

Let's learn about Datasets via these 102 free blog posts. They are ordered by HackerNoon reader engagement data. Visit the Learn Repo or LearnRepo.com to find the most read blog posts about any technology.
Learn how to leverage diverse datasets to fuel innovation and solve complex problems.
1. 15 Excel Datasets for Data Analytics Beginners
 Excel is an indispensable tool for data manipulation, data visualization and statistical analysis. These are 15 Excel datasets for data analytics beginners.
Excel is an indispensable tool for data manipulation, data visualization and statistical analysis. These are 15 Excel datasets for data analytics beginners.
2. 13 Best Datasets for Power BI Practice
 In 2022, Gartner named Microsoft Power BI the Business Intelligence and Analytics Platforms leader. These are the 13 Best Datasets for Power BI Practice.
In 2022, Gartner named Microsoft Power BI the Business Intelligence and Analytics Platforms leader. These are the 13 Best Datasets for Power BI Practice.
3. 14 Best Tableau Datasets for Practicing Data Visualization
 This article focuses on the 14 Best Tableau Datasets for Practicing Data Visualization, which is essential for business analysts and data scientists.
This article focuses on the 14 Best Tableau Datasets for Practicing Data Visualization, which is essential for business analysts and data scientists.
4. 10 Best Datasets for Time Series Analysis
 In order to understand how a certain metric varies over time and to predict future values, we will look at the 10 Best Datasets for Time Series Analysis.
In order to understand how a certain metric varies over time and to predict future values, we will look at the 10 Best Datasets for Time Series Analysis.
5. 10 Data Table Libraries for JavaScript
 Tables are a useful tool for visualizing, organizing and processing data in JavaScript. To start using them, you need to download a free library or one for a reasonable price. Here is a list of 10 useful, functional, and reliable JS libraries that will help you work with tables.
Tables are a useful tool for visualizing, organizing and processing data in JavaScript. To start using them, you need to download a free library or one for a reasonable price. Here is a list of 10 useful, functional, and reliable JS libraries that will help you work with tables.
6. Top 20 Image Datasets for Machine Learning and Computer Vision
 Computer vision enables computers to understand the content of images and videos. The goal in computer vision is to automate tasks that the human visual system can do.
Computer vision enables computers to understand the content of images and videos. The goal in computer vision is to automate tasks that the human visual system can do.
7. 7 Effective Ways to Deal With a Small Dataset
 In a real-world setting, you often only have a small dataset to work with. Models trained on a small number of observations tend to overfit and produce inaccurate results. Learn how to avoid overfitting and get accurate predictions even if available data is scarce.
In a real-world setting, you often only have a small dataset to work with. Models trained on a small number of observations tend to overfit and produce inaccurate results. Learn how to avoid overfitting and get accurate predictions even if available data is scarce.
8. 16 Best Sklearn Datasets for Building Machine Learning Models
 Sklearn datasets are included as part of the scikit-learn (sklearn) library, so they come pre-installed with the library.
Sklearn datasets are included as part of the scikit-learn (sklearn) library, so they come pre-installed with the library.
9. Top 15 Chatbot Datasets for NLP Projects
 An effective chatbot requires a massive amount of training data in order to quickly solve user inquiries without human intervention. However, the primary bottleneck in chatbot development is obtaining realistic, task-oriented dialog data to train these machine learning-based systems.
An effective chatbot requires a massive amount of training data in order to quickly solve user inquiries without human intervention. However, the primary bottleneck in chatbot development is obtaining realistic, task-oriented dialog data to train these machine learning-based systems.
10. 14 Open Datasets for Text Classification in Machine Learning
 Text classification datasets are used to categorize natural language texts according to content. For example, think classifying news articles by topic, or classifying book reviews based on a positive or negative response. Text classification is also helpful for language detection, organizing customer feedback, and fraud detection. Though time consuming when done manually, this process can be automated with machine learning models. The result saves companies time while also providing valuable data insights.
Text classification datasets are used to categorize natural language texts according to content. For example, think classifying news articles by topic, or classifying book reviews based on a positive or negative response. Text classification is also helpful for language detection, organizing customer feedback, and fraud detection. Though time consuming when done manually, this process can be automated with machine learning models. The result saves companies time while also providing valuable data insights.
11. 10 Biggest Image Datasets for Computer Vision
 Data is very important in building computer vision models and these are the 10 Biggest Datasets for Computer Vision.
Data is very important in building computer vision models and these are the 10 Biggest Datasets for Computer Vision.
12. 11 Best Climate Change Datasets for Data Science Projects
 Data is a central piece of the climate change debate. With the climate change datasets on this list, many data scientists have created visualizations and models to measure and track the change in surface temperatures, sea ice levels, and more. Many of these datasets have been made public to allow people to contribute and add valuable insight into the way the climate is changing and its causes.
Data is a central piece of the climate change debate. With the climate change datasets on this list, many data scientists have created visualizations and models to measure and track the change in surface temperatures, sea ice levels, and more. Many of these datasets have been made public to allow people to contribute and add valuable insight into the way the climate is changing and its causes.
13. Top 10 Open Datasets for Linear Regression
 On Hacker Noon, I will be sharing some of my best-performing machine learning articles. This listicle on datasets built for regression or linear regression tasks has been upvoted many times on Reddit and reshared dozens of times on various social media platforms. I hope Hacker Noon data scientists find it useful as well!
