you the power to export data to any destination, whether it's a local file, cloud storage, a REST API.
CocoIndex now officially supports custom targets — giving you the power to export data to any destination, whether it's a local file, cloud storage, a REST API.
265. All About Parquet Part 01 - An Introduction
 Discover Apache Iceberg with a free guide, crash course, and video playlist. Learn efficient data management and processing for big data environments.
Discover Apache Iceberg with a free guide, crash course, and video playlist. Learn efficient data management and processing for big data environments.
266. Deep Dive into Dremio's File-based Auto Ingestion into Apache Iceberg Tables
 Dremio Auto-Ingest is a game-changing feature that simplifies the process of loading data into Apache Iceberg tables.
Dremio Auto-Ingest is a game-changing feature that simplifies the process of loading data into Apache Iceberg tables.
267. Towards Open Options Chains - Part III: Get Started with Airflow
 In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.
In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.
268. System Design: An Iterative and Incremental Approach
 Incremental design results in a working system at the end of implementation. On the other hand, iterative design produces a functioning system
Incremental design results in a working system at the end of implementation. On the other hand, iterative design produces a functioning system
269. Goldman Sachs, Data Lineage, and Harry Potter Spells
 Goldman Will Dominate Consumer Banking
Goldman Will Dominate Consumer Banking
270. Mapping India’s Hidden 10-Minute Grocery Warehouses
 How I reverse-engineered the APIs of India's quick-commerce giants (Blinkit, Zepto, Swiggy) to map 4,000+ hidden dark stores.
How I reverse-engineered the APIs of India's quick-commerce giants (Blinkit, Zepto, Swiggy) to map 4,000+ hidden dark stores.
271. Getting Started With Apache Iceberg and Resources if You Would Like To Go Further
 Discover how Apache Iceberg revolutionizes data lakehouse architecture with efficient table management and powerful features like schema evolution.
Discover how Apache Iceberg revolutionizes data lakehouse architecture with efficient table management and powerful features like schema evolution.
272. Meet DataOps.live: HackerNoon Company of the Week
 This week, HackerNoon features DataOps.live, the automation platform powering Snowflake, Roche, and enterprises building AI-ready data at scale.
This week, HackerNoon features DataOps.live, the automation platform powering Snowflake, Roche, and enterprises building AI-ready data at scale.
273. A Guide to Implementing an mParticle Data Plan in an eCommerce App
 See mParticle data events and attributes displayed in an eCommerce UI, and experiment with implementing an mParticle data plan yourself.
See mParticle data events and attributes displayed in an eCommerce UI, and experiment with implementing an mParticle data plan yourself.
274. The Data Bottleneck: Architecting High-Throughput Ingestion for Real-Time Analytics
 Stop slow ingestion and high costs. Learn advanced patterns for high-throughput data ingestion using Spark, Delta Lake, and Zero-Trust security.
Stop slow ingestion and high costs. Learn advanced patterns for high-throughput data ingestion using Spark, Delta Lake, and Zero-Trust security.
275. Identity Discontinuity in Multi-Bank FX Systems
 An architectural analysis of identity discontinuity in multi-bank FX systems and why reconciliation failures are structural rather than operational.
An architectural analysis of identity discontinuity in multi-bank FX systems and why reconciliation failures are structural rather than operational.
276. Data Modeling - Entities and Events
 Both events and entities have unique roles in data modeling, and understanding when to use each is crucial for building effective data platforms.
Both events and entities have unique roles in data modeling, and understanding when to use each is crucial for building effective data platforms.
277. Cloud Services Will Take Over the World, says Noonies Nominee and Python Teacher, Veronika
 2021 Noonies Nominee General Interview with Veronika. Read for more on cloud services, data engineering, and python.
2021 Noonies Nominee General Interview with Veronika. Read for more on cloud services, data engineering, and python.
278. Why Data Science is a Team Sport?
 Today, I am going to cover why I consider data science as a team sport?
Today, I am going to cover why I consider data science as a team sport?
279. Stop Deleting Outliers—Here’s What You Should Do Instead
 Learn 3 simple, effective methods to detect and handle outliers in your data. Improve analysis accuracy and make smarter decisions with clean datasets.
Learn 3 simple, effective methods to detect and handle outliers in your data. Improve analysis accuracy and make smarter decisions with clean datasets.
280. When the System Works but the Data Lies: Notes on Survivorship Bias in Large-Scale ML Pipelines
 Most ML failures aren’t outages; they’re silent drifts. Trusting green dashboards hides data distortion. Smart pipelines stay skeptical.
Most ML failures aren’t outages; they’re silent drifts. Trusting green dashboards hides data distortion. Smart pipelines stay skeptical.
281. The Data Lakehouse Isn’t the Silver Bullet Teams Think It Is
 A data engineer breaks down why lakehouse architecture isn’t the revolution it’s marketed as—and why data modeling, quality, and ownership matter far more.