On Hacker Noon, I will be sharing some of my best-performing machine learning articles. This listicle on datasets built for regression or linear regression tasks has been upvoted many times on Reddit and reshared dozens of times on various social media platforms. I hope Hacker Noon data scientists find it useful as well!
14. 12 Best Pre-Installed R Datasets Commonly Used for Statistical Analysis
 R programming is mostly used in statistical analysis and ML.
This article looks at the Best Pre-Installed R Datasets Commonly Used for Statistical Analysis.
R programming is mostly used in statistical analysis and ML.
This article looks at the Best Pre-Installed R Datasets Commonly Used for Statistical Analysis.
15. 10 Best Stock Market Datasets for Machine Learning
 For those looking to build predictive models, this article will introduce 10 stock market and cryptocurrency datasets for machine learning.
For those looking to build predictive models, this article will introduce 10 stock market and cryptocurrency datasets for machine learning.
16. How To Scrap Product Information With Python & BeautifulSoup Module From Amazon Listings [Tutorial]
 Intro
Intro
17. 6 Work from Home Positions in AI Data Collection and Data Annotation
 For digital nomads, college students, stay-at-home parents or anyone looking for remote work positions, this article introduces online/remote work positions that are available today in the fields of AI Data Collection and Data Annotation.
For digital nomads, college students, stay-at-home parents or anyone looking for remote work positions, this article introduces online/remote work positions that are available today in the fields of AI Data Collection and Data Annotation.
18. How To Master Elasticsearch Query DSL
 Photo by Evgeni Tcherkasski on Unsplash
Photo by Evgeni Tcherkasski on Unsplash
19. 11 Torchvision Datasets for Computer Vision You Need to Know
 With torchvision datasets, developers can train and test their machine learning models on a range of tasks, such as image classification and object detection.
With torchvision datasets, developers can train and test their machine learning models on a range of tasks, such as image classification and object detection.
20. 10 Best Hugging Face Datasets for Building NLP Models
 Hugging Face offers solutions and tools for developers and researchers. This article looks at the Best Hugging Face Datasets for Building NLP Models.
Hugging Face offers solutions and tools for developers and researchers. This article looks at the Best Hugging Face Datasets for Building NLP Models.
21. An Intro to No-Code Web Scraping
 Web scraping has broken the barriers of programming and can now be done in a much simpler and easier manner without using a single line of code.
Web scraping has broken the barriers of programming and can now be done in a much simpler and easier manner without using a single line of code.
22. 10 Best Image Classification Datasets for ML Projects
 To help you build object recognition models, scene recognition models, and more, we’ve compiled a list of the best image classification datasets. These datasets vary in scope and magnitude and can suit a variety of use cases. Furthermore, the datasets have been divided into the following categories: medical imaging, agriculture & scene recognition, and others.
To help you build object recognition models, scene recognition models, and more, we’ve compiled a list of the best image classification datasets. These datasets vary in scope and magnitude and can suit a variety of use cases. Furthermore, the datasets have been divided into the following categories: medical imaging, agriculture & scene recognition, and others.
23. "We Are Very Early in Our Work With LLMs," - Prem Ramaswami, Head of Data Commons at Google
 Google's Head of Data Commons joined HackerNoon to discuss grounding AI in verifiable data, and why "we are very early with LLMs," MCP's open approach.
Google's Head of Data Commons joined HackerNoon to discuss grounding AI in verifiable data, and why "we are very early with LLMs," MCP's open approach.
24. How to Draw an Attractive Convenient Table — Design Techniques and Examples
 In this article, I want to show different table design techniques and examples of their application.
In this article, I want to show different table design techniques and examples of their application.
25. 17 Open Crime Datasets for Data Science and Machine Learning Projects
 For those looking to analyze crime rates or trends over a specific area or time period, we have compiled a list of the 16 best crime datasets made available for public use.
For those looking to analyze crime rates or trends over a specific area or time period, we have compiled a list of the 16 best crime datasets made available for public use.
26. Top 20 Twitter Datasets for Machine Learning Projects
 It is often very difficult for AI researchers to gather social media data for machine learning. Luckily, one free and accessible source of SNS data is Twitter.
It is often very difficult for AI researchers to gather social media data for machine learning. Luckily, one free and accessible source of SNS data is Twitter.
27. 8 Best Human Behaviour Datasets for Machine Learning
 Human behaviour describes how people interact and in this article, we will look at the 8 Best Human Behaviour Datasets for Machine Learning.
Human behaviour describes how people interact and in this article, we will look at the 8 Best Human Behaviour Datasets for Machine Learning.
28. 7 Steps To Prepare A Dataset For An Image-Based AI Project
 A guide for AI entrepreneurs on how to prepare a dataset for a machine learning project.
A guide for AI entrepreneurs on how to prepare a dataset for a machine learning project.
29. 10 Best Datasets for Geospatial Analytics (Open and Public Access)
 Scientists use geospatial analytics to build visualizations such as maps, graphs and cartograms. These are the Best Public Datasets for Geospatial Analytics.
Scientists use geospatial analytics to build visualizations such as maps, graphs and cartograms. These are the Best Public Datasets for Geospatial Analytics.