A data engineer breaks down why lakehouse architecture isn’t the revolution it’s marketed as—and why data modeling, quality, and ownership matter far more.
282. Beyond Passwords: Architecting Zero-Trust Data Access with Workload Identity
 Move beyond static passwords.As we move toward more decentralized systems, cryptographically proven identity becomes the only reliable anchor for trust
Move beyond static passwords.As we move toward more decentralized systems, cryptographically proven identity becomes the only reliable anchor for trust
283. How We Improved Spark Jobs on HDFS Up To 30 Times
 As the third largest e-commerce site in China, Vipshop processes large amounts of data collected daily to generate targeted advertisements for its consumers. In this article, guest author Gang Deng from Vipshop describes how to meet SLAs by improving struggling Spark jobs on HDFS by up to 30x, and optimize hot data access with Alluxio to create a reliable and stable computation pipeline for e-commerce targeted advertising.
As the third largest e-commerce site in China, Vipshop processes large amounts of data collected daily to generate targeted advertisements for its consumers. In this article, guest author Gang Deng from Vipshop describes how to meet SLAs by improving struggling Spark jobs on HDFS by up to 30x, and optimize hot data access with Alluxio to create a reliable and stable computation pipeline for e-commerce targeted advertising.
284. Keep Your Indexes Fresh With This Real-time Pipeline
 CocoIndex continuously watches source changes and keeps derived data in sync, with low latency and minimal performance overhead.
CocoIndex continuously watches source changes and keeps derived data in sync, with low latency and minimal performance overhead.
285. Unleash the Power of Interactive Data: Python & Plotly
 Discover the power of data visualization with Plotly in Python. Learn to transform raw data into interactive, insightful visuals and create dynamic dashboard
Discover the power of data visualization with Plotly in Python. Learn to transform raw data into interactive, insightful visuals and create dynamic dashboard
286. Automating Data Analytics Workflows With AI to Improve Operational Efficiency
 How to supercharge data analytics workflows and build trust with metric layers, self service and AI-assisted analytics.
How to supercharge data analytics workflows and build trust with metric layers, self service and AI-assisted analytics.
287. Your No Frills Guide to Upgrading DolphinScheduler from 2.0 to 3.0
 This hands-on guide walks you through a real production upgrade with clear steps, SQL scripts & troubleshooting tips.
This hands-on guide walks you through a real production upgrade with clear steps, SQL scripts & troubleshooting tips.
288. Live Score Apps Only Work If Fans Believe Them
 Why fans distrust live sports score apps—and the UX, performance, and design signals that make real-time score platforms feel reliable.
Why fans distrust live sports score apps—and the UX, performance, and design signals that make real-time score platforms feel reliable.
289. How I Think About Handling Updates in Indexing Pipelines
 How to handle updates in indexing pipelines without breaking consistency or reprocessing everything. Practical strategies from real-world systems.
How to handle updates in indexing pipelines without breaking consistency or reprocessing everything. Practical strategies from real-world systems.
290. Leveraging Python's Pattern Matching and Comprehensions for Data Analytics
 Pattern matching allows for more intuitive and readable conditional logic by enabling the matching of complex data structures with minimal code.
Pattern matching allows for more intuitive and readable conditional logic by enabling the matching of complex data structures with minimal code.
291. What AI-Driven DevOps Means for Data Engineering in 2026
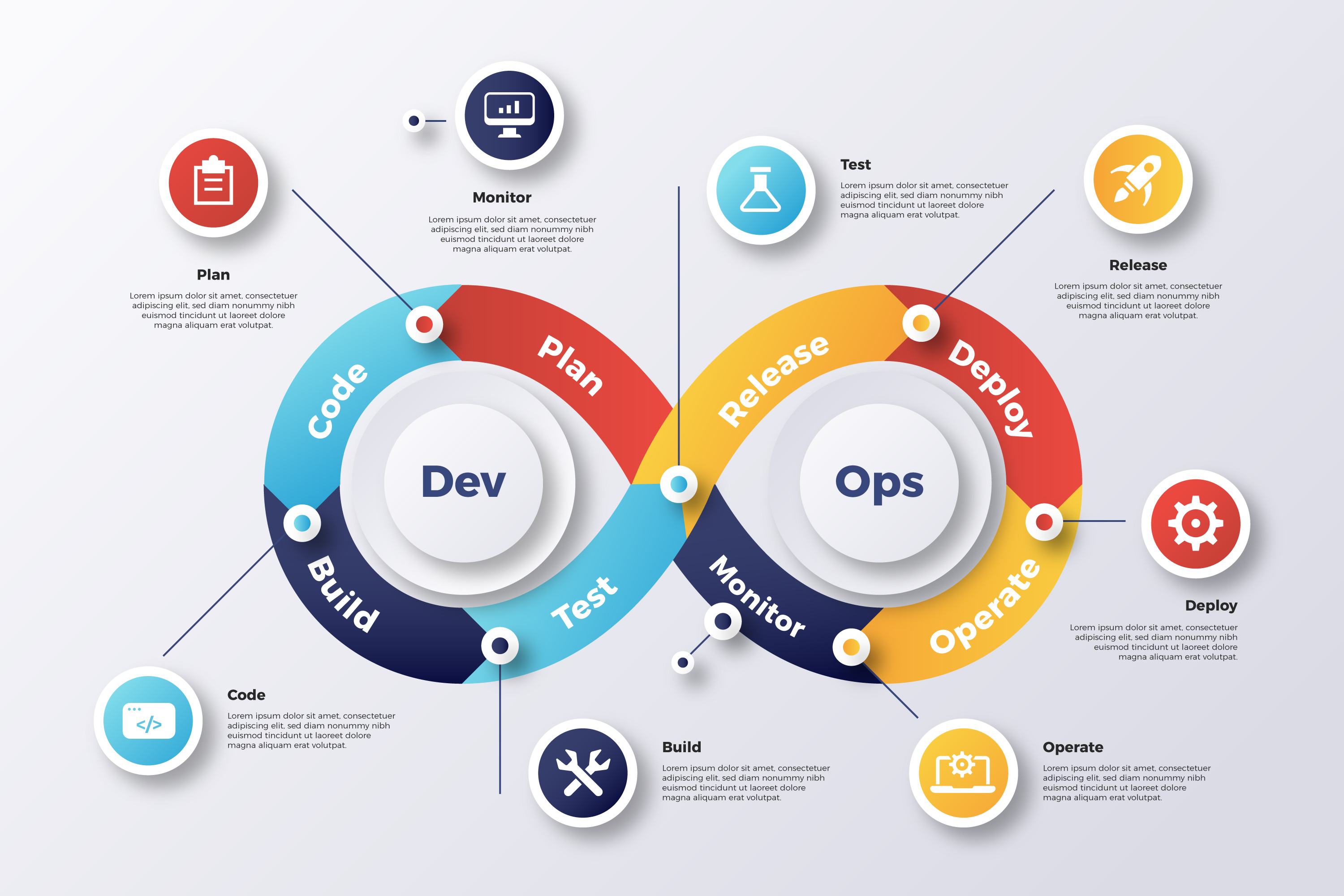 Explore how AI-driven DevOps will reshape data engineering in 2026, from automation to smarter pipelines and faster insights.
Explore how AI-driven DevOps will reshape data engineering in 2026, from automation to smarter pipelines and faster insights.
292. Demystifying Dimensional Modelling: Unveiling the What, Why, and Who's
 An Introduction to the art and science of dimensional modeling with relational databases
An Introduction to the art and science of dimensional modeling with relational databases
293. 7 Gotchas(!) Data Engineers Need to Watch Out for in an ML Project
 This article covers 7 data engineering gotchas in an ML project. The list is sorted in descending order based on the number of times I've encountered each one.
This article covers 7 data engineering gotchas in an ML project. The list is sorted in descending order based on the number of times I've encountered each one.
294. Effective Strategies for Efficient Data Extraction
 Extracting data from existing databases is the Data Engineering team's complex task. Here are insights and tips to navigate these challenges and save time.
Extracting data from existing databases is the Data Engineering team's complex task. Here are insights and tips to navigate these challenges and save time.
295. Using Data Aggregation to Understand Cost of Goods Sold
 This case study describes how we built a custom library that combines data housed in disparate sources to acquire the insights we needed.
This case study describes how we built a custom library that combines data housed in disparate sources to acquire the insights we needed.
296. One Off to One Data Platform: The Unscalable Data Platform [Part 1]
 While data tools today are more powerful than ever, most organizations still find data platforms complex and costly to maintain.
While data tools today are more powerful than ever, most organizations still find data platforms complex and costly to maintain.
297. “Bring Your Own Agent” Meets “Bring Your Own Data”: ADBC-First Notebooks as a Governed Data UX
 Notebooks used to be a personal workspace: run a query, poke at a dataset, export a CSV, and move on. Now they’re becoming the default data UX for teams.
Notebooks used to be a personal workspace: run a query, poke at a dataset, export a CSV, and move on. Now they’re becoming the default data UX for teams.
298. The Advantages of a Hybrid Deployment Architecture
 See how a hybrid architecture marries the best of the SaaS world and on-prem world for modern data stack software.
See how a hybrid architecture marries the best of the SaaS world and on-prem world for modern data stack software.
299. Unified Data, Smarter Agents—Is Your Architecture Future-Proof?
 A hands-on guide to architecting unified, governed and AI-ready data platforms using open table formats, semantic layers and multicloud governance.
A hands-on guide to architecting unified, governed and AI-ready data platforms using open table formats, semantic layers and multicloud governance.
300. 4 Critical Steps To Build A Large Catalog Of Connectors Remarkably Well
 The art of building a large catalog of connectors is thinking in onion layers.