30. Top 3 Face Datasets and How to Work with Them
 An image dataset contains specially selected digital images intended to help train, test, and evaluate an artificial intelligence (AI) or machine learning (ML)
An image dataset contains specially selected digital images intended to help train, test, and evaluate an artificial intelligence (AI) or machine learning (ML)
31. 10 Best Keras Datasets for Building and Training Deep Learning Models
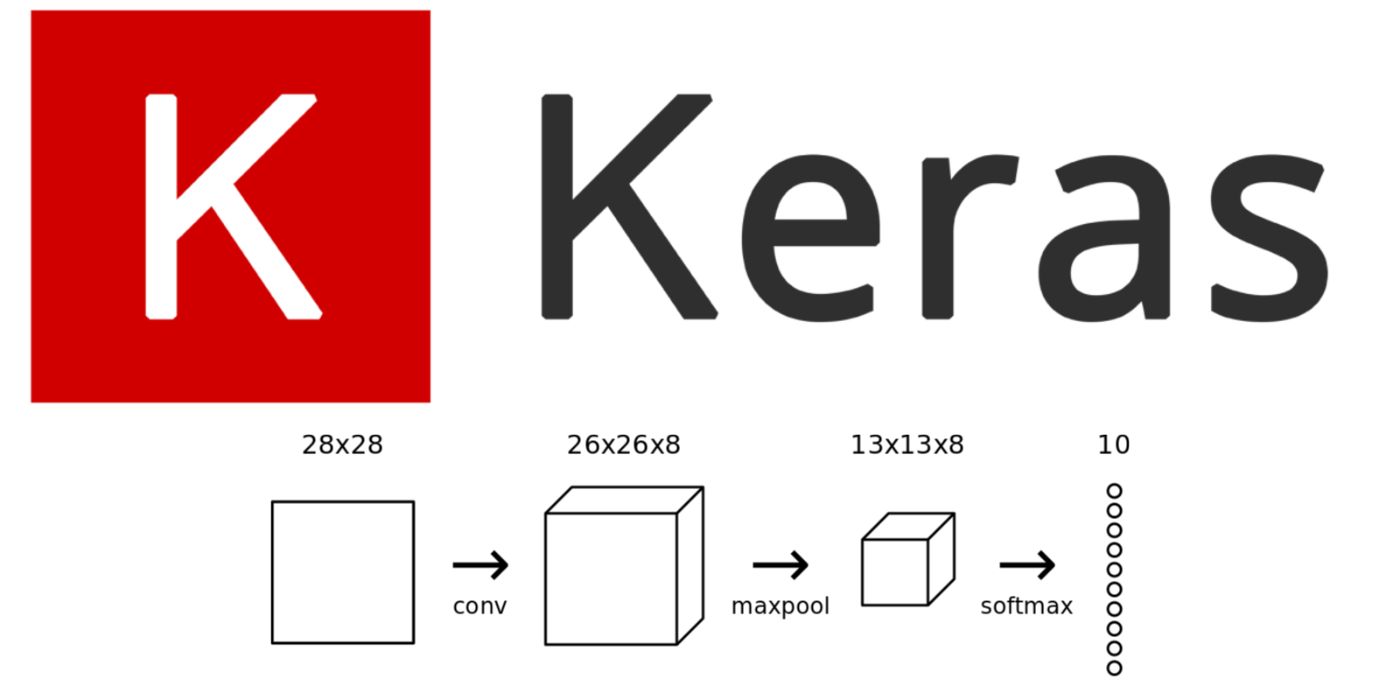 This article looks at the Best Keras Datasets for Building and Training Deep Learning Models, accessible to developers and researchers worldwide.
This article looks at the Best Keras Datasets for Building and Training Deep Learning Models, accessible to developers and researchers worldwide.
32. 20 Best PyTorch Datasets for Building Deep Learning Models
 PyTorch has gained a reputation as a research-focused framework, and these are the Best PyTorch Datasets for Building Deep Learning Models available today.
PyTorch has gained a reputation as a research-focused framework, and these are the Best PyTorch Datasets for Building Deep Learning Models available today.
33. Machine Learning Food Datasets Collection
 An essential part of my company's Machine Learning team is working with different food datasets, and we spend a lot of time before for searching, combining or intersecting different datasets to get data that we need and can use in our work. Given that it might help someone else, I decided to list all helpful datasets in one place.
An essential part of my company's Machine Learning team is working with different food datasets, and we spend a lot of time before for searching, combining or intersecting different datasets to get data that we need and can use in our work. Given that it might help someone else, I decided to list all helpful datasets in one place.
34. Data Set and Data Augmentation for Face Detection and Recognition
 When it comes to building an Artificially Intelligent (AI) application, your approach must be data first, not application first.
When it comes to building an Artificially Intelligent (AI) application, your approach must be data first, not application first.
35. Build Data-Driven Web App Without Backend

36. How Data Analysis Helps Unveil the Truth of Coronavirus
 These days we are all scared of the new airborne contagious coronavirus (2019-nCoV). Even if it is a tiny cough or low fever, it might underlie a lethargic symptom. However, what is the real truth?
These days we are all scared of the new airborne contagious coronavirus (2019-nCoV). Even if it is a tiny cough or low fever, it might underlie a lethargic symptom. However, what is the real truth?
37. 10 Best Reddit Datasets for NLP and Other ML Projects
 In this post, I wanted to share a Reddit dataset list that gained a lot of traction on social media when it was first posted.
In this post, I wanted to share a Reddit dataset list that gained a lot of traction on social media when it was first posted.
38. Alternatives to Web Scraping with Python
 Is Python really the easiest and most efficient way to scrape a website? There are other options out there. Find out which one is best for you!
Is Python really the easiest and most efficient way to scrape a website? There are other options out there. Find out which one is best for you!
39. InfluxDB Continuous Downsampling - Optimize Your TSDB Today
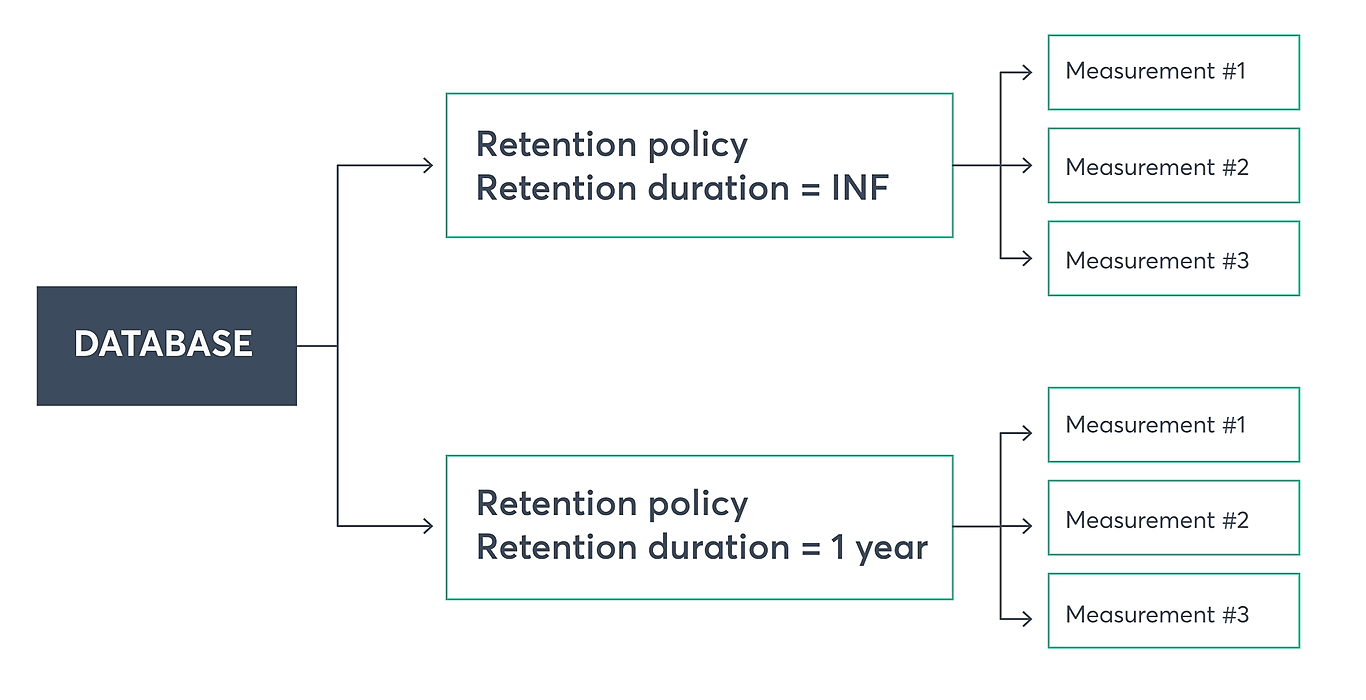 Introduction
Introduction
40. 5 Million Face Images for Facial Recognition Model Training
 This article on face recognition datasets is one of my best-performing articles I wrote originally on Lionbridge AI. I'm happy to share it with the Hacker Noon community!
This article on face recognition datasets is one of my best-performing articles I wrote originally on Lionbridge AI. I'm happy to share it with the Hacker Noon community!
41. Top 10 Best Web Scraper And Data Scraping Tools
 Data extraction has many forms and can be complicated. From Preventing your IP from getting banned to bypassing the captchas, to parsing the source correctly, headerless chrome for javascript rendering, data cleaning, and then generating the data in a usable format, there is a lot of effort that goes in. I have been scraping data from the web for over 8 years. We used web scraping for tracking the prices of other hotel booking vendors. So, when our competitor lowers his prices we get a notification to lower our prices to from our cron web scrapers.
Data extraction has many forms and can be complicated. From Preventing your IP from getting banned to bypassing the captchas, to parsing the source correctly, headerless chrome for javascript rendering, data cleaning, and then generating the data in a usable format, there is a lot of effort that goes in. I have been scraping data from the web for over 8 years. We used web scraping for tracking the prices of other hotel booking vendors. So, when our competitor lowers his prices we get a notification to lower our prices to from our cron web scrapers.
42. Azure Data Factory - Datasets and Linked Services
 ADF Concepts & relation among the ADF components
ADF Concepts & relation among the ADF components
43. Introducing theHolopix50k Dataset for Image Super-Resolution

44. Automating the Automation: Can AI Fully Take Over the Data Scraping Process?
 Can modern AI systems fully automate web data collection and analysis? Let’s delve deeper into ML and web scraping to see if this is more than just a new hype.
Can modern AI systems fully automate web data collection and analysis? Let’s delve deeper into ML and web scraping to see if this is more than just a new hype.
45. How To Monitor a Forum for Keywords Using Python and AWS Lambda
 While building ScrapingBee I'm always checking different forums everyday to help people about web scraping related questions and engage with the community.
While building ScrapingBee I'm always checking different forums everyday to help people about web scraping related questions and engage with the community.