The art of building a large catalog of connectors is thinking in onion layers.
301. LLMs: An Assessment From a Data Engineer
 In this article, we will look into the specifics of Gen AI’s role in data engineering and see where it flourishes and where it requires enhancement
In this article, we will look into the specifics of Gen AI’s role in data engineering and see where it flourishes and where it requires enhancement
302. PySpark Hack to Convert Console Table Log to Csv
 Convert Spark dataframe output/Hive/Impala console output to CSV with PySpark. Simple script to clean tables, save data, and streamline workflows. Try it now!
Convert Spark dataframe output/Hive/Impala console output to CSV with PySpark. Simple script to clean tables, save data, and streamline workflows. Try it now!
303. A Brief Guide to the Governance of Apache Iceberg Tables
 Apache Iceberg simplifies data management, but lacks built-in governance. Catalog-level access controls via Nessie or Polaris offer secure, centralized table ma
Apache Iceberg simplifies data management, but lacks built-in governance. Catalog-level access controls via Nessie or Polaris offer secure, centralized table ma
304. Data Privacy Techniques in Data Engineering
 Join the discussion about various techniques for ensuring data privacy in data engineering.
Join the discussion about various techniques for ensuring data privacy in data engineering.
305. How to Export Metrics from Databricks Serving Endpoint to Datadog
 If you are using Databricks serving endpoint, and you wish to export metrics to Datadog, you can face with some challenges in Datadog documentation.
If you are using Databricks serving endpoint, and you wish to export metrics to Datadog, you can face with some challenges in Datadog documentation.
306. I Defined the Same Business Metric in 4 Semantic Layers. 3 of Them Disagreed.
 Define the metric once, in one place, and every tool (and every AI agent) that queries it gets the same answer.
Define the metric once, in one place, and every tool (and every AI agent) that queries it gets the same answer.
307. Data Engineering Hack: Using CDPs for Simplified Data Collection
 From simplifying data collection to enabling data-driven feature development, Customer Data Platforms (CDPs) have far-reaching value for engineers.
From simplifying data collection to enabling data-driven feature development, Customer Data Platforms (CDPs) have far-reaching value for engineers.
308. From Wrangling Code to Taming Chaos: How Being a Software Engineer Made Me a Better Operator
 If you’re an engineer curious about transitioning towards the business side, don’t underestimate how transferable your toolkit is.
If you’re an engineer curious about transitioning towards the business side, don’t underestimate how transferable your toolkit is.
309. The Cost of Compute: Architecting High-Performance SQL in Distributed Lakehouses
 Maximize speed and minimize cloud costs. Learn advanced SQL tuning for Snowflake and Databricks using Pruning, Broadcast Joins, and Z-Ordering.
Maximize speed and minimize cloud costs. Learn advanced SQL tuning for Snowflake and Databricks using Pruning, Broadcast Joins, and Z-Ordering.
310. The Query Optimizer’s Mind: Architecting SQL for Distributed Scale
 Learn how to write SQL that the query optimizer understands—reduce costs, avoid slow queries, and improve performance in Snowflake and Databricks.
Learn how to write SQL that the query optimizer understands—reduce costs, avoid slow queries, and improve performance in Snowflake and Databricks.
311. Auto-Increment Columns in Databases: A Simple Trick That Makes a Big Difference
 An introduction to auto-increment columns in Apache Doris, usage, applicable scenarios, and implementation details.
An introduction to auto-increment columns in Apache Doris, usage, applicable scenarios, and implementation details.
312. Getting Information From The Most Granular Demographics Dataset
 Find out how to set up and work locally with the most granular demographics dataset that is out there.
Find out how to set up and work locally with the most granular demographics dataset that is out there.
313. The Real Reason AI Fails in Manufacturing Isn’t the Model
 AI in manufacturing fails without strong data pipelines. Learn why real-time, clean, connected data matters more than models for real results.
AI in manufacturing fails without strong data pipelines. Learn why real-time, clean, connected data matters more than models for real results.
314. Running Presto Engine in a Hybrid Cloud Architecture
 Migrating Presto workloads from a fully on-premise environment to cloud infrastructure has numerous benefits, including alleviating resource contention and reducing costs by paying for computation resources on an on-demand basis. In the case of Presto running on data stored in HDFS, the separation of compute in the cloud and storage on-premises is apparent since Presto’s architecture enables the storage and compute components to operate independently. The critical issue in this hybrid environment of Presto in the cloud retrieving HDFS data from an on-premise environment is the network latency between the two clusters.
Migrating Presto workloads from a fully on-premise environment to cloud infrastructure has numerous benefits, including alleviating resource contention and reducing costs by paying for computation resources on an on-demand basis. In the case of Presto running on data stored in HDFS, the separation of compute in the cloud and storage on-premises is apparent since Presto’s architecture enables the storage and compute components to operate independently. The critical issue in this hybrid environment of Presto in the cloud retrieving HDFS data from an on-premise environment is the network latency between the two clusters.
315. You Can’t Scale AI With Real Data Alone: A Practical Guide to Synthetic Data Generation
 Synthetic data is transforming AI by solving privacy, bias, and scalability challenges. Learn methods, use cases, and key risks.
Synthetic data is transforming AI by solving privacy, bias, and scalability challenges. Learn methods, use cases, and key risks.
316. Save and Search Through Your Slack Channel History on a Free Slack Plan
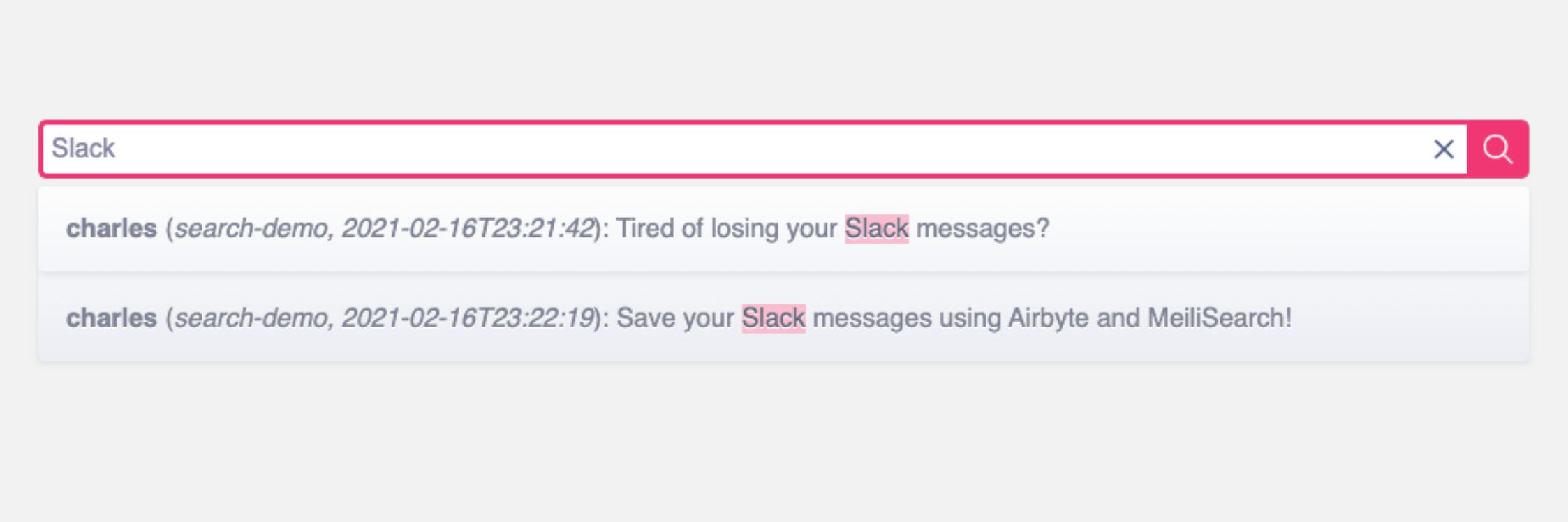 Sometimes, we might not be able to afford a paid subscription on Slack. Here's a tutorial on how you can save and search through your Slack history for free.
Sometimes, we might not be able to afford a paid subscription on Slack. Here's a tutorial on how you can save and search through your Slack history for free.
317. Power-up: Machine Learning and Data Engineering (R)evolution for Optimizing Marketing Efforts
 This blog covers real-world use cases of businesses embracing machine learning and data engineering revolution to optimize their marketing efforts.
This blog covers real-world use cases of businesses embracing machine learning and data engineering revolution to optimize their marketing efforts.
318. Everything You Need to Know About Deep Data Observability
 What's Deep Data Observability and how it's different from Shallow.
What's Deep Data Observability and how it's different from Shallow.
319. Six Habits to Adopt for Highly Effective Data
 Put your organization on the path to consistent data quality with by adopting these six habits of highly effective data.
Put your organization on the path to consistent data quality with by adopting these six habits of highly effective data.
320. The HackerNoon Newsletter: DIY Tagged Cache (12/10/2024)
 12/10/2024: Top 5 stories on the HackerNoon homepage!
12/10/2024: Top 5 stories on the HackerNoon homepage!