46. How Vectors, RAG and Llama 3 Are Changing First-Party Data
 In the battle for the best data, is first-party better? Not by itself, but it could be with vectors, frameworks like RAG, and open-source models
In the battle for the best data, is first-party better? Not by itself, but it could be with vectors, frameworks like RAG, and open-source models
47. 10 Best African Language Datasets for Data Science Projects
 A list of African language datasets from across the web that can be used in numerous NLP tasks.
A list of African language datasets from across the web that can be used in numerous NLP tasks.
48. Multi-EuP: Analysis of Bias in Information Retrieval - Abstract and Intro
 Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
49. Going From Data Lakes to Oceans
 Aggregating into data lakes is the solution of today — but are Federated Sources the solution of tomorrow?
Aggregating into data lakes is the solution of today — but are Federated Sources the solution of tomorrow?
50. A Deep Dive Into Facebook’s AI Transcoder
 Just over a week, most of you would have heard that Facebooks AI research team (FAIR) developed a neural transcompiler, that converts code from high level programming language like C++, Python, Java, Cobol into another language using ‘unsupervised translation’ . The traditional approach had been to tokenize the source language and convert it into an Abstract Syntax Tree (AST) which the transcompiler would use to translate to the target language of choice, based on handwritten rules that define the translations, such that abstract or the context is not lost.
Just over a week, most of you would have heard that Facebooks AI research team (FAIR) developed a neural transcompiler, that converts code from high level programming language like C++, Python, Java, Cobol into another language using ‘unsupervised translation’ . The traditional approach had been to tokenize the source language and convert it into an Abstract Syntax Tree (AST) which the transcompiler would use to translate to the target language of choice, based on handwritten rules that define the translations, such that abstract or the context is not lost.
51. Evolution of The Data Production Paradigm in AI
 The long-term success of an AI-based product relies on having the infrastructure for scalable, flexible, and cost-effective data labeling for its learning.
The long-term success of an AI-based product relies on having the infrastructure for scalable, flexible, and cost-effective data labeling for its learning.
52. Unveiling Causal Impact: From Theory to Practice
 We will guide you through a specific dataset, demonstrating how to implement the library and interpret results.
We will guide you through a specific dataset, demonstrating how to implement the library and interpret results.
53. What is Data Analytics and How It Can Be Used

54. Top 15 Datasets for Autonomous Driving
 A2D2, ApolloScape, and Berkeley DeepDrive are among the best autonomous driving datasets available today.
A2D2, ApolloScape, and Berkeley DeepDrive are among the best autonomous driving datasets available today.
55. Merging Datasets from Different Timescales
 One of the trickiest situations in machine learning is when you have to deal with datasets coming from different time scales.
One of the trickiest situations in machine learning is when you have to deal with datasets coming from different time scales.
56. What is Web Data Collection?
 Everything you need to know to automate, optimize and streamline the data collection process in your organization!
Everything you need to know to automate, optimize and streamline the data collection process in your organization!
57. Data and Its Color
 I had the opportunity to speak with Bourgeois about her project, what she learned, and how others can use creative approaches to ask questions
I had the opportunity to speak with Bourgeois about her project, what she learned, and how others can use creative approaches to ask questions
58. The Rise of Reusable SQL-based Data Modeling Tools and DataOps services
 The resurgence of SQL-based RDBMS
The resurgence of SQL-based RDBMS
59. Build A Commission-Free Algo Trading Bot By Machine Learning Quarterly Earnings Reports [Full Guide]
 Introduction
Introduction
60. The Art of Data Storytelling: How to Make Your Data Impactful

61. Encoding Categorical Data for ML Algorithms
 Encoding is a technique used to convert categorical data to numerical representations to be able to use the data in machine learning algorithms.
Encoding is a technique used to convert categorical data to numerical representations to be able to use the data in machine learning algorithms.
62. How Big Data and Artificial Intelligence Will Go Hand in Hand?
 The emergence of technology is playing an inevitable role in business. It’s drastically transforming the way people work together in an organization. Both these technologies are revolutionizing every aspect of our life. These technologies are creating a culture where the collaboration of IT leaders and businesses results in realizing values from all generated data.
The emergence of technology is playing an inevitable role in business. It’s drastically transforming the way people work together in an organization. Both these technologies are revolutionizing every aspect of our life. These technologies are creating a culture where the collaboration of IT leaders and businesses results in realizing values from all generated data.
63. Data-driven Autonomous Driving: AI Needs Diverse Training Datasets to Ensure Security and Robustness
 AI training data solutions will drive the evolution of autonomous driving by providing diverse, high-quality datasets necessary for handling real-world scenerio
AI training data solutions will drive the evolution of autonomous driving by providing diverse, high-quality datasets necessary for handling real-world scenerio
64. Getting Started with Data Visualization: Building a JavaScript Scatter Plot Module
 Scatter plots are a great way to visualize data. Data is represented as points on a Cartesian plane where the x and y coordinate of each point represents a variable. These charts let you investigate the relationship between two variables, detect outliers in the data set as well as detect trends. They are one of the most commonly used data visualization techniques and are a must have for your data visualization arsenal!
Scatter plots are a great way to visualize data. Data is represented as points on a Cartesian plane where the x and y coordinate of each point represents a variable. These charts let you investigate the relationship between two variables, detect outliers in the data set as well as detect trends. They are one of the most commonly used data visualization techniques and are a must have for your data visualization arsenal!
65. Database APIs vs Datasets: Weighing Benefits, Drawbacks, and Transition Strategies
 Database API is a convenient way to get relevant data records whenever needed. Learn about the benefits, limitations, and common use cases.