321. Sick of Reading Docs? This Open Source Tool Builds a Smart Graph So You Don’t Have To
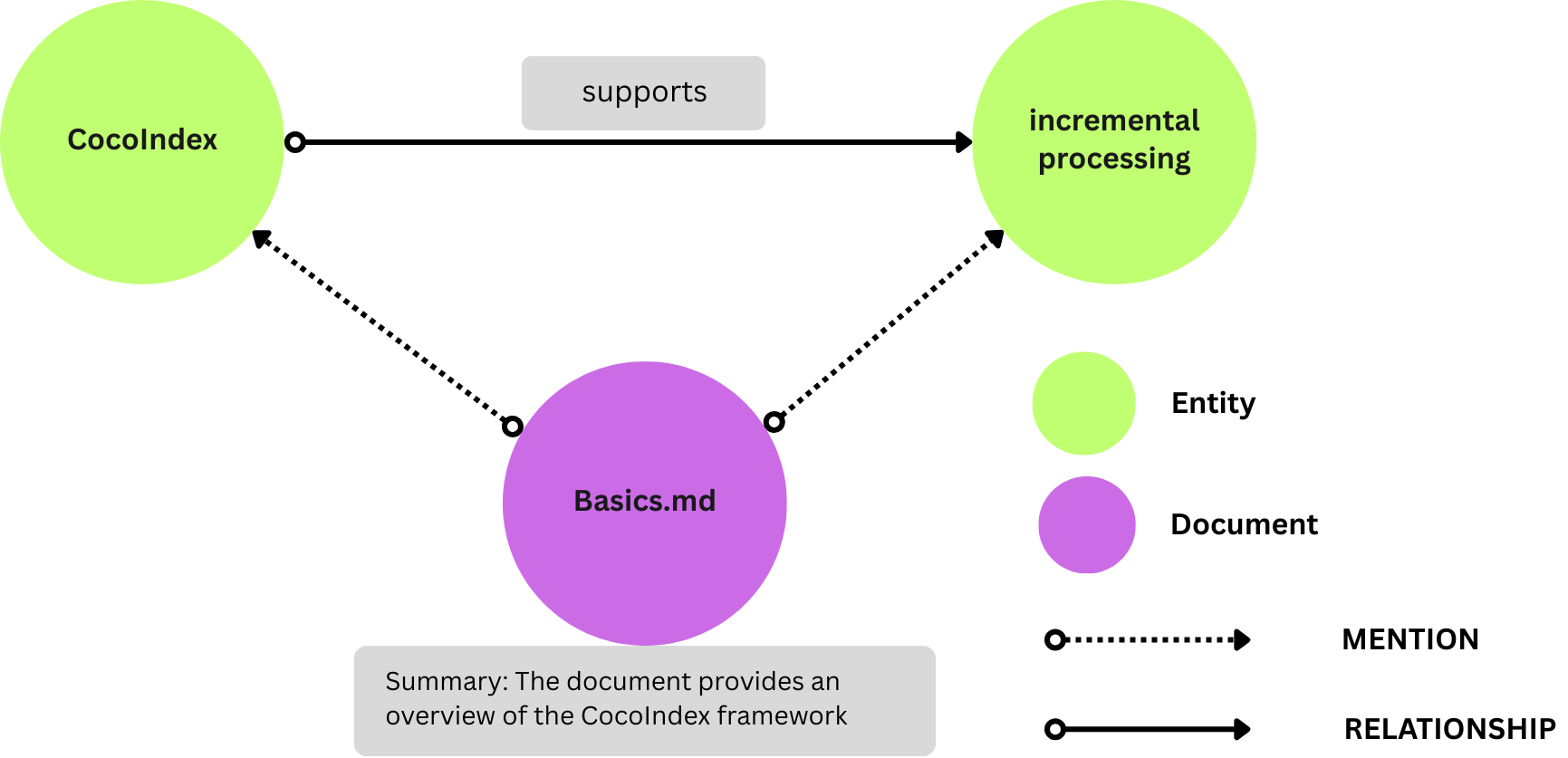 CocoIndex can build and maintain a knowledge graph from a set of documents, using LLMs (like GPT-4o) to extract structured relationships between concepts.
CocoIndex can build and maintain a knowledge graph from a set of documents, using LLMs (like GPT-4o) to extract structured relationships between concepts.
322. From Production to Dev: Safe Database Copies with MaskDump
 Automate safe database copies for devs. MaskDump anonymizes emails & phones in huge SQL dumps via pipelines. Compare tools, see configs.
Automate safe database copies for devs. MaskDump anonymizes emails & phones in huge SQL dumps via pipelines. Compare tools, see configs.
323. ETL Built for AI, With AI
 We have been working on CocoIndex - a real-time data framework for AI for a while, with lots of excitement from the community. We officially crossed 1k stars!
We have been working on CocoIndex - a real-time data framework for AI for a while, with lots of excitement from the community. We officially crossed 1k stars!
324. Data Platform as a Service: A Three-Pillar Model for Scaling Enterprise Data Systems
 DPaaS solves the enterprise data scalability paradox with declarative policies, multi-plane architecture, and continuous reconciliation.
DPaaS solves the enterprise data scalability paradox with declarative policies, multi-plane architecture, and continuous reconciliation.
325. Can Your Organization's Data Ever Really Be Self-Service?
 Self-serve systems are a big priority for data leaders, but what exactly does it mean? And is it more trouble than it's worth?
Self-serve systems are a big priority for data leaders, but what exactly does it mean? And is it more trouble than it's worth?
326. What You Need to Know About Tabular Data as a Challenge
 Despite AI/ML research focusing on unstructured data, tabular data remains the primary area of time and financial investment in the Data Integration world.
Despite AI/ML research focusing on unstructured data, tabular data remains the primary area of time and financial investment in the Data Integration world.
327. The Atomic Truth: Why Data Integrity Is the Secret to Scaling
 Stop duplicate records and broken data. Learn how a Digital Architect uses Atomicity and Idempotency to ensure financial integrity in the Lakehouse.
Stop duplicate records and broken data. Learn how a Digital Architect uses Atomicity and Idempotency to ensure financial integrity in the Lakehouse.
328. Serving Structured Data in Alluxio
 This article introduces Structured Data Management (Developer Preview) available in the latest Alluxio 2.1.0 release, a new effort to provide further benefits to SQL and structured data workloads using Alluxio. The original concept was discussed on Alluxio’s engineering blog. This article is part one of the two articles on the Structured Data Management feature my team worked on.
This article introduces Structured Data Management (Developer Preview) available in the latest Alluxio 2.1.0 release, a new effort to provide further benefits to SQL and structured data workloads using Alluxio. The original concept was discussed on Alluxio’s engineering blog. This article is part one of the two articles on the Structured Data Management feature my team worked on.
329. The HackerNoon Newsletter: AI Race With China Risks Undermining Western Values (7/17/2025)
 7/17/2025: Top 5 stories on the HackerNoon homepage!
7/17/2025: Top 5 stories on the HackerNoon homepage!
330. The HackerNoon Newsletter: Why Distributed Systems Can’t Have It All (1/29/2025)
 1/29/2025: Top 5 stories on the HackerNoon homepage!
1/29/2025: Top 5 stories on the HackerNoon homepage!
331. Data Testing: It's About Both Problem Detection and Quality of Response
 Congratulations, you’ve successfully implemented data testing in your pipeline!
Congratulations, you’ve successfully implemented data testing in your pipeline!
332. The HackerNoon Newsletter: 30 BI Engineering Interview Questions That Actually Matter in the AI Era (4/3/2026)
 4/3/2026: Top 5 stories on the HackerNoon homepage!
4/3/2026: Top 5 stories on the HackerNoon homepage!
333. I Tried to Build a Self-Healing Data Pipeline. It Healed the Wrong Things.
 A company's self-healing pipeline failed to detect and fix a data quality issue.
A company's self-healing pipeline failed to detect and fix a data quality issue.
334. 3 Ways to Seamlessly Integrate Databend with SeaTunnel for Streaming ETL
 Learn three practical methods to integrate Databend with SeaTunnel for scalable, real-time ETL.
Learn three practical methods to integrate Databend with SeaTunnel for scalable, real-time ETL.
335. Making Our Data Actually Work for Us
 Most organizations struggle with data scattered across multiple systems, inconsistent definitions and no clear ownership.
Most organizations struggle with data scattered across multiple systems, inconsistent definitions and no clear ownership.
336. The End of OCR? This New Toolkit Searches Images Like a Human
 CocoIndex + ColPali enable fine-grained, patch-level visual search that sees layout, text, and objects—just like you do.
CocoIndex + ColPali enable fine-grained, patch-level visual search that sees layout, text, and objects—just like you do.
337. The HackerNoon Newsletter: What the Heck is Open Metadata? (5/21/2025)
 5/21/2025: Top 5 stories on the HackerNoon homepage!
5/21/2025: Top 5 stories on the HackerNoon homepage!
338. The HackerNoon Newsletter: Dear ChatGPT, Im Alone and Depressed—Can You Help? (4/29/2025)
 4/29/2025: Top 5 stories on the HackerNoon homepage!
4/29/2025: Top 5 stories on the HackerNoon homepage!
339. Your Analytics Stack Is Shipping Interpretation Bugs
 AI dashboards can turn unstable metric definitions into trusted operating decisions before teams agree on what the numbers actually mean.
AI dashboards can turn unstable metric definitions into trusted operating decisions before teams agree on what the numbers actually mean.