Database API is a convenient way to get relevant data records whenever needed. Learn about the benefits, limitations, and common use cases.
66. 75 Stories To Learn About Datasets
 Learn everything you need to know about Datasets via these 75 free HackerNoon stories.
Learn everything you need to know about Datasets via these 75 free HackerNoon stories.
67. Antonio Reza's Top 10 Secrets to Mastering Sheets Like a Pro
 I've created hundreds of financial models in Google Sheets using SQL and AI to help the company sell billions of dollars.
I've created hundreds of financial models in Google Sheets using SQL and AI to help the company sell billions of dollars.
68. Artificial Intelligence is No Match for Natural Stupidity
 A Lazy Introduction to AI for Infosec.
A Lazy Introduction to AI for Infosec.
69. Six Ways For Effective Data Visualization With Tableau
 Tableau
Tableau
70. Gender Prediction Using Mobile App Data
 Сreate a model for the gender prediction based on the list of installed applications on a mobile device.
Сreate a model for the gender prediction based on the list of installed applications on a mobile device.
71. The Hunt for Data: Creating a Computer Vision Dataset for Road Safety
 In this article, I would like to share my own experience of developing a smart camera for cyclists with an advanced computer vision algorithm
In this article, I would like to share my own experience of developing a smart camera for cyclists with an advanced computer vision algorithm
72. Sort Through Online Data via Web Scraping [101]
 How Can You Sort Through Online Data?
How Can You Sort Through Online Data?
73. Multi-EuP: Analysis of Bias in Information Retrieval - Conclusion, Limitations, and Ethics Statement
 Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
74. Here's Why We Built An Open-Source Goldmine of Crypto-Markets Datasets
 How to run a distributed data-mining operation to source and process crypto market data at zero cost.
How to run a distributed data-mining operation to source and process crypto market data at zero cost.
75. MODEL-CENTRIC vs DATA-CENTRIC Approaches in Machine Learning
 Machine learning is an area of artificial intelligence (AI) and computer science that focuses on using data and algorithms to mimic the way humans learn
Machine learning is an area of artificial intelligence (AI) and computer science that focuses on using data and algorithms to mimic the way humans learn
76. Face Data Augmentation - Part 1: Geometric Transformation
 In this article, I will show how your dataset of human faces can be enriched by 3D geometry transformation to improve the performance of your model.
In this article, I will show how your dataset of human faces can be enriched by 3D geometry transformation to improve the performance of your model.
77. Collecting Data from 1.1M Hacker News Curated Comments
 In this test we use the data collection of 1.1M Hacker News curated comments with numeric fields from https://zenodo.org/record/45901.
In this test we use the data collection of 1.1M Hacker News curated comments with numeric fields from https://zenodo.org/record/45901.
78. Kannada-MNIST:A new handwritten digits dataset in ML town
 TLDR:
TLDR:
79. The Pain Points of Scaling Data Science
 While building a machine learning model, data scaling in machine learning is the most significant element through data pre-processing. Scaling may recognize the difference between a model of poor machine learning and a stronger one.
While building a machine learning model, data scaling in machine learning is the most significant element through data pre-processing. Scaling may recognize the difference between a model of poor machine learning and a stronger one.
80. Universal Data Tool Introduction: Weekly Update 1
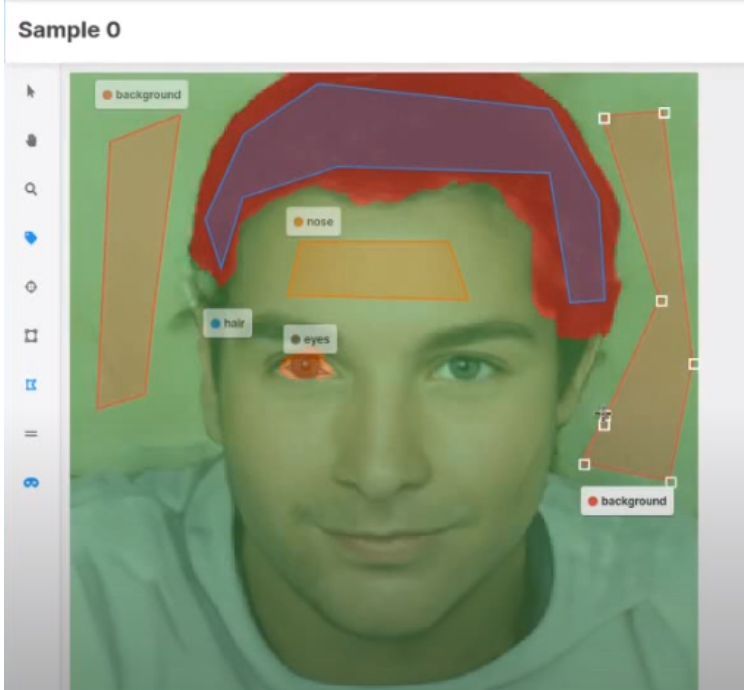 If you haven’t heard of the Universal Data Tool, it’s an open-source web or desktop program to collaborate, build and edit text, image, video and audio datasets with labels and annotations. You can get started with the Universal Data Tool at universaldatatool.com
If you haven’t heard of the Universal Data Tool, it’s an open-source web or desktop program to collaborate, build and edit text, image, video and audio datasets with labels and annotations. You can get started with the Universal Data Tool at universaldatatool.com
81. Python vs. Spark: When Does It Make Sense to Scale Up?
 Wondering when to switch from Python to Spark? This practical guide breaks down the real differences, warning signs, and best use cases—so you know exactly when
Wondering when to switch from Python to Spark? This practical guide breaks down the real differences, warning signs, and best use cases—so you know exactly when
82. Las 15 preguntas más frecuentes sobre Web Scraping
 Previously published at https://www.octoparse.es/blog/15-preguntas-frecuentes-sobre-web-scraping
Previously published at https://www.octoparse.es/blog/15-preguntas-frecuentes-sobre-web-scraping
83. Improve Early Failure Detection (EFD) in Web Scraping With Benchmark Data
 We need to increase the Failure Detection Rate (FDR) and reduce the False Alarm Rate (FAR). With a cherry on top: keeping costs low.
We need to increase the Failure Detection Rate (FDR) and reduce the False Alarm Rate (FAR). With a cherry on top: keeping costs low.
84. What Is Big Data? Understanding The Business Use of Big Data Analytics
 Big data analytics can be applied for all and any business to boost their revenue and conversions and identify their common mistakes.
Big data analytics can be applied for all and any business to boost their revenue and conversions and identify their common mistakes.
85. Why Datasets are Crucial to Data Science: the Key to Informed Decisions
 Datasets are crucial for anyone wanting to learn data science.
Datasets are crucial for anyone wanting to learn data science.
86. The Ouroboros Effect of Data Aggregation and Scraping
 Learn how web scraping and data aggregation might feed of each other, unintentionally creating an effect of decision-making convergence.
Learn how web scraping and data aggregation might feed of each other, unintentionally creating an effect of decision-making convergence.
87. Web Scraping API para Extracción de Datos: Una Guía para Principiantes
 ¿Alguna vez te sucede cuando la gente te pide que escribas una API separada para integrar datos de redes sociales y guardar los datos sin procesar en tu base de datos de análisis en el sitio? Definitivamente quieres saber qué es la API, cómo se usa en web scraping y qué puede lograr con ella. Echemos un vistazo.
¿Alguna vez te sucede cuando la gente te pide que escribas una API separada para integrar datos de redes sociales y guardar los datos sin procesar en tu base de datos de análisis en el sitio? Definitivamente quieres saber qué es la API, cómo se usa en web scraping y qué puede lograr con ella. Echemos un vistazo.
88. Multi-EuP: Analysis of Bias in Information Retrieval - Multi-EuP Use
 Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
89. Limitations, Ethical Considerations, and More: Everything You Need to Know About WikiWebQuestions
 We have created a new high-quality benchmark, WikiWebQuestions, for large knowledge-base question answering.
We have created a new high-quality benchmark, WikiWebQuestions, for large knowledge-base question answering.
90. Introducing a Simple Module for Parsing CSV Files
 This Slogging thread by and Arthur Tkachenko occurred in slogging's official #programming channel, and has been edited for readability.
This Slogging thread by and Arthur Tkachenko occurred in slogging's official #programming channel, and has been edited for readability.
91. Things to Consider When Looking For Data Science Roles
 There is a great demand for data scientists presenting market dynamics that are favourable for the community. More so than your peers in other professions, you will be able to evaluate a company for what it is able to offer you, rather than solely being the one that is being evaluated. So what should you look for when comparing and evaluating data science roles? Here is a list of some commonly known factors plus some less discussed ones that will help you in your evaluation.
There is a great demand for data scientists presenting market dynamics that are favourable for the community. More so than your peers in other professions, you will be able to evaluate a company for what it is able to offer you, rather than solely being the one that is being evaluated. So what should you look for when comparing and evaluating data science roles? Here is a list of some commonly known factors plus some less discussed ones that will help you in your evaluation.
92. Multi-EuP: Analysis of Bias in Information Retrieval - Background and Related Work
 Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
93. How This Open Litter Database Will Save the Planet
 The Litterati app has been around for a couple years on iOS + Android. Over that time, well over 100k people have downloaded the app and been a part of a global team that is 'crowdsource cleaning the Earth'.
The Litterati app has been around for a couple years on iOS + Android. Over that time, well over 100k people have downloaded the app and been a part of a global team that is 'crowdsource cleaning the Earth'.
Over that time, people only had access to the data that they themselves generated.