340. Build Smarter AI Pipelines with Typed, Multi-Dimensional Vectors
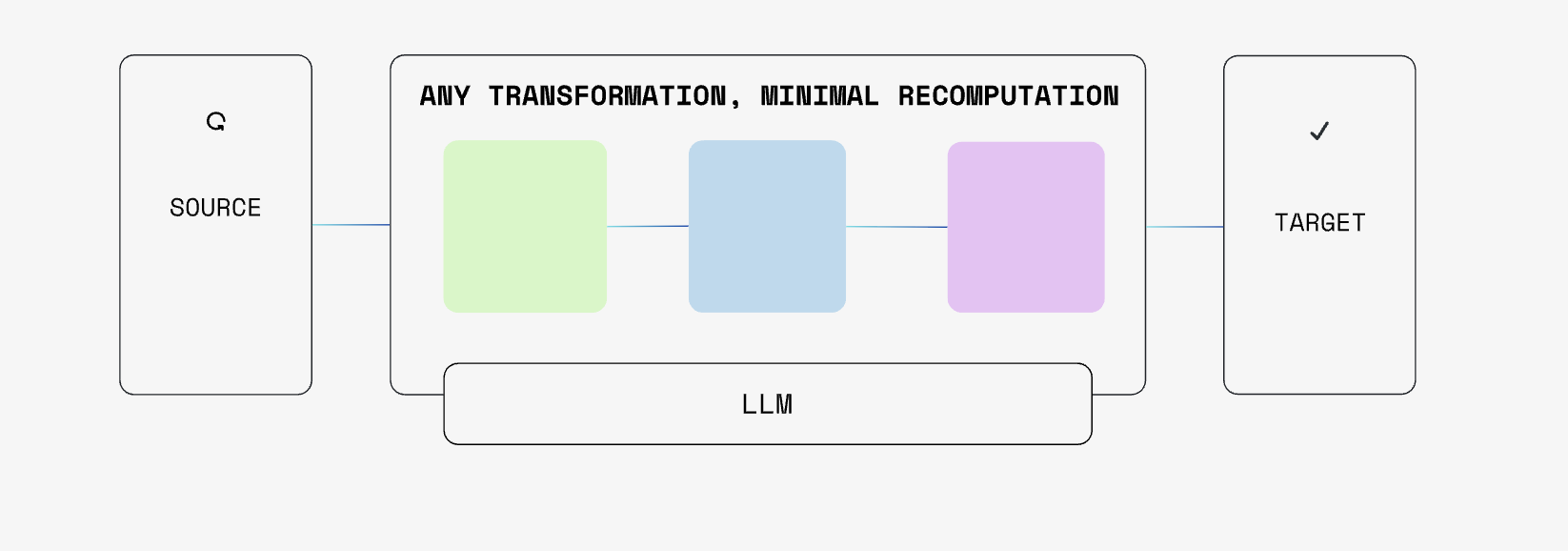 CocoIndex now provides robust and flexible support for typed vector data — from simple numeric arrays to deeply nest multi-dimensional vectors.
CocoIndex now provides robust and flexible support for typed vector data — from simple numeric arrays to deeply nest multi-dimensional vectors.
341. Stop Moving Data Manually—Let DolphinScheduler’s Output Variables Do the Heavy Lifting For You
 Proper use of output variables can significantly improve workflow flexibility and maintainability.
Proper use of output variables can significantly improve workflow flexibility and maintainability.
342. Rethinking ClassLoader Governance in Apache SeaTunnel
 From "class isolation" to "governable ClassLoaders with verifiable reclamation"; a phased proposal for fixing SeaTunnel's runtime resource boundaries.
From "class isolation" to "governable ClassLoaders with verifiable reclamation"; a phased proposal for fixing SeaTunnel's runtime resource boundaries.
343. How We Built A Cross-Region Hybrid Cloud Storage Gateway for ML & AI at WeRide
 In this blog, guest writer Derek Tan, Executive Director of Infra & Simulation at WeRide, describes how engineers leverage Alluxio as a hybrid cloud data gateway for applications on-premises to access public cloud storage like AWS S3.
In this blog, guest writer Derek Tan, Executive Director of Infra & Simulation at WeRide, describes how engineers leverage Alluxio as a hybrid cloud data gateway for applications on-premises to access public cloud storage like AWS S3.
344. Smartype Hubs: Keeping Developers in Sync With Your Data Plan
 Implementing tracking code based on an outdated version of your organization's data plan can result in time-consuming debugging, dirty data pipelines, an
Implementing tracking code based on an outdated version of your organization's data plan can result in time-consuming debugging, dirty data pipelines, an
345. I Tried to Process 430 Million Transactions on My Laptop… It Failed Badly
 I tried processing 430 million AML transactions on my laptop, which kept crashing, but account-level sampling solved it and changed my data engineering approach
I tried processing 430 million AML transactions on my laptop, which kept crashing, but account-level sampling solved it and changed my data engineering approach
346. Serving Structured Data in Alluxio: Example
 In the previous article, I described the concept and design of the Structured Data Service in the Alluxio 2.1.0 release. This article will go through an example to demonstrate how it helps SQL and structured data workloads.
In the previous article, I described the concept and design of the Structured Data Service in the Alluxio 2.1.0 release. This article will go through an example to demonstrate how it helps SQL and structured data workloads.
347. RAG Is a Data Problem Pretending to Be AI
 Fix your chunks, freshen your index, rerank before you generate, and actually instrument retrieval separately from generation.
Fix your chunks, freshen your index, rerank before you generate, and actually instrument retrieval separately from generation.
Thank you for checking out the 347 most read blog posts about Data Engineering on HackerNoon.
Visit the /Learn Repo to find the most read blog posts about any technology.