94. How to Aid Disease Research with a Biomedical Knowledge Graph
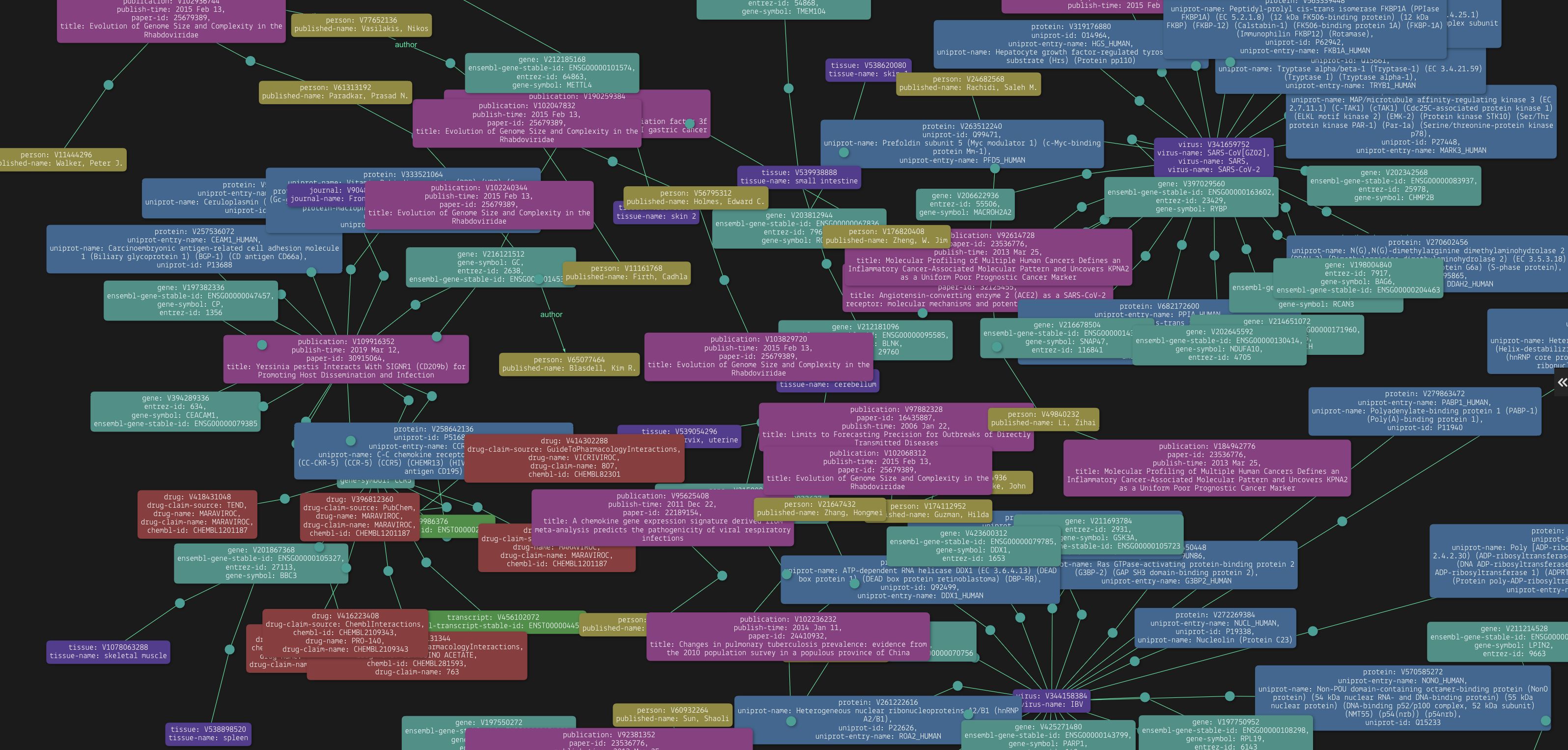 Building a biomedical knowledge graph using publicly available datasets to better aid disease research and biomedical data modelling.
Building a biomedical knowledge graph using publicly available datasets to better aid disease research and biomedical data modelling.
95. What AV Programs That Ship Get Right About Data Annotation
 The gap between 50,000 frames and 100 million is where most AV programs quietly fall apart. What production-grade annotation operations get right from day one.
The gap between 50,000 frames and 100 million is where most AV programs quietly fall apart. What production-grade annotation operations get right from day one.
96. Towards an ImageNet Moment for Speech-to-Text: A Deep Dive
 Speech-to-text (STT), also known as automated-speech-recognition (ASR), has a long history and has made amazing progress over the past decade. Currently, it is often believed that only large corporations like Google, Facebook, or Baidu (or local state-backed monopolies for the Russian language) can provide deployable “in-the-wild” solutions.
Speech-to-text (STT), also known as automated-speech-recognition (ASR), has a long history and has made amazing progress over the past decade. Currently, it is often believed that only large corporations like Google, Facebook, or Baidu (or local state-backed monopolies for the Russian language) can provide deployable “in-the-wild” solutions.
97. Spending Weekend with GraphQL

98. Multi-EuP: Analysis of Bias in Information Retrieval - Language Bias Discussion
 Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
99. WikiWebQuestions (WWQ) Dataset: What Is It?
 We migrated WebQuestionsSP, the best collection of natural language questions over a general knowledge graph, from Freebase to Wikidata.
We migrated WebQuestionsSP, the best collection of natural language questions over a general knowledge graph, from Freebase to Wikidata.
100. Is Data Catalog an Indispensable Tool for Corporate?
 To understand the concept of data catalog, we need an assessment of the fundamentals that constitute the process on an elementary level. At the most rudimentary stage lies the idea of arrangement and the order of things.
To understand the concept of data catalog, we need an assessment of the fundamentals that constitute the process on an elementary level. At the most rudimentary stage lies the idea of arrangement and the order of things.
101. Multi-EuP: Analysis of Bias in Information Retrieval - Experiments and Findings
 Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
Explore language bias in multilingual information retrieval with the Multi-EuP dataset, revealing insights into fairness and demographic factors.
102. What Makes LightCap Tick? Breaking Down the Numbers and Components
 LightCap, trained on 5.8M image-text pairs, excels on COCO and nocaps using BLEU@4, METEOR, CIDEr, SPICE; ablations show each module’s performance boost.
LightCap, trained on 5.8M image-text pairs, excels on COCO and nocaps using BLEU@4, METEOR, CIDEr, SPICE; ablations show each module’s performance boost.
Thank you for checking out the 102 most read blog posts about Datasets on HackerNoon.
Visit the /Learn Repo to find the most read blog posts about any technology